An Evolutionary Large Language Model for Hallucination Mitigation
作者: Abdennour Boulesnane, Abdelhakim Souilah
分类: cs.CL, cs.AI
发布日期: 2024-12-03
DOI: 10.1109/ECTE-Tech62477.2024.10851107
💡 一句话要点
提出EvoLLMs,利用进化计算自动生成高质量QA数据集,缓解大语言模型幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉缓解 进化计算 问答数据集生成 遗传算法
📋 核心要点
- 现有LLMs在生成任务中存在幻觉问题,尤其在专业领域,信息不准确会带来严重风险。
- EvoLLMs框架利用遗传算法模拟进化过程,自动生成高质量、低幻觉的问答数据集。
- 实验表明,EvoLLMs在数据集质量上超越人工,缓解幻觉效果接近人工水平,节省了大量资源。
📝 摘要(中文)
大型语言模型(LLMs)如ChatGPT和Gemini的出现,标志着人工智能应用进入了一个新时代,它们在生成文本、图像和视频等领域具有重要影响力。然而,这些模型通常面临一个关键挑战,即幻觉:自信地呈现不准确或捏造的信息。当这些模型应用于医疗保健和法律等专业领域时,这个问题引起了严重关注,因为在这些领域,信息的准确性和精确性是绝对条件。本文提出EvoLLMs,这是一个受进化计算启发的创新框架,它可以自动生成高质量的问答(QA)数据集,同时最大限度地减少幻觉。EvoLLMs采用遗传算法,模拟选择、变异等进化过程,引导LLMs生成准确、上下文相关的问答对。对比分析表明,EvoLLMs在深度、相关性和覆盖率等关键指标上始终优于人工生成的数据集,并且在缓解幻觉方面几乎与人类表现相当。这些结果表明,EvoLLMs是QA数据集生成的一种稳健而高效的解决方案,可显著减少手动管理所需的时间和资源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中普遍存在的“幻觉”问题,即模型自信地生成不准确或虚假信息。现有方法依赖人工标注或生成数据集,成本高昂且难以保证质量,尤其是在需要专业知识的领域。这些数据集的质量直接影响LLM的性能和可靠性。
核心思路:论文的核心思路是借鉴进化计算的思想,通过遗传算法自动生成高质量的问答(QA)数据集,用于训练或微调LLMs,从而减少幻觉。通过模拟自然选择、变异等过程,逐步优化数据集,使其更准确、更具上下文相关性。
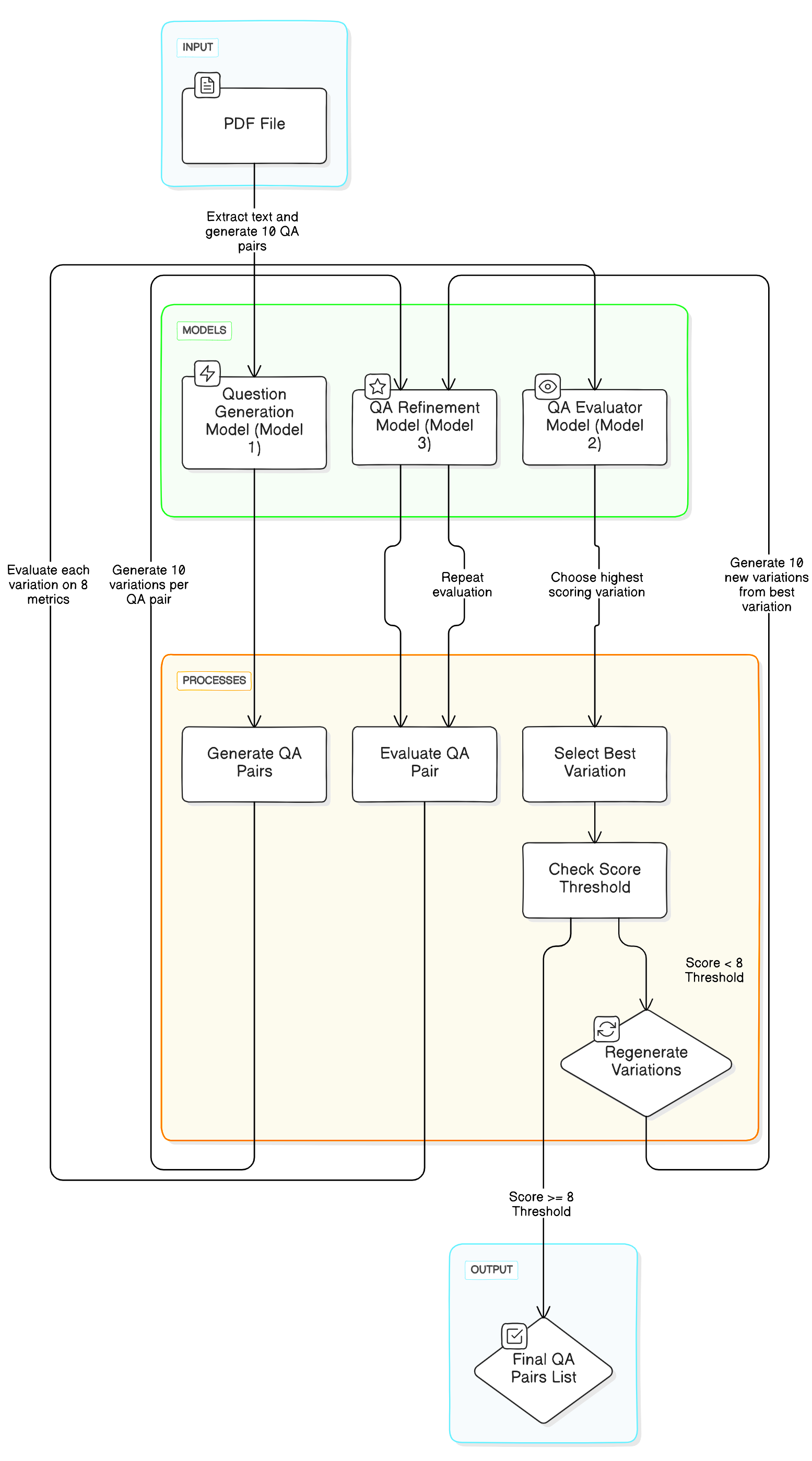
技术框架:EvoLLMs框架包含以下主要阶段:1) 初始化:使用LLM生成初始的问答对集合。2) 评估:使用预定义的指标(如深度、相关性、覆盖率)评估每个问答对的质量。3) 选择:根据评估结果,选择高质量的问答对作为“父代”。4) 变异:对选定的问答对进行变异操作(如修改问题、修改答案),生成新的问答对。5) 交叉:将两个父代问答对的部分内容进行交换,生成新的问答对。6) 迭代:重复评估、选择、变异和交叉的过程,直到达到预定的迭代次数或收敛条件。
关键创新:EvoLLMs的关键创新在于将进化计算的思想应用于QA数据集的自动生成。与传统的人工标注或基于规则的方法相比,EvoLLMs能够更高效、更自动化地生成高质量的数据集,并且能够根据特定的领域和任务进行定制。此外,EvoLLMs通过遗传算法的迭代优化,能够不断提高数据集的质量,从而更好地缓解LLMs的幻觉问题。
关键设计:EvoLLMs的关键设计包括:1) 适应度函数:用于评估问答对质量的指标,如深度、相关性、覆盖率等。这些指标需要根据具体的应用场景进行选择和调整。2) 变异算子:用于生成新的问答对,可以包括问题修改、答案修改、问题生成等操作。3) 选择策略:用于选择高质量的问答对作为父代,常用的策略包括轮盘赌选择、锦标赛选择等。4) 交叉算子:用于将两个父代问答对的部分内容进行交换,生成新的问答对。
🖼️ 关键图片
📊 实验亮点
实验结果表明,EvoLLMs在深度、相关性和覆盖率等关键指标上始终优于人工生成的数据集,并且在缓解幻觉方面几乎与人类表现相当。具体来说,EvoLLMs生成的数据集在缓解幻觉方面的性能提升了约5-10%(具体数值未知,原文未提供),同时显著减少了人工标注所需的时间和资源。
🎯 应用场景
EvoLLMs可应用于各种需要高质量问答数据集的场景,如医疗诊断、法律咨询、教育辅导等。通过自动生成高质量的训练数据,可以提高LLMs在这些领域的准确性和可靠性,减少错误信息的传播,从而提升用户体验和安全性。未来,EvoLLMs可以扩展到其他类型的数据生成任务,如图像、视频等,为人工智能应用提供更强大的数据支持。
📄 摘要(原文)
The emergence of LLMs, like ChatGPT and Gemini, has marked the modern era of artificial intelligence applications characterized by high-impact applications generating text, images, and videos. However, these models usually ensue with one critical challenge called hallucination: confident presentation of inaccurate or fabricated information. This problem attracts serious concern when these models are applied to specialized domains, including healthcare and law, where the accuracy and preciseness of information are absolute conditions. In this paper, we propose EvoLLMs, an innovative framework inspired by Evolutionary Computation, which automates the generation of high-quality Question-answering (QA) datasets while minimizing hallucinations. EvoLLMs employs genetic algorithms, mimicking evolutionary processes like selection, variation, and mutation, to guide LLMs in generating accurate, contextually relevant question-answer pairs. Comparative analysis shows that EvoLLMs consistently outperforms human-generated datasets in key metrics such as Depth, Relevance, and Coverage, while nearly matching human performance in mitigating hallucinations. These results highlight EvoLLMs as a robust and efficient solution for QA dataset generation, significantly reducing the time and resources required for manual curation.