Multi-Bin Batching for Increasing LLM Inference Throughput
作者: Ozgur Guldogan, Jackson Kunde, Kangwook Lee, Ramtin Pedarsani
分类: cs.CL, cs.DC, cs.LG, eess.SY
发布日期: 2024-12-03
💡 一句话要点
提出多桶批处理方法,提升大语言模型推理吞吐量
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 LLM推理 批量处理 吞吐量优化 资源利用率
📋 核心要点
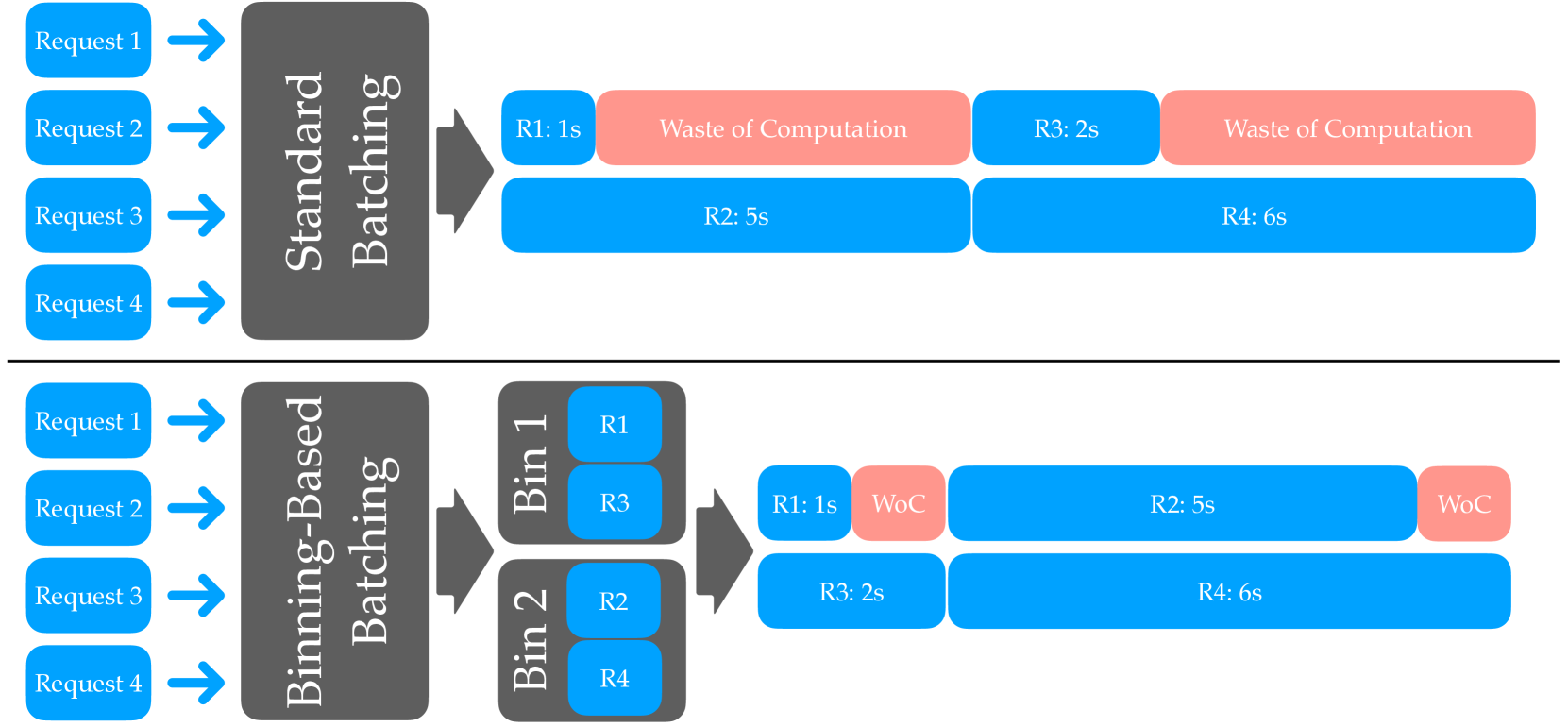
- 现有LLM推理系统在批量处理请求时,由于请求长度差异大,导致资源利用率低,影响整体吞吐量。
- 论文提出多桶批处理方法,将具有相似执行时间的请求分到同一桶中,从而优化资源分配,提升吞吐量。
- 通过理论分析和实际LLM推理实验,证明了该方法相比标准批处理方法,能够显著提高推理吞吐量。
📝 摘要(中文)
随着大语言模型(LLM)因其多样化的能力而日益普及,提高其推理系统的效率变得至关重要。批量处理LLM请求是在服务器(例如GPU)上调度推理作业的关键步骤,它通过允许多个请求并行处理来最大化系统吞吐量。然而,请求通常具有不同的生成长度,导致资源利用不足,因为硬件必须等待批处理中最长运行的请求完成才能移动到下一个批处理。我们从排队论的角度形式化了这个问题,并旨在设计一种吞吐量最优的控制策略。我们提出多桶批处理,这是一种简单而有效的方法,可以通过将具有相似(预测)执行时间的请求分组到预定的桶中来显著提高LLM推理吞吐量。通过理论分析和实验(包括真实世界的LLM推理场景),我们证明了与标准批处理方法相比,吞吐量有了显著提高。
🔬 方法详解
问题定义:论文旨在解决大语言模型(LLM)推理过程中,由于请求长度差异导致的资源利用率低下的问题。传统的批量处理方法将不同长度的请求放在同一批次中,导致GPU等硬件资源必须等待最长的请求完成才能开始处理下一批次,造成资源浪费,降低了整体的推理吞吐量。
核心思路:论文的核心思路是将具有相似(预测)执行时间的请求分组到不同的“桶”中,每个桶内的请求长度相近,从而减少批处理内部的等待时间,提高GPU的利用率。通过优化桶的划分和请求的分配策略,可以实现更高的推理吞吐量。
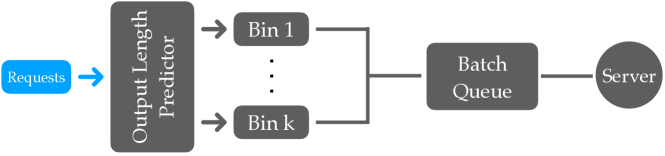
技术框架:该方法主要包含以下几个阶段:1. 请求预测:预测每个请求的执行时间。可以使用简单的模型或者启发式方法进行预测。2. 桶划分:将请求按照预测的执行时间划分到不同的桶中。桶的数量和大小可以根据实际情况进行调整。3. 批处理:在每个桶内进行批处理,将桶内的请求打包成一个批次进行推理。4. 调度:根据一定的策略调度不同桶的批次进行推理。
关键创新:该方法的核心创新在于提出了“多桶”的概念,将请求按照执行时间进行分类,从而避免了传统批量处理方法中长短请求混合导致的资源浪费。这种方法简单有效,易于实现,并且具有较强的通用性,可以应用于不同的LLM推理场景。
关键设计:关键设计包括:1. 桶的数量和大小:需要根据实际的请求分布进行调整,以达到最佳的资源利用率。2. 请求预测模型:预测的准确性会直接影响桶的划分效果,因此需要选择合适的预测模型。3. 调度策略:需要根据桶的优先级和资源情况进行调度,以最大化吞吐量。论文中可能使用了排队论相关的模型来分析和优化调度策略,但具体细节未知。
🖼️ 关键图片
📊 实验亮点
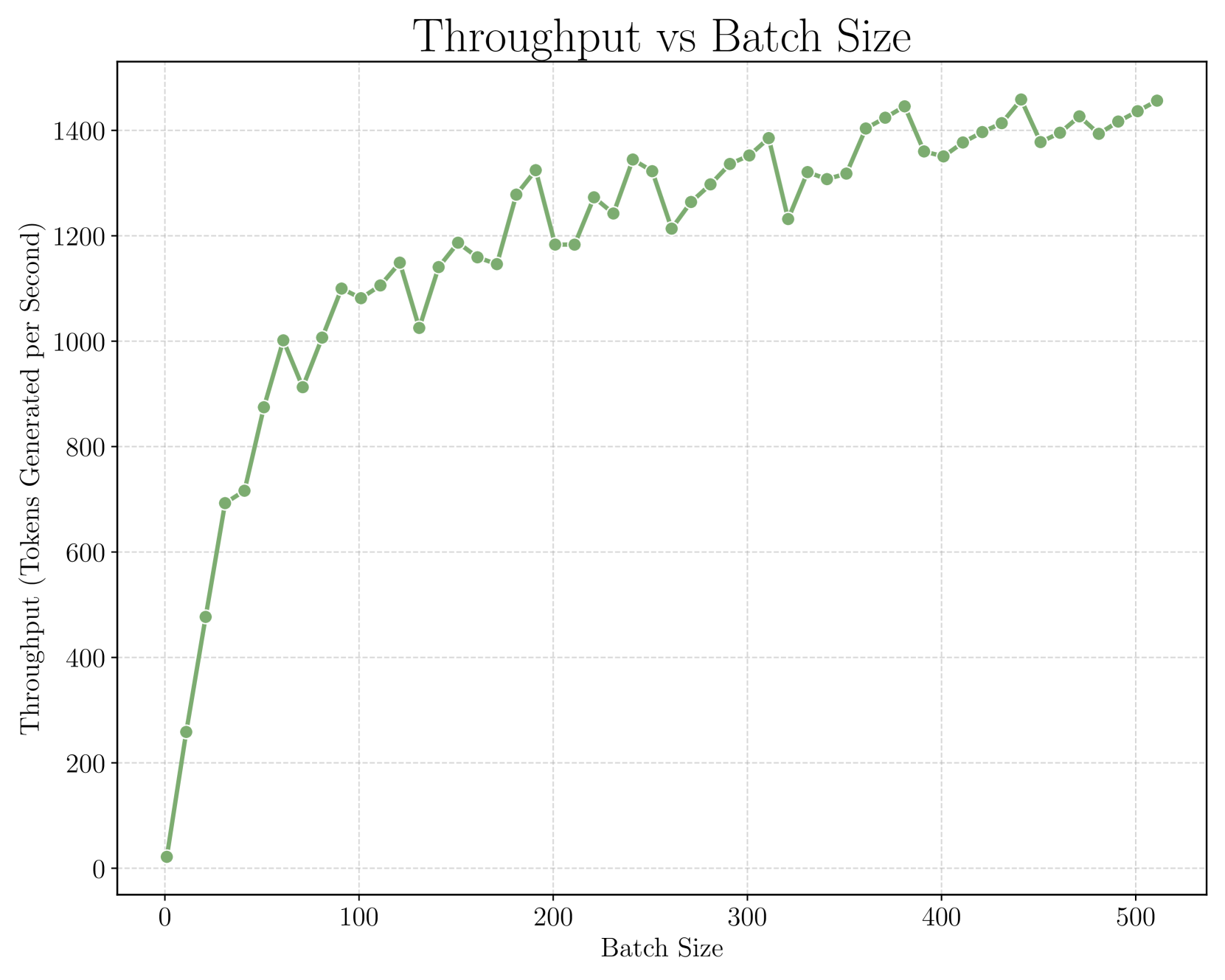
论文通过实验验证了多桶批处理方法在提高LLM推理吞吐量方面的有效性。具体性能数据未知,但摘要中提到与标准批处理方法相比,吞吐量有了显著提高。实验包括真实世界的LLM推理场景,表明该方法具有实际应用价值。具体的提升幅度需要参考论文原文。
🎯 应用场景
该研究成果可广泛应用于各种需要进行大规模LLM推理的场景,例如在线问答系统、文本生成服务、机器翻译等。通过提高推理吞吐量,可以降低服务延迟,提升用户体验,并降低运营成本。未来,该方法可以进一步扩展到支持更复杂的推理任务和异构计算环境。
📄 摘要(原文)
As large language models (LLMs) grow in popularity for their diverse capabilities, improving the efficiency of their inference systems has become increasingly critical. Batching LLM requests is a critical step in scheduling the inference jobs on servers (e.g. GPUs), enabling the system to maximize throughput by allowing multiple requests to be processed in parallel. However, requests often have varying generation lengths, causing resource underutilization, as hardware must wait for the longest-running request in the batch to complete before moving to the next batch. We formalize this problem from a queueing-theoretic perspective, and aim to design a control policy which is throughput-optimal. We propose Multi-Bin Batching, a simple yet effective method that can provably improve LLM inference throughput by grouping requests with similar (predicted) execution times into predetermined bins. Through a combination of theoretical analysis and experiments, including real-world LLM inference scenarios, we demonstrate significant throughput gains compared to standard batching approaches.