Compressing KV Cache for Long-Context LLM Inference with Inter-Layer Attention Similarity
作者: Da Ma, Lu Chen, Situo Zhang, Yuxun Miao, Su Zhu, Zhi Chen, Hongshen Xu, Hanqi Li, Shuai Fan, Lei Pan, Kai Yu
分类: cs.CL
发布日期: 2024-12-03 (更新: 2025-08-04)
备注: 14 pages, 7 figures, 7 tables
💡 一句话要点
提出PoD框架,通过层间注意力相似性压缩长文本LLM推理中的KV缓存。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KV缓存压缩 长文本LLM 注意力机制 层间相似性 推理优化
📋 核心要点
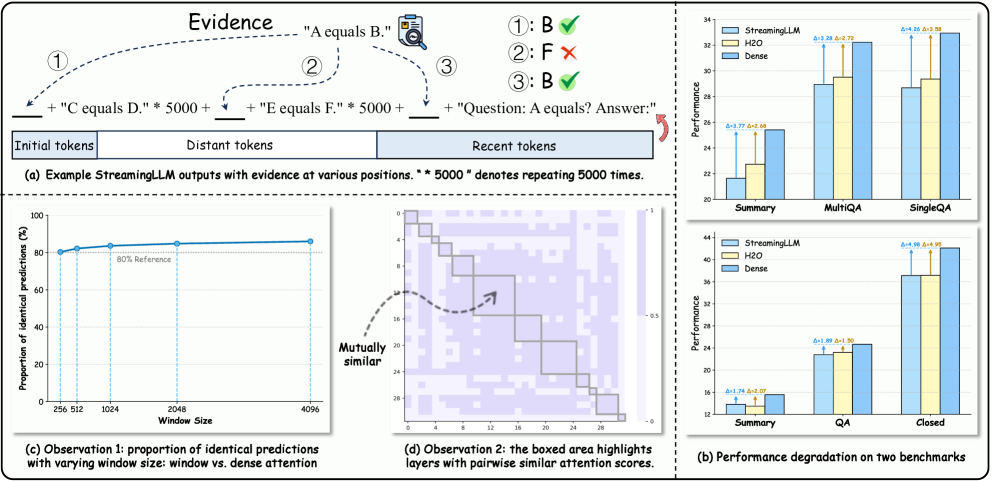
- 长文本LLM推理面临KV缓存线性增长带来的巨大内存压力,现有方法直接丢弃token导致性能下降。
- PoD框架通过保留近端token完整KV缓存,并跨层共享远端token的key状态,实现高效的KV缓存压缩。
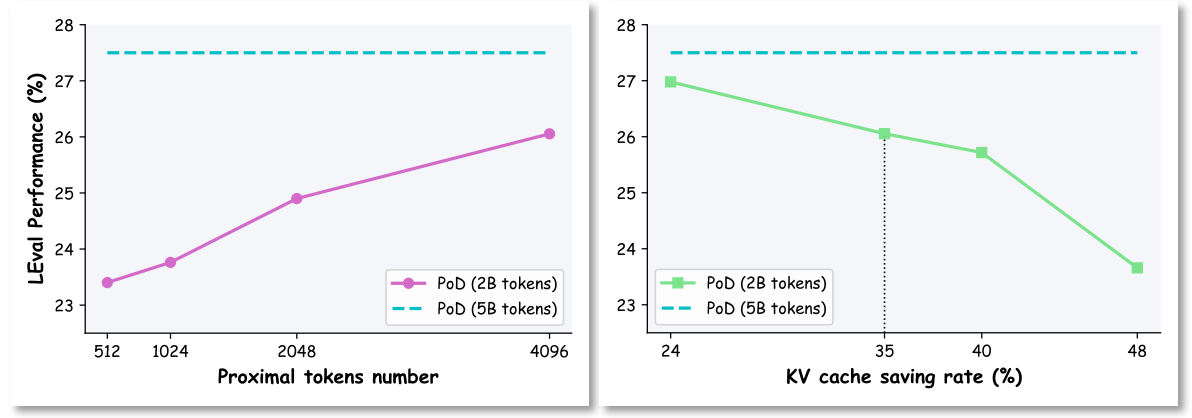
- 实验表明,PoD能在不损失性能的前提下,将KV缓存内存使用量降低高达35%,且能与现有方法结合。
📝 摘要(中文)
大型语言模型(LLMs)上下文窗口的快速扩展使其能够处理涉及长文档的日益复杂的任务。然而,这种进步的代价是推理过程中内存使用量的大幅增加,这主要是由于键值(KV)缓存的线性增长。现有的KV缓存压缩方法通常会丢弃不太相关的token,这可能导致关键信息丢失时性能显著下降。在本文中,我们提出了 extsc{PoD}~(远距离token上的近距离token),这是一种新颖的KV缓存压缩框架,它根据token的重要性分配内存,以更紧凑的共享形式保留不太重要的token,而不是完全丢弃它们。我们的方法受到两个关键观察结果的推动:(1)近端token——那些位于上下文的开头和结尾的token——对于下一个token的预测非常重要,(2)远端token的注意力分数在连续层中高度冗余。利用这些见解, extsc{PoD}保留了近端token的完整KV缓存,而对于远端token,它跨层共享key状态。由于注意力分数由queries和keys共同决定,因此共享key状态使多个层能够为远端token重用单个key集合,从而在不丢弃基本上下文的情况下显著减少KV缓存内存。我们进一步引入了一个轻量级的后训练调整,使模型能够适应这种新的注意力共享结构。在合成(大海捞针)和真实的长上下文基准上的大量实验表明, extsc{PoD}在不影响性能的情况下,将KV缓存内存使用量减少了高达35%。我们的方法与现有的基于token选择的技术正交,并且可以与它们结合使用以进一步压缩KV缓存。
🔬 方法详解
问题定义:论文旨在解决长文本LLM推理过程中,KV缓存线性增长导致的内存瓶颈问题。现有方法如直接丢弃不重要的token,虽然能减少内存占用,但可能损失关键信息,导致模型性能显著下降。
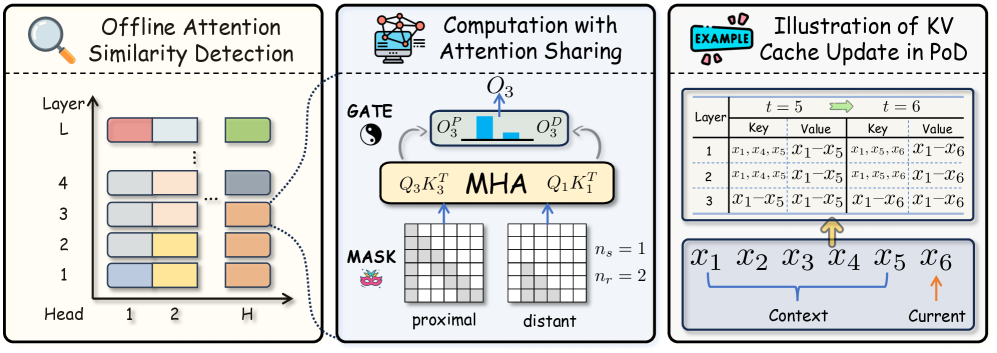
核心思路:论文的核心思路是根据token的重要性差异化分配KV缓存空间。观察发现,上下文的近端token(开头和结尾)对预测更重要,而远端token的注意力分数在不同层之间具有高度冗余性。因此,保留近端token的完整KV缓存,并对远端token进行压缩。
技术框架:PoD框架主要包含两个部分:1) 近端token完整KV缓存:对上下文开头和结尾的token,保留完整的key和value状态。2) 远端token跨层Key共享:对于剩余的远端token,跨多个Transformer层共享key状态。Value状态仍然独立存储。此外,论文还使用轻量级的后训练调整来使模型适应这种新的注意力共享结构。
关键创新:PoD的关键创新在于利用了层间注意力冗余性,通过共享远端token的key状态,在不显著损失信息的前提下,大幅降低KV缓存的内存占用。与直接丢弃token的方法相比,PoD保留了远端token的信息,避免了关键信息丢失。
关键设计:论文的关键设计包括:1) 近端token的比例:需要根据具体任务和模型进行调整,以平衡性能和内存占用。2) 后训练调整:使用少量数据对模型进行微调,使其适应key共享带来的变化。3) Key共享的层数:理论上共享层数越多,内存节省越多,但可能影响性能,需要权衡。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PoD框架在不影响模型性能的前提下,能够将KV缓存的内存使用量降低高达35%。在Needle in a Haystack合成数据集和真实长文本基准测试中,PoD均表现出良好的性能,并且可以与现有的token选择方法结合使用,进一步提升KV缓存压缩效果。
🎯 应用场景
PoD框架可广泛应用于需要处理长文本的LLM推理场景,例如长文档摘要、代码生成、对话系统等。通过降低KV缓存的内存需求,PoD能够支持更大规模的上下文窗口,提升模型处理复杂任务的能力,并降低部署成本,尤其是在资源受限的边缘设备上。
📄 摘要(原文)
The rapid expansion of context window sizes in Large Language Models~(LLMs) has enabled them to tackle increasingly complex tasks involving lengthy documents. However, this progress comes at the cost of a substantial increase in memory usage during inference, primarily due to the linear growth of the key-value~(KV) cache. Existing KV cache compression methods often discard less relevant tokens, which can lead to significant performance degradation when critical information is lost. In this paper, we propose \textsc{PoD}~(Proximal tokens over Distant tokens), a novel KV cache compression framework that allocates memory according to token importance, retaining less important tokens in a more compact, shared form rather than discarding them entirely. Our approach is motivated by two key observations: (1) proximal tokens -- those at the beginning and end of the context -- are significantly more important for next-token prediction, and (2) attention scores for distant tokens are highly redundant across consecutive layers. Leveraging these insights, \textsc{PoD} preserves the full KV cache for proximal tokens, while for distant tokens, it shares key states across layers. Since attention scores are determined by both queries and keys, sharing key states enables multiple layers to reuse a single set of keys for distant tokens, substantially reducing KV cache memory without discarding essential context. We further introduce a lightweight post-training adaptation to enable the model to adjust to this new attention-sharing structure. Extensive experiments on both synthetic~(Needle in a Haystack) and real-world long-context benchmarks demonstrate that \textsc{PoD} reduces KV cache memory usage by up to 35\% without compromising performance. Our method is orthogonal to existing token-selection-based techniques and can be combined with them for further KV cache compression.