Curriculum-style Data Augmentation for LLM-based Metaphor Detection
作者: Kaidi Jia, Yanxia Wu, Ming Liu, Rongsheng Li
分类: cs.CL
发布日期: 2024-12-04 (更新: 2025-03-02)
💡 一句话要点
提出课程学习风格数据增强方法,用于微调LLM以提升隐喻检测性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 隐喻检测 大型语言模型 数据增强 课程学习 微调 自然语言处理 开源LLM
📋 核心要点
- 现有隐喻检测方法依赖闭源LLM,存在推理成本高、延迟大的问题。
- 提出课程学习风格数据增强(CDA)方法,通过评估数据并有针对性地进行数据增强,提升模型性能。
- 实验结果表明,该方法在隐喻检测任务上取得了state-of-the-art的性能,并验证了CDA的有效性。
📝 摘要(中文)
本文提出了一种基于大型语言模型(LLM)的隐喻检测方法,旨在解决现有方法过度依赖闭源LLM导致的高推理成本和延迟问题。通过微调开源LLM,该方法能够以单步推理有效降低成本和延迟。此外,针对隐喻检测中数据稀缺的问题,本文引入了课程学习风格的数据增强(CDA)方法。该方法首先评估训练数据,将正确预测的实例用于微调,而错误预测的实例作为种子数据进行数据增强。这种方法使模型能够快速学习简单知识,并逐步掌握更复杂的知识,从而逐步提高性能。实验结果表明,该方法在所有基线上均实现了最先进的性能。此外,还提供了详细的消融研究,以验证CDA的有效性。
🔬 方法详解
问题定义:论文旨在解决隐喻检测任务中,现有方法依赖闭源LLM导致的高推理成本和延迟问题,以及数据稀缺导致LLM难以有效微调的问题。现有方法的痛点在于无法兼顾性能和效率,且在数据量不足的情况下难以充分发挥LLM的潜力。
核心思路:论文的核心思路是利用开源LLM进行微调,降低推理成本和延迟。同时,采用课程学习风格的数据增强(CDA)方法,让模型先学习简单的知识,再逐步学习复杂的知识,从而提高模型在数据稀缺情况下的学习效率和泛化能力。
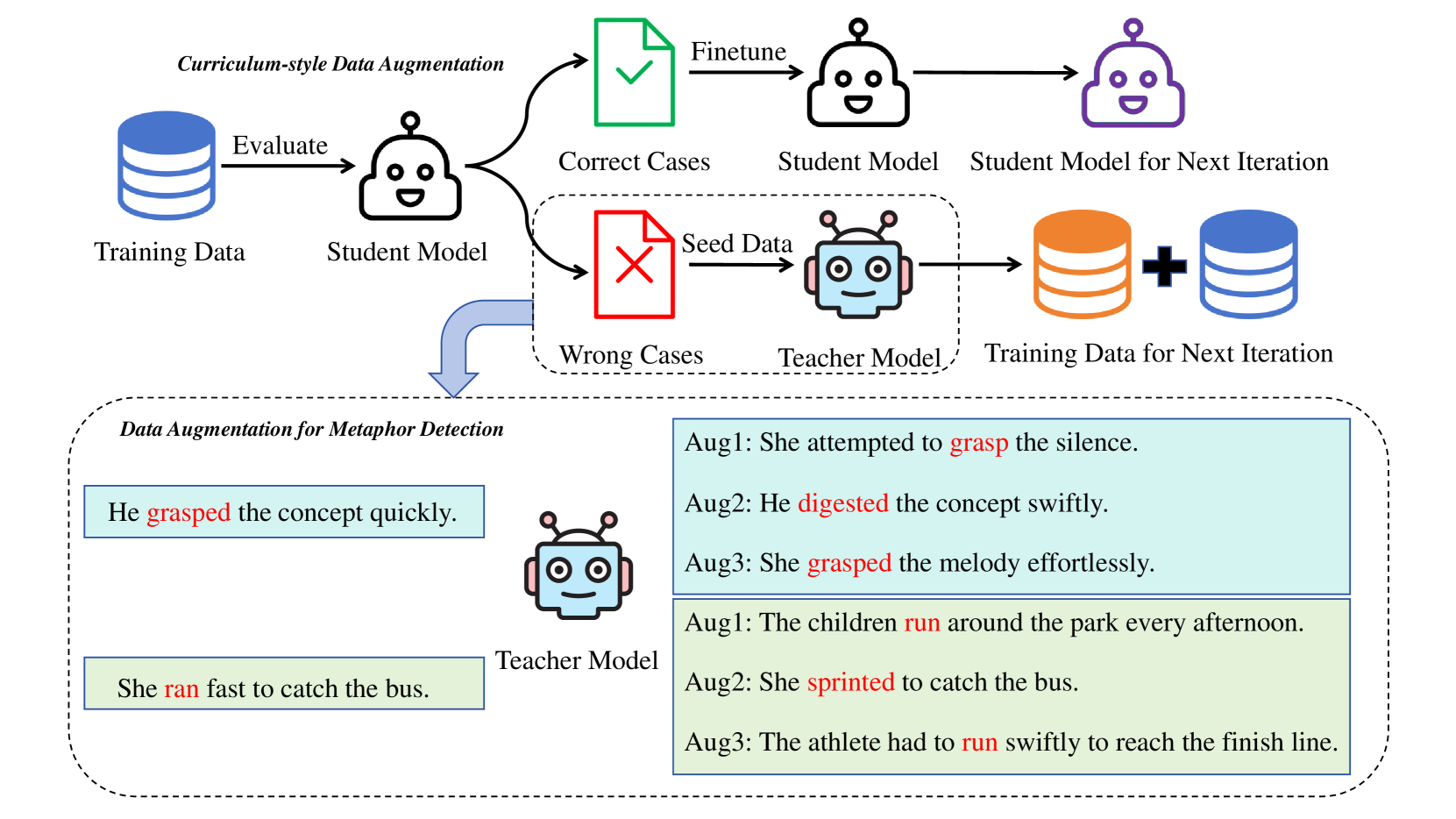
技术框架:整体框架包括两个主要阶段:1) 数据评估与增强阶段:首先使用预训练的LLM对训练数据进行预测,根据预测结果将数据分为正确预测的实例和错误预测的实例。然后,将错误预测的实例作为种子数据,使用数据增强技术生成新的训练数据。2) 微调阶段:使用原始训练数据和增强后的数据,对开源LLM进行微调。
关键创新:论文的关键创新在于提出了课程学习风格的数据增强(CDA)方法。与传统的数据增强方法不同,CDA方法不是随机地生成新的数据,而是根据模型对原始数据的预测结果,有针对性地生成新的数据。这种方法能够让模型更快地学习到有用的知识,从而提高模型的性能。
关键设计:CDA方法的关键设计在于如何评估训练数据和如何生成新的数据。论文使用预训练的LLM对训练数据进行预测,并将预测结果作为评估的标准。对于数据增强,论文可能采用了回译、同义词替换等常见的数据增强技术,但具体细节未知。损失函数方面,可能采用交叉熵损失函数,但具体细节未知。
🖼️ 关键图片
📊 实验亮点
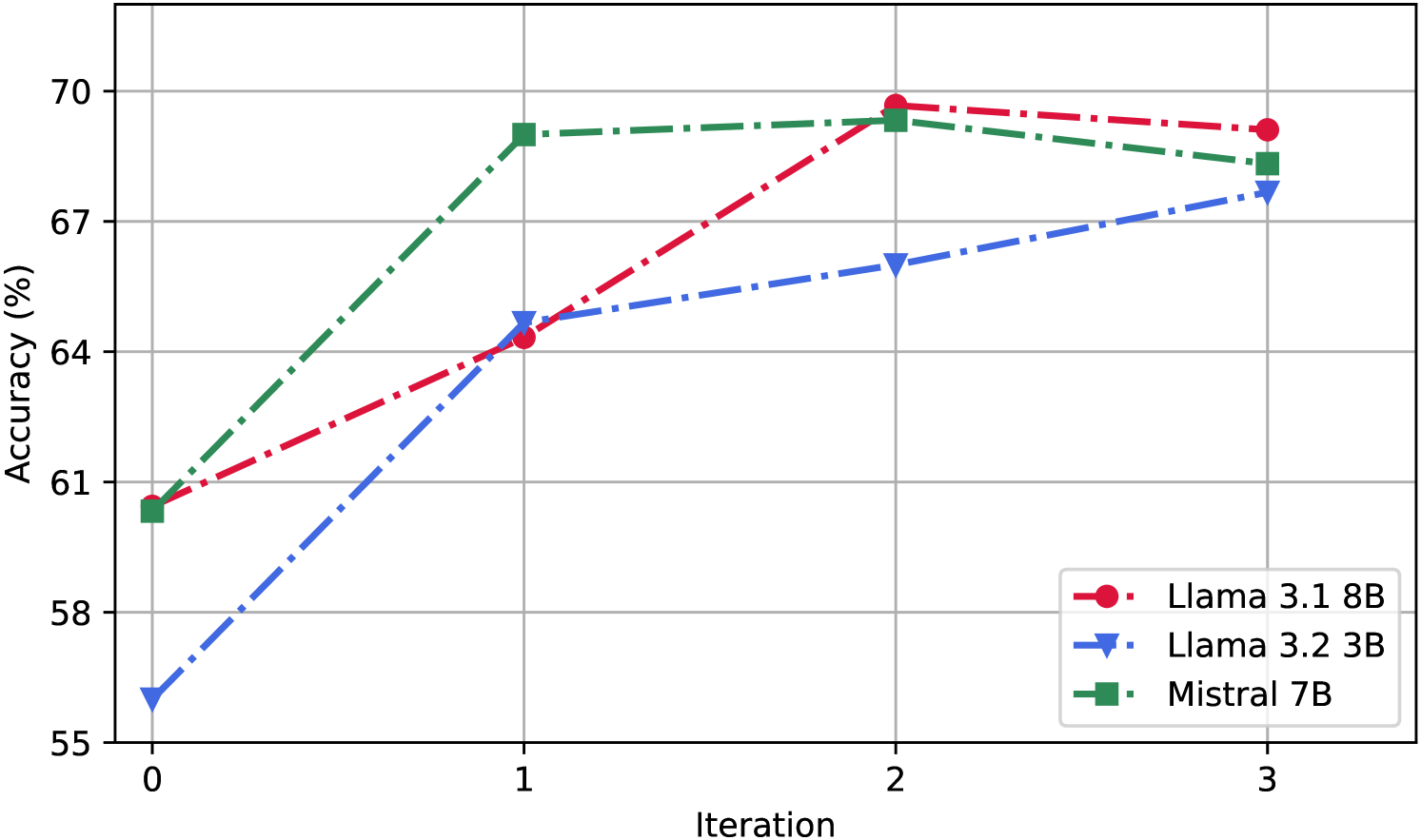
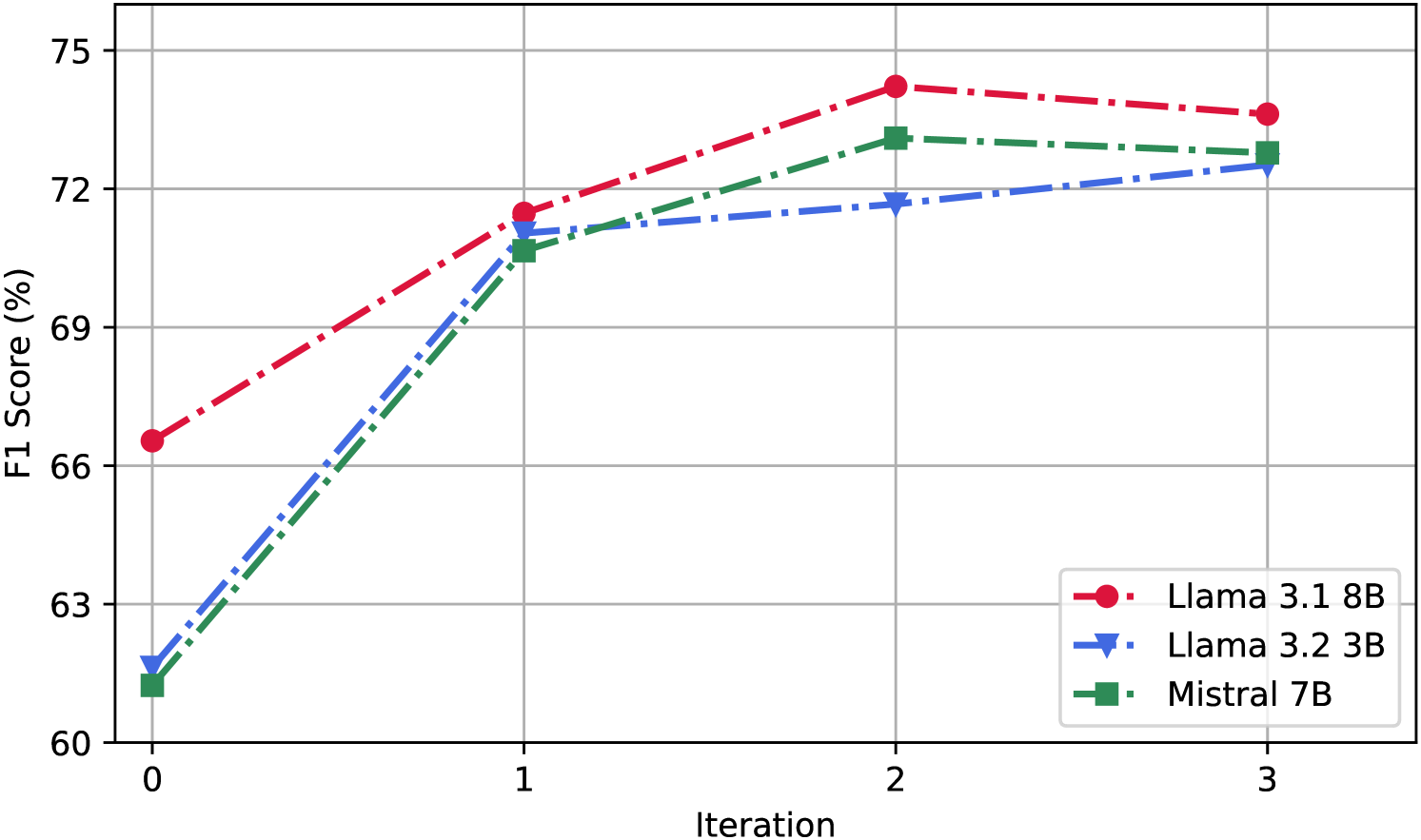
实验结果表明,该方法在隐喻检测任务上取得了state-of-the-art的性能。具体性能数据和对比基线未知,但论文强调该方法在所有基线上均取得了最佳结果,并提供了消融实验验证了CDA的有效性。提升幅度未知,但整体效果显著。
🎯 应用场景
该研究成果可应用于自然语言处理的多个领域,例如情感分析、文本理解和机器翻译。通过提高隐喻检测的准确性和效率,可以提升机器对人类语言的理解能力,从而改善人机交互体验,并为下游任务提供更可靠的基础。
📄 摘要(原文)
Recently, utilizing large language models (LLMs) for metaphor detection has achieved promising results. However, these methods heavily rely on the capabilities of closed-source LLMs, which come with relatively high inference costs and latency. To address this, we propose a method for metaphor detection by fine-tuning open-source LLMs, effectively reducing inference costs and latency with a single inference step. Furthermore, metaphor detection suffers from a severe data scarcity problem, which hinders effective fine-tuning of LLMs. To tackle this, we introduce Curriculum-style Data Augmentation (CDA). Specifically, before fine-tuning, we evaluate the training data to identify correctly predicted instances for fine-tuning, while incorrectly predicted instances are used as seed data for data augmentation. This approach enables the model to quickly learn simpler knowledge and progressively acquire more complex knowledge, thereby improving performance incrementally. Experimental results demonstrate that our method achieves state-of-the-art performance across all baselines. Additionally, we provide detailed ablation studies to validate the effectiveness of CDA.