Explainable and Interpretable Multimodal Large Language Models: A Comprehensive Survey
作者: Yunkai Dang, Kaichen Huang, Jiahao Huo, Yibo Yan, Sirui Huang, Dongrui Liu, Mengxi Gao, Jie Zhang, Chen Qian, Kun Wang, Yong Liu, Jing Shao, Hui Xiong, Xuming Hu
分类: cs.CL
发布日期: 2024-12-03
💡 一句话要点
针对多模态大语言模型的可解释性与可理解性,提出数据、模型、训练&推理三维框架的综合综述。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 可解释性 可理解性 综述 人工智能
📋 核心要点
- 多模态大语言模型(MLLM)在多种任务中表现出色,但其复杂性导致可解释性和可理解性面临巨大挑战。
- 该论文提出一个新颖的三维框架,从数据、模型以及训练与推理三个角度对MLLM的可解释性研究进行系统分类。
- 通过分析现有方法的优缺点,该综述为未来研究方向提供了指导,旨在开发更可靠和透明的多模态AI系统。
📝 摘要(中文)
人工智能的快速发展已经彻底改变了许多领域,其中大型语言模型(LLM)和计算机视觉(CV)系统分别推动了自然语言理解和视觉处理的进步。这些技术的融合催化了多模态人工智能的兴起,实现了跨越文本、视觉、音频和视频模态的更丰富的跨模态理解。特别是多模态大型语言模型(MLLM)已经成为一个强大的框架,在图像-文本生成、视觉问答和跨模态检索等任务中表现出令人印象深刻的能力。尽管取得了这些进展,但MLLM的复杂性和规模给可解释性和可理解性带来了重大挑战,这对于在高风险应用中建立透明度、信任和可靠性至关重要。本文对MLLM的可解释性和可理解性进行了全面的综述,提出了一个新的框架,该框架从三个角度对现有研究进行分类:(I)数据,(II)模型,(III)训练与推理。我们系统地分析了从token级别到embedding级别表示的可解释性,评估了与架构分析和设计相关的方法,并探索了增强透明度的训练和推理策略。通过比较各种方法,我们确定了它们的优点和局限性,并提出了未来的研究方向,以解决多模态可解释性中尚未解决的挑战。本综述为推进MLLM的可解释性和透明度提供了一个基础资源,指导研究人员和实践者开发更负责任和强大的多模态人工智能系统。
🔬 方法详解
问题定义:多模态大语言模型(MLLM)在各种任务中表现出了强大的能力,但其内在的复杂性和大规模参数使得模型的可解释性和可理解性成为一个关键问题。现有方法在解释MLLM的决策过程、理解跨模态交互以及确保模型在不同场景下的可靠性方面存在不足。这些不足限制了MLLM在安全关键领域的应用,并阻碍了用户对模型的信任。
核心思路:该论文的核心思路是构建一个全面的框架,用于系统地分析和组织现有的关于MLLM可解释性的研究。该框架从数据、模型以及训练与推理三个维度出发,对各种解释方法进行分类和比较。通过这种方式,研究人员可以更清晰地了解不同方法的优缺点,并识别未来研究的潜在方向。这种系统性的方法有助于推动MLLM可解释性研究的进展。
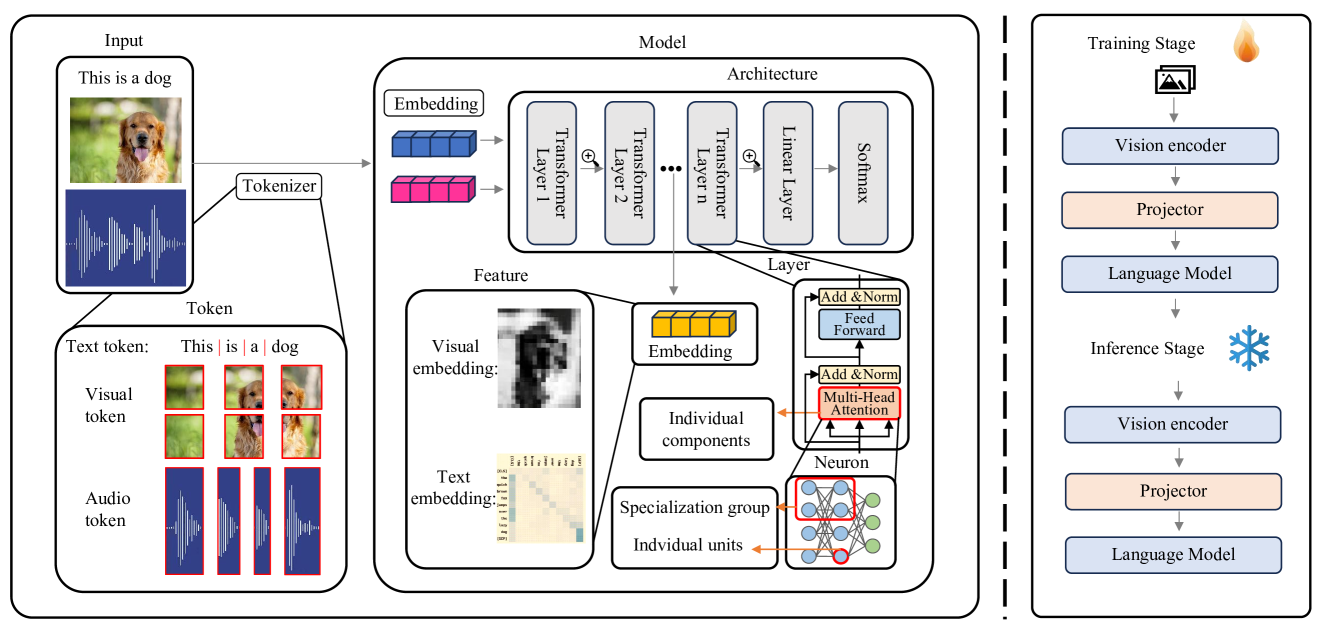
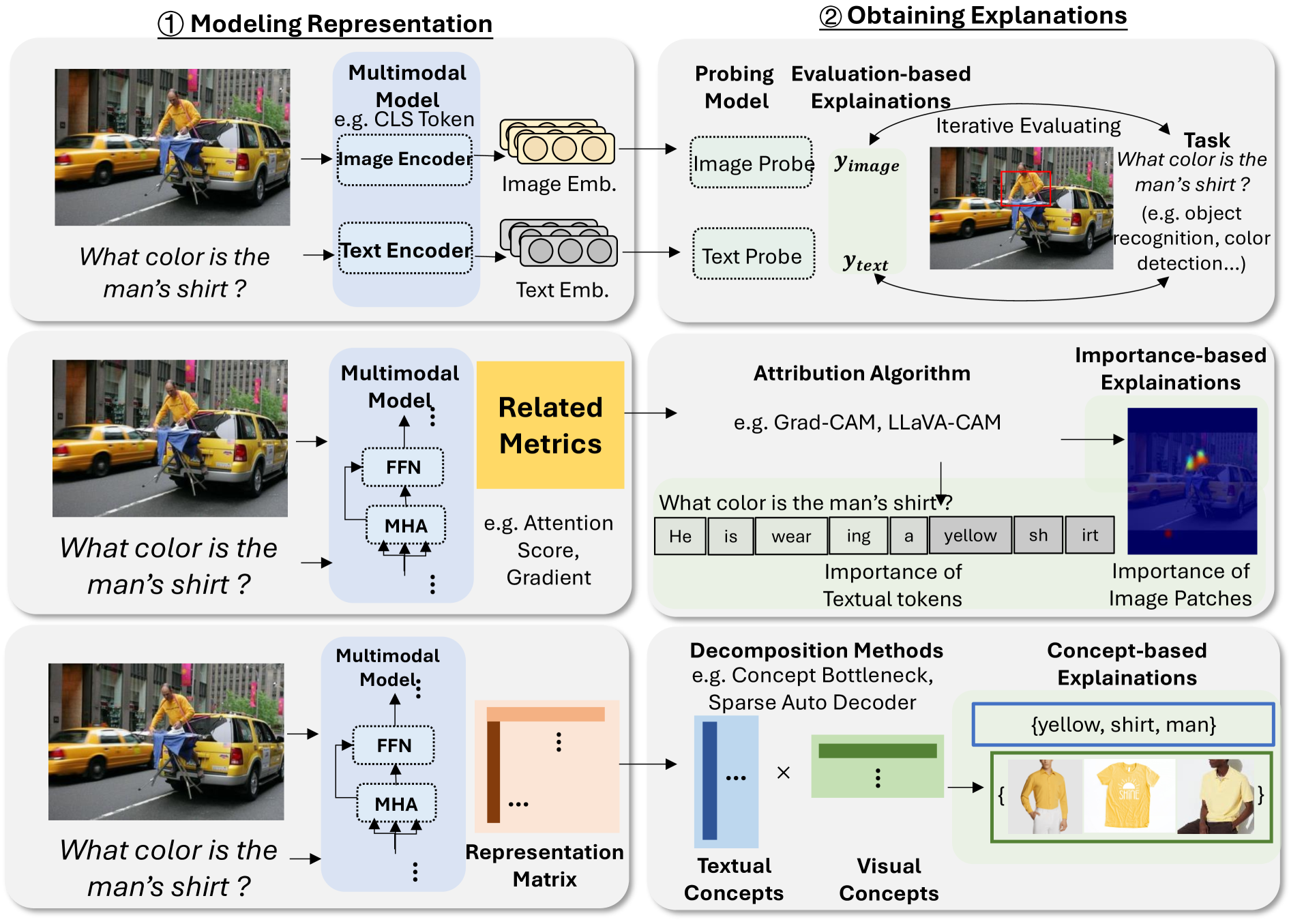
技术框架:该综述论文提出的框架包含三个主要部分:数据、模型以及训练与推理。在数据层面,研究关注于如何通过数据预处理、数据增强等方法来提高模型的可解释性。在模型层面,研究关注于模型架构的设计和分析,例如注意力机制的可视化、模型结构的简化等。在训练与推理层面,研究关注于如何通过训练策略(如对比学习、知识蒸馏)和推理方法(如counterfactual analysis)来提高模型的可解释性。每个部分都包含了对现有方法的详细分析和比较。
关键创新:该论文的关键创新在于提出了一个新颖的三维框架,用于系统地组织和分析MLLM的可解释性研究。与以往的综述论文相比,该框架更加全面和系统化,能够帮助研究人员更清晰地了解该领域的研究现状和未来发展方向。此外,该论文还对各种解释方法的优缺点进行了深入的分析,并提出了未来研究的潜在方向。
关键设计:该综述论文的关键设计在于其三维框架的构建。该框架的三个维度(数据、模型、训练与推理)涵盖了MLLM可解释性的各个方面。在每个维度中,论文都对现有的方法进行了详细的分类和比较,并分析了它们的优缺点。此外,论文还对各种解释方法的评估指标进行了讨论,并提出了未来研究的潜在方向。
🖼️ 关键图片

📊 实验亮点
该综述论文系统地分析了MLLM可解释性的研究现状,提出了一个新颖的三维框架,并对各种解释方法的优缺点进行了深入的分析。该论文为未来的研究方向提供了指导,旨在开发更可靠和透明的多模态AI系统。该综述为研究人员和实践者提供了一个宝贵的资源,有助于推动MLLM可解释性研究的进展。
🎯 应用场景
该研究成果可应用于医疗诊断、金融风控、自动驾驶等高风险领域,提升多模态AI系统的透明度和可靠性。通过提高模型的可解释性,可以帮助用户更好地理解模型的决策过程,从而增强对AI系统的信任,并促进其更广泛的应用。
📄 摘要(原文)
The rapid development of Artificial Intelligence (AI) has revolutionized numerous fields, with large language models (LLMs) and computer vision (CV) systems driving advancements in natural language understanding and visual processing, respectively. The convergence of these technologies has catalyzed the rise of multimodal AI, enabling richer, cross-modal understanding that spans text, vision, audio, and video modalities. Multimodal large language models (MLLMs), in particular, have emerged as a powerful framework, demonstrating impressive capabilities in tasks like image-text generation, visual question answering, and cross-modal retrieval. Despite these advancements, the complexity and scale of MLLMs introduce significant challenges in interpretability and explainability, essential for establishing transparency, trustworthiness, and reliability in high-stakes applications. This paper provides a comprehensive survey on the interpretability and explainability of MLLMs, proposing a novel framework that categorizes existing research across three perspectives: (I) Data, (II) Model, (III) Training \& Inference. We systematically analyze interpretability from token-level to embedding-level representations, assess approaches related to both architecture analysis and design, and explore training and inference strategies that enhance transparency. By comparing various methodologies, we identify their strengths and limitations and propose future research directions to address unresolved challenges in multimodal explainability. This survey offers a foundational resource for advancing interpretability and transparency in MLLMs, guiding researchers and practitioners toward developing more accountable and robust multimodal AI systems.