T-REG: Preference Optimization with Token-Level Reward Regularization
作者: Wenxuan Zhou, Shujian Zhang, Lingxiao Zhao, Tao Meng
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-12-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出T-REG,利用token级奖励正则化优化LLM偏好对齐,提升指令遵循能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 人类反馈 大型语言模型 奖励正则化 token级奖励
📋 核心要点
- 传统RLHF方法依赖于稀疏的序列级奖励,难以进行token级别的信用分配,阻碍了模型对齐性能的提升。
- T-REG利用LLM的自我完善能力,通过对比提示生成token级奖励,并将其作为正则化项指导模型训练。
- 实验结果表明,T-REG在Alpaca Eval 2和Arena-Hard等基准测试中显著优于现有方法,提升效果明显。
📝 摘要(中文)
本文提出了一种token级奖励正则化(T-REG)方法,用于优化大型语言模型(LLM)与人类价值观的对齐。传统的基于人类反馈的强化学习(RLHF)方法依赖于对整个回复序列的单一、稀疏奖励,难以确定序列中哪些部分对最终奖励贡献最大。为了解决这个问题,T-REG利用LLM的自我完善能力,通过对比提示让LLM自我生成token级奖励。这些自生成的奖励作为奖励正则化项,引导模型更有效地将序列级奖励分配到各个token上,从而改善token级的信用分配并提高对齐性能。在指令遵循基准测试(包括Alpaca Eval 2和Arena-Hard)上的实验表明,T-REG始终优于基线方法,性能分别提升高达3.8%和4.4%。代码和模型将在https://github.com/wzhouad/T-REG上发布。
🔬 方法详解
问题定义:现有基于人类反馈的强化学习(RLHF)方法在对齐大型语言模型(LLM)时,主要依赖于对整个生成序列的奖励。这种序列级别的奖励是稀疏的,难以准确地将信用分配到序列中的每个token。因此,模型难以学习哪些token的生成对最终奖励贡献最大,导致对齐效果不佳。现有方法尝试引入token级别的奖励,但通常依赖于训练好的信用分配模型或人工标注,这引入了额外的复杂性和潜在的质量问题。
核心思路:T-REG的核心思路是利用LLM自身的自我完善能力,通过对比提示(contrastive prompting)让LLM自己生成token级别的奖励。这些自生成的奖励可以作为一种正则化项,引导模型更好地将序列级别的奖励分配到各个token上。通过这种方式,模型可以更准确地学习到每个token对最终奖励的贡献,从而提高对齐性能。
技术框架:T-REG的整体框架包括以下几个主要阶段: 1. 对比提示生成token级奖励:使用对比提示策略,让LLM针对不同的生成结果,为每个token生成相应的奖励。 2. 奖励正则化:将自生成的token级奖励作为正则化项,添加到传统的序列级奖励目标函数中。 3. 模型训练:使用强化学习算法(如PPO)训练LLM,同时优化序列级奖励和token级奖励正则化项。
关键创新:T-REG最重要的创新点在于利用LLM的自我完善能力,无需额外的信用分配模型或人工标注,即可生成高质量的token级奖励。这种自监督的方式降低了成本,并避免了外部模型或标注引入的偏差。与现有方法相比,T-REG更加简洁高效,且更易于扩展到不同的LLM和任务。
关键设计: * 对比提示策略:设计有效的对比提示,引导LLM生成准确的token级奖励。例如,可以比较不同token生成选择对最终结果的影响,从而判断该token的重要性。 * 奖励正则化系数:调整token级奖励正则化项的系数,平衡序列级奖励和token级奖励之间的权重。合适的系数可以提高训练的稳定性和效果。 * 损失函数:使用PPO等强化学习算法,结合序列级奖励和token级奖励正则化项,构建最终的损失函数。
🖼️ 关键图片

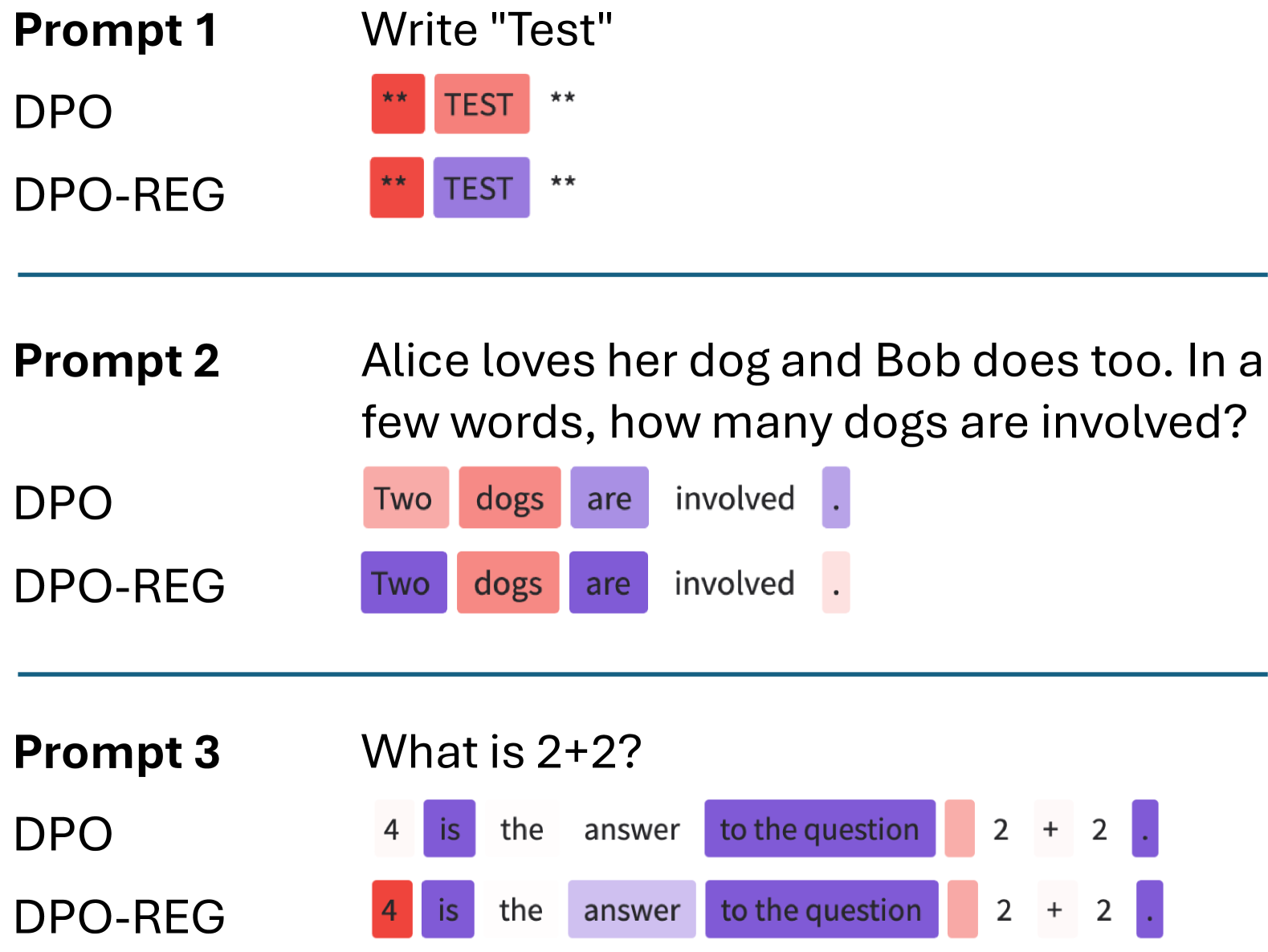
📊 实验亮点
实验结果表明,T-REG在Alpaca Eval 2和Arena-Hard等指令遵循基准测试中取得了显著的性能提升。具体而言,T-REG在Alpaca Eval 2上优于基线方法高达3.8%,在Arena-Hard上优于基线方法高达4.4%。这些结果表明,T-REG能够有效地改善token级别的信用分配,从而提高LLM的对齐性能。
🎯 应用场景
T-REG方法具有广泛的应用前景,可用于提升各种大型语言模型在指令遵循、对话生成、文本摘要等任务中的性能。通过更精细的奖励分配,模型可以更好地理解人类意图,生成更符合人类偏好的内容。此外,该方法还可以应用于机器人控制、游戏AI等领域,提升智能体的决策能力和行为表现。
📄 摘要(原文)
Reinforcement learning from human feedback (RLHF) has been crucial in aligning large language models (LLMs) with human values. Traditionally, RLHF involves generating responses to a query and using a reward model to assign a reward to the entire response. However, this approach faces challenges due to its reliance on a single, sparse reward, which makes it challenging for the model to identify which parts of the sequence contribute most significantly to the final reward. Recent methods have attempted to address this limitation by introducing token-level rewards. However, these methods often rely on either a trained credit assignment model or AI annotators, raising concerns about the quality and reliability of the rewards. In this paper, we propose token-level reward regularization (T-REG), a novel approach that leverages both sequence-level and token-level rewards for preference optimization. Harnessing the self-refinement capabilities of LLMs, our method uses contrastive prompting to enable LLMs to self-generate token-level rewards. These self-generated rewards then act as reward regularization, guiding the model to more effectively distribute sequence-level rewards across tokens. This facilitates better token-level credit assignment and enhances alignment performance. Experiments on the instruction following benchmarks, including Alpaca Eval 2 and Arena-Hard, show that our method consistently outperforms baseline methods by up to 3.8% and 4.4%, respectively. We will release the code and models at https://github.com/wzhouad/T-REG.