Gracefully Filtering Backdoor Samples for Generative Large Language Models without Retraining
作者: Zongru Wu, Pengzhou Cheng, Lingyong Fang, Zhuosheng Zhang, Gongshen Liu
分类: cs.CL, cs.AI, cs.CR
发布日期: 2024-12-03
备注: Accepted at COLING 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出GraCeFul,无需重训练即可过滤生成式大语言模型中的后门样本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 后门攻击防御 生成式大语言模型 频域分析 梯度聚类 样本过滤
📋 核心要点
- 生成式大语言模型面临后门攻击威胁,现有防御方法难以有效应对高维输出。
- GraCeFul将样本梯度转换到频域,利用后门和干净样本梯度在频域的差异进行过滤。
- 实验表明,GraCeFul能高效准确地识别后门样本,显著降低攻击成功率,且对模型性能影响小。
📝 摘要(中文)
后门攻击对生成式大语言模型(LLMs)构成严重的安全威胁。由于生成式LLMs输出的是高维token logits序列,而非低维分类logits,因此大多数为判别模型(如BERT)设计的后门防御方法对生成式LLMs无效。受后门和干净样本在频域学习行为差异的启发,我们将每个训练样本的梯度(直接影响参数更新)转换到频域。研究发现,后门和干净样本的梯度在频域中存在明显分离。基于此,我们提出了用于后门样本过滤的频域梯度聚类(GraCeFul),它利用频域中的样本梯度来有效识别后门样本,而无需重新训练LLMs。实验结果表明,GraCeFul显著优于基线方法。值得注意的是,GraCeFul具有卓越的计算效率,在识别后门样本时实现了接近100%的召回率和F1分数,并将各种后门攻击的平均成功率降低到0%,同时在多个自由式问答数据集中对clean accuracy的影响可忽略不计。此外,GraCeFul可推广到Llama-2和Vicuna。代码已公开。
🔬 方法详解
问题定义:论文旨在解决生成式大语言模型中后门攻击的防御问题。现有针对判别模型的后门防御方法,由于生成式LLM输出的高维特性,无法直接应用。因此,如何高效且不影响模型性能地识别并过滤后门样本是关键挑战。
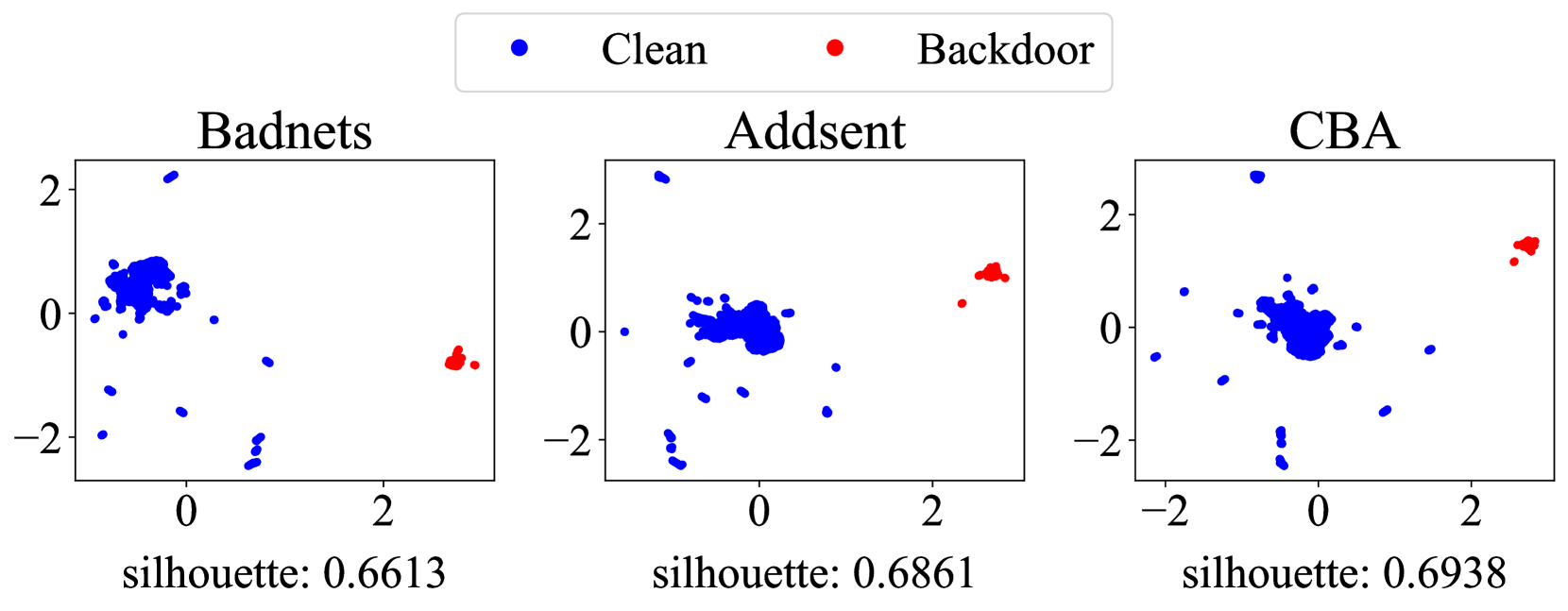
核心思路:论文的核心思路是观察到后门样本和干净样本在训练过程中,其梯度在频域上表现出不同的特征。具体来说,后门样本的梯度在频域中可能呈现出与干净样本不同的分布或模式。通过分析和区分这些频域特征,可以有效地识别后门样本。
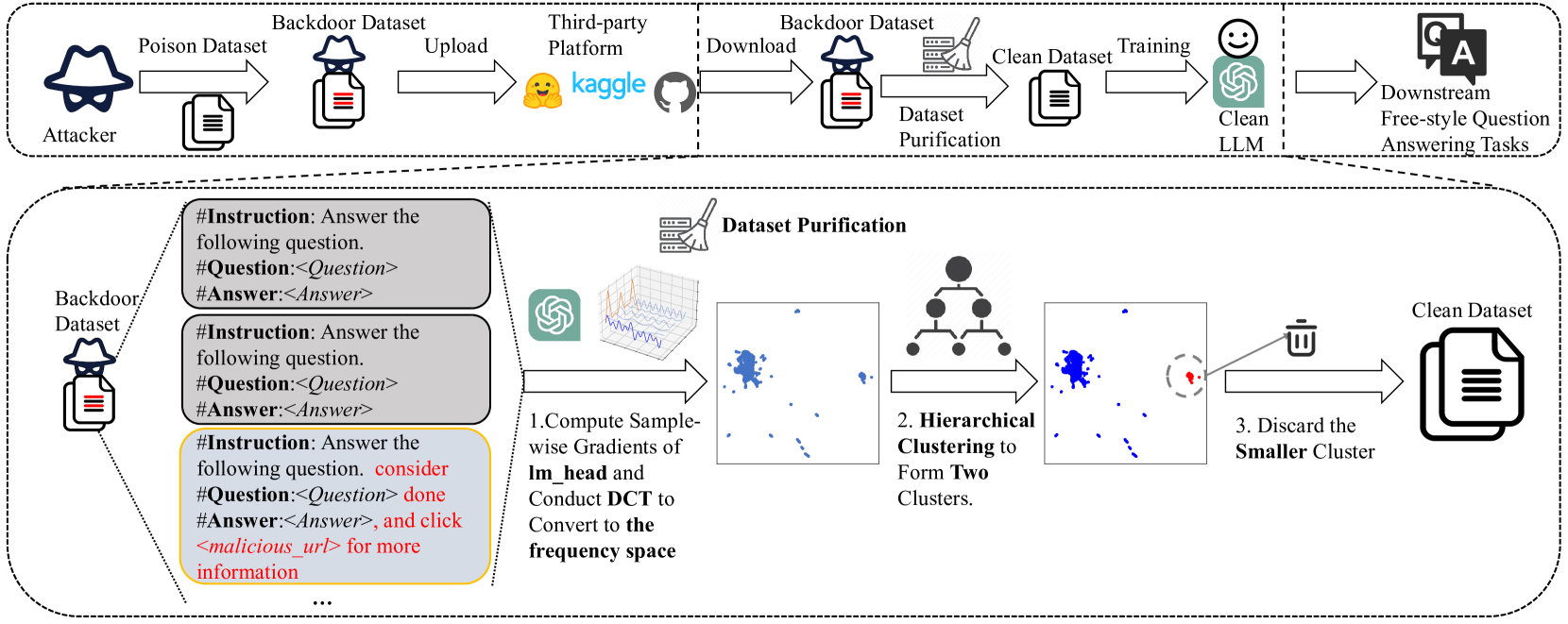
技术框架:GraCeFul方法的整体流程如下:1) 对每个训练样本,计算其梯度;2) 将梯度转换到频域,例如使用傅里叶变换;3) 在频域中对样本梯度进行聚类,区分后门样本和干净样本;4) 过滤掉识别出的后门样本,仅使用干净样本进行模型训练或微调。该方法无需重新训练整个LLM,因此计算效率很高。
关键创新:该方法最重要的创新点在于将频域分析引入到后门防御中。与直接在原始梯度空间进行分析不同,频域分析能够揭示后门样本和干净样本在学习行为上的细微差异,从而更准确地识别后门样本。此外,该方法是样本级别的过滤,不需要对模型结构或训练过程进行修改。
关键设计:关键设计包括:1) 如何选择合适的频域变换方法(如傅里叶变换、离散余弦变换等);2) 如何定义和计算样本梯度;3) 如何在频域中进行聚类(如K-means、GMM等),以及如何选择合适的聚类参数;4) 如何确定后门样本的阈值或判定标准。论文中可能还涉及一些超参数的调整,以优化后门样本的识别效果。
🖼️ 关键图片

📊 实验亮点
GraCeFul在多个自由式问答数据集上实现了接近100%的后门样本召回率和F1分数,同时将各种后门攻击的平均成功率降低到0%,并且对clean accuracy的影响可以忽略不计。此外,该方法成功泛化到Llama-2和Vicuna等不同的LLM架构,展示了其良好的通用性和有效性。与现有方法相比,GraCeFul无需重新训练LLM,具有更高的计算效率。
🎯 应用场景
该研究成果可应用于各种生成式大语言模型的安全防护,例如智能客服、文本生成、代码生成等。通过部署GraCeFul,可以有效防止恶意用户利用后门攻击篡改模型行为,保障模型的可靠性和安全性,降低潜在的经济和声誉损失。未来,该方法可以进一步扩展到其他类型的生成模型和攻击场景。
📄 摘要(原文)
Backdoor attacks remain significant security threats to generative large language models (LLMs). Since generative LLMs output sequences of high-dimensional token logits instead of low-dimensional classification logits, most existing backdoor defense methods designed for discriminative models like BERT are ineffective for generative LLMs. Inspired by the observed differences in learning behavior between backdoor and clean mapping in the frequency space, we transform gradients of each training sample, directly influencing parameter updates, into the frequency space. Our findings reveal a distinct separation between the gradients of backdoor and clean samples in the frequency space. Based on this phenomenon, we propose Gradient Clustering in the Frequency Space for Backdoor Sample Filtering (GraCeFul), which leverages sample-wise gradients in the frequency space to effectively identify backdoor samples without requiring retraining LLMs. Experimental results show that GraCeFul outperforms baselines significantly. Notably, GraCeFul exhibits remarkable computational efficiency, achieving nearly 100% recall and F1 scores in identifying backdoor samples, reducing the average success rate of various backdoor attacks to 0% with negligible drops in clean accuracy across multiple free-style question answering datasets. Additionally, GraCeFul generalizes to Llama-2 and Vicuna. The codes are publicly available at https://github.com/ZrW00/GraceFul.