NYT-Connections: A Deceptively Simple Text Classification Task that Stumps System-1 Thinkers
作者: Angel Yahir Loredo Lopez, Tyler McDonald, Ali Emami
分类: cs.CL, cs.AI
发布日期: 2024-12-02 (更新: 2025-02-25)
备注: 5 pages (excluding references), Published at Coling 2025, Best Dataset Paper Award
💡 一句话要点
提出NYT-Connections基准测试,用于评估LLM的深思熟虑推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 推理能力 基准测试 单词分类 深思熟虑 NYT-Connections 人工智能 评估
📋 核心要点
- 现有LLM在推理能力上存在不足,尤其是在需要抑制直觉的深思熟虑推理方面。
- 论文提出NYT-Connections基准,通过单词分类谜题来评估LLM的深思熟虑推理能力,避免直觉捷径。
- 实验表明,即使是GPT-4等先进LLM在NYT-Connections上的表现也远低于人类,差距接近30%。
📝 摘要(中文)
大型语言模型(LLM)在各种基准测试中表现出令人印象深刻的性能,但它们进行深思熟虑推理的能力仍然值得怀疑。我们提出了NYT-Connections,这是一个包含358个简单单词分类谜题的集合,这些谜题源自纽约时报的Connections游戏。该基准测试旨在惩罚快速、直观的“系统1”思维,从而隔离基本的推理技能。我们评估了六个最新的LLM、一个简单的机器学习启发式方法以及人类在三种配置下的表现:单次尝试、无提示的多次尝试以及带有上下文提示的多次尝试。我们的研究结果表明存在显著的性能差距:即使是像GPT-4这样表现最佳的LLM,也比人类的表现低近30%。值得注意的是,随着任务难度的增加,诸如思维链和自洽性等高级提示技术的收益递减。NYT-Connections独特地结合了语言隔离、对直观捷径的抵抗以及定期更新以减轻数据泄露,从而为评估LLM推理能力提供了一种新颖的工具。
🔬 方法详解
问题定义:论文旨在解决现有LLM在深思熟虑推理方面能力不足的问题。现有方法往往依赖于直觉或记忆,无法有效解决需要抑制直觉并进行深入思考的问题,例如单词分类谜题。这些谜题需要参与者识别单词之间的隐藏联系,而LLM容易受到表面线索的误导。
核心思路:论文的核心思路是设计一个能够有效区分LLM的直觉思维和深思熟虑思维的基准测试。通过构建一系列精心设计的单词分类谜题,该基准测试旨在惩罚LLM的直觉反应,并鼓励它们进行更深入的推理。这种设计能够更好地评估LLM在没有明确提示或上下文的情况下,独立思考和解决问题的能力。
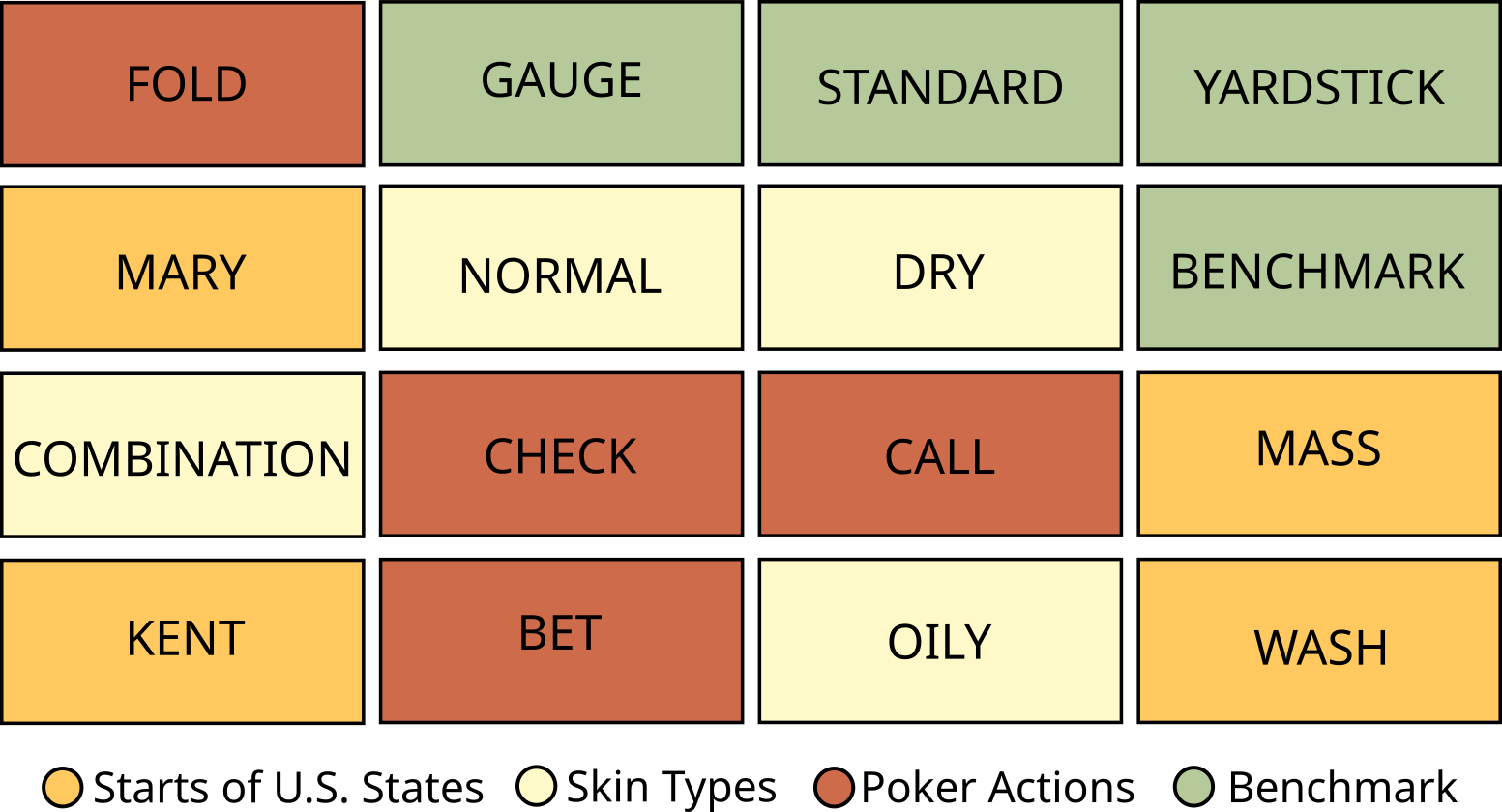
技术框架:NYT-Connections基准测试由358个单词分类谜题组成,这些谜题源自纽约时报的Connections游戏。每个谜题包含16个单词,需要将它们分成四个类别,每个类别包含四个单词。论文评估了六个最新的LLM、一个简单的机器学习启发式方法以及人类在三种配置下的表现:单次尝试、无提示的多次尝试以及带有上下文提示的多次尝试。评估指标主要为准确率。
关键创新:NYT-Connections的关键创新在于其独特的设计,它能够有效地隔离和评估LLM的深思熟虑推理能力。与传统的基准测试不同,NYT-Connections避免了对LLM的直接提示或上下文信息,从而迫使它们独立思考和解决问题。此外,该基准测试还定期更新,以减轻数据泄露的风险,确保评估结果的可靠性。
关键设计:谜题的设计关键在于单词之间的联系并非显而易见,需要参与者进行深入思考才能发现。论文没有提供关于参数设置、损失函数或网络结构的具体细节,因为重点在于基准测试的设计和评估,而不是特定的模型或算法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,即使是GPT-4等先进LLM在NYT-Connections上的表现也远低于人类,差距接近30%。这表明现有LLM在深思熟虑推理方面仍存在显著不足。此外,随着任务难度的增加,诸如思维链和自洽性等高级提示技术的收益递减,进一步强调了开发更强大的推理算法的重要性。
🎯 应用场景
NYT-Connections可用于评估和改进LLM的推理能力,尤其是在需要深思熟虑和抑制直觉的场景中,例如复杂问题求解、决策制定和科学研究。该基准测试可以帮助研究人员开发更可靠、更智能的AI系统,并推动人工智能技术的进步。
📄 摘要(原文)
Large Language Models (LLMs) have shown impressive performance on various benchmarks, yet their ability to engage in deliberate reasoning remains questionable. We present NYT-Connections, a collection of 358 simple word classification puzzles derived from the New York Times Connections game. This benchmark is designed to penalize quick, intuitive "System 1" thinking, isolating fundamental reasoning skills. We evaluated six recent LLMs, a simple machine learning heuristic, and humans across three configurations: single-attempt, multiple attempts without hints, and multiple attempts with contextual hints. Our findings reveal a significant performance gap: even top-performing LLMs like GPT-4 fall short of human performance by nearly 30%. Notably, advanced prompting techniques such as Chain-of-Thought and Self-Consistency show diminishing returns as task difficulty increases. NYT-Connections uniquely combines linguistic isolation, resistance to intuitive shortcuts, and regular updates to mitigate data leakage, offering a novel tool for assessing LLM reasoning capabilities.