The "LLM World of Words" English free association norms generated by large language models
作者: Katherine Abramski, Riccardo Improta, Giulio Rossetti, Massimo Stella
分类: cs.CL, cs.AI
发布日期: 2024-12-02
备注: 16 pages, 11 figures, associated Github page with dataset available at: https://github.com/LLMWorldOfWords/LWOW
💡 一句话要点
构建LLM词语联想规范数据集LWOW,用于研究LLM的知识表征和偏见。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM 自由联想 知识表征 偏见分析 认知网络 语义记忆 数据集构建
📋 核心要点
- 现有研究缺乏大规模LLM生成的自由联想规范,难以与人类数据对比分析LLM的知识表征。
- 论文构建了LLM词语世界(LWOW)数据集,通过提示LLM生成自由联想,模拟人类的SWOW数据集。
- 利用SWOW和LWOW数据集构建认知网络模型,研究人类和LLM的隐性偏见,例如性别刻板印象。
📝 摘要(中文)
自由联想广泛应用于认知心理学和语言学,用于研究概念知识的组织方式。最近,一种类似的方法被用于研究LLM中编码的知识,特别是作为调查LLM偏见的方法。然而,缺乏可与人类生成的规范相比较的大规模LLM生成的自由联想规范,阻碍了这一新的研究方向。为了解决这个限制,我们创建了一个新的LLM生成的自由联想规范数据集,模仿了“词语小世界”(SWOW)人类生成的规范,包含约12,000个提示词。我们使用与SWOW规范中相同的提示词来提示三个LLM,即Mistral、Llama3和Haiku,以生成三个新的可比较的数据集,即“LLM词语世界”(LWOW)。使用SWOW和LWOW规范,我们构建了语义记忆的认知网络模型,代表人类和LLM所拥有的概念知识。我们展示了这些数据集如何用于调查人类和LLM中的隐性偏见,例如社会和LLM输出中普遍存在的有害性别刻板印象。
🔬 方法详解
问题定义:论文旨在解决缺乏大规模LLM自由联想规范数据集的问题,现有方法难以直接对比人类和LLM的知识表征和偏见。现有的人工标注成本高昂,难以扩展到大规模数据集。
核心思路:论文的核心思路是模仿人类的自由联想实验,使用大规模语言模型(LLM)生成自由联想数据,构建一个可与人类数据(SWOW)相比较的LLM词语世界(LWOW)数据集。通过对比分析LLM和人类的自由联想,可以研究LLM的知识表征方式和潜在偏见。
技术框架:整体框架包括以下几个阶段:1) 数据集构建:使用SWOW数据集中的约12,000个提示词,分别提示Mistral、Llama3和Haiku三个LLM,生成对应的自由联想词语。2) 数据处理:对生成的自由联想词语进行清洗和整理,构建LWOW数据集。3) 认知网络模型构建:使用SWOW和LWOW数据集,分别构建人类和LLM的语义记忆认知网络模型。4) 偏见分析:分析认知网络模型,识别人类和LLM中存在的隐性偏见,例如性别刻板印象。
关键创新:最重要的技术创新点在于构建了大规模的LLM自由联想规范数据集(LWOW),该数据集与人类的SWOW数据集具有可比性,为研究LLM的知识表征和偏见提供了新的数据基础。此外,论文还展示了如何利用这些数据集构建认知网络模型,并分析其中的隐性偏见。
关键设计:论文的关键设计包括:1) 提示词的选择:使用与SWOW数据集相同的提示词,保证了LLM生成的数据与人类数据具有可比性。2) LLM的选择:选择了Mistral、Llama3和Haiku三个不同的LLM,以评估不同LLM生成数据的差异。3) 认知网络模型的构建:使用自由联想数据构建语义记忆认知网络模型,可以有效地表示人类和LLM的知识结构。
🖼️ 关键图片

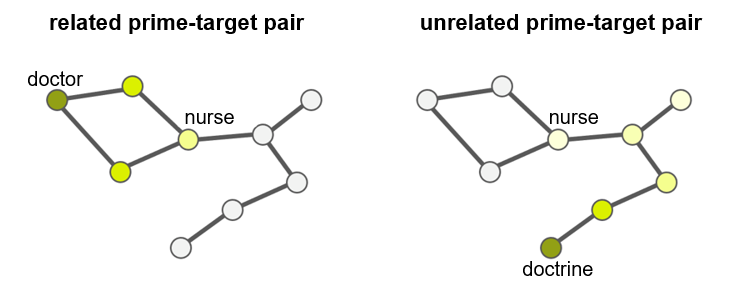
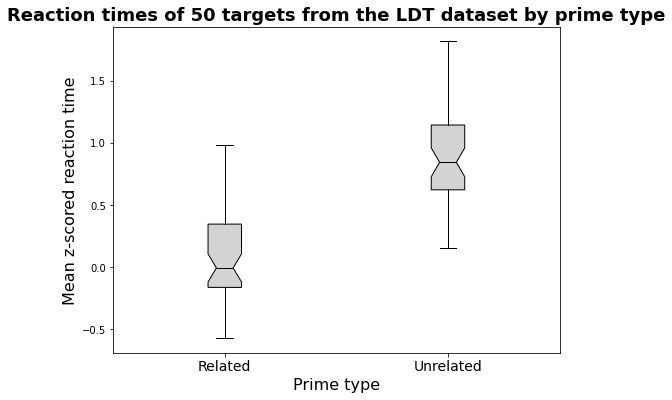
📊 实验亮点
论文构建了包含约12,000个提示词的LWOW数据集,并使用Mistral、Llama3和Haiku三个LLM生成了自由联想。通过对比SWOW和LWOW数据集,发现LLM中存在与人类相似的性别刻板印象。例如,在提示词“doctor”时,LLM更容易联想到男性,而在提示词“nurse”时,更容易联想到女性。
🎯 应用场景
该研究成果可应用于评估和缓解LLM中的偏见,例如性别、种族等。通过分析LLM的自由联想,可以识别其潜在的刻板印象,并采取相应的措施进行纠正。此外,该数据集还可以用于研究LLM的知识表征方式,以及LLM与人类在认知方面的差异。未来,可以进一步扩展该数据集,并将其应用于更广泛的认知科学研究。
📄 摘要(原文)
Free associations have been extensively used in cognitive psychology and linguistics for studying how conceptual knowledge is organized. Recently, the potential of applying a similar approach for investigating the knowledge encoded in LLMs has emerged, specifically as a method for investigating LLM biases. However, the absence of large-scale LLM-generated free association norms that are comparable with human-generated norms is an obstacle to this new research direction. To address this limitation, we create a new dataset of LLM-generated free association norms modeled after the "Small World of Words" (SWOW) human-generated norms consisting of approximately 12,000 cue words. We prompt three LLMs, namely Mistral, Llama3, and Haiku, with the same cues as those in the SWOW norms to generate three novel comparable datasets, the "LLM World of Words" (LWOW). Using both SWOW and LWOW norms, we construct cognitive network models of semantic memory that represent the conceptual knowledge possessed by humans and LLMs. We demonstrate how these datasets can be used for investigating implicit biases in humans and LLMs, such as the harmful gender stereotypes that are prevalent both in society and LLM outputs.