Data Uncertainty-Aware Learning for Multimodal Aspect-based Sentiment Analysis
作者: Hao Yang, Zhenyu Zhang, Yanyan Zhao, Bing Qin
分类: cs.CL
发布日期: 2024-12-02
💡 一句话要点
提出数据不确定性感知学习方法UA-MABSA,提升多模态情感分析在低质量数据上的性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态情感分析 方面级情感分析 数据不确定性 跨模态融合 质量评估 深度学习 注意力机制
📋 核心要点
- 现有MABSA方法忽略了数据集中普遍存在的数据质量差异(即数据不确定性),对所有样本同等对待。
- 提出UA-MABSA模型,通过数据质量和难度对样本损失进行加权,使模型更关注高质量和有挑战性的样本。
- 在Twitter-2015数据集上的实验表明,UA-MABSA达到了SOTA性能,验证了质量评估策略的有效性。
📝 摘要(中文)
多模态面向方面的情感分析(MABSA)是一项细粒度的任务,主要关注于识别文本-图像对中方面级别的情感信息。然而,我们观察到,在低质量样本中识别方面的情感是困难的,例如那些具有低分辨率图像且容易包含噪声的样本。在现实世界中,不同样本的数据质量通常各不相同,这种噪声被称为数据不确定性。但是,先前用于MABSA任务的工作以相同的重要性对待不同质量的样本,而忽略了数据不确定性的影响。在本文中,我们提出了一种新的数据不确定性感知多模态面向方面的情感分析方法UA-MABSA,该方法通过数据质量和难度来加权不同样本的损失。UA-MABSA采用了一种新颖的质量评估策略,该策略同时考虑了图像质量和基于方面的跨模态相关性,从而使模型能够更加关注高质量和具有挑战性的样本。大量的实验表明,我们的方法在Twitter-2015数据集上实现了最先进(SOTA)的性能。进一步的分析证明了质量评估策略的有效性。
🔬 方法详解
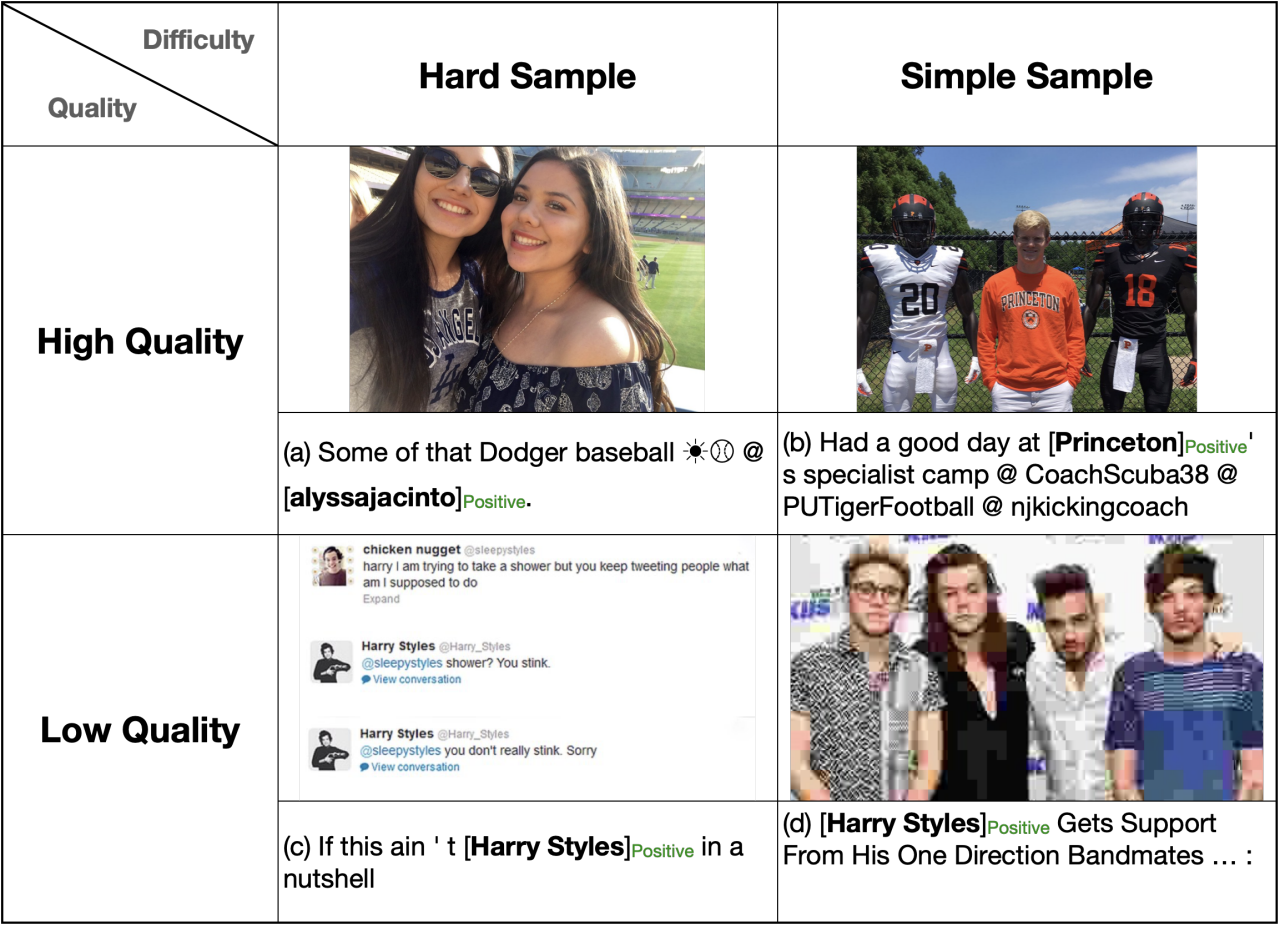
问题定义:MABSA任务旨在识别文本-图像对中特定方面的情感极性。现有方法忽略了数据集中样本质量的差异,即数据不确定性,对所有样本采用相同的学习策略,导致模型在低质量样本上的性能下降。低质量样本可能包含噪声,例如低分辨率图像或与方面无关的图像,从而影响情感判断的准确性。
核心思路:UA-MABSA的核心思路是引入数据不确定性感知机制,根据样本的质量和难度动态调整其在训练过程中的权重。通过质量评估策略,模型能够识别高质量和具有挑战性的样本,并给予更高的关注,从而提高整体性能。这种方法类似于人类学习过程,即更专注于学习高质量和有难度的知识。
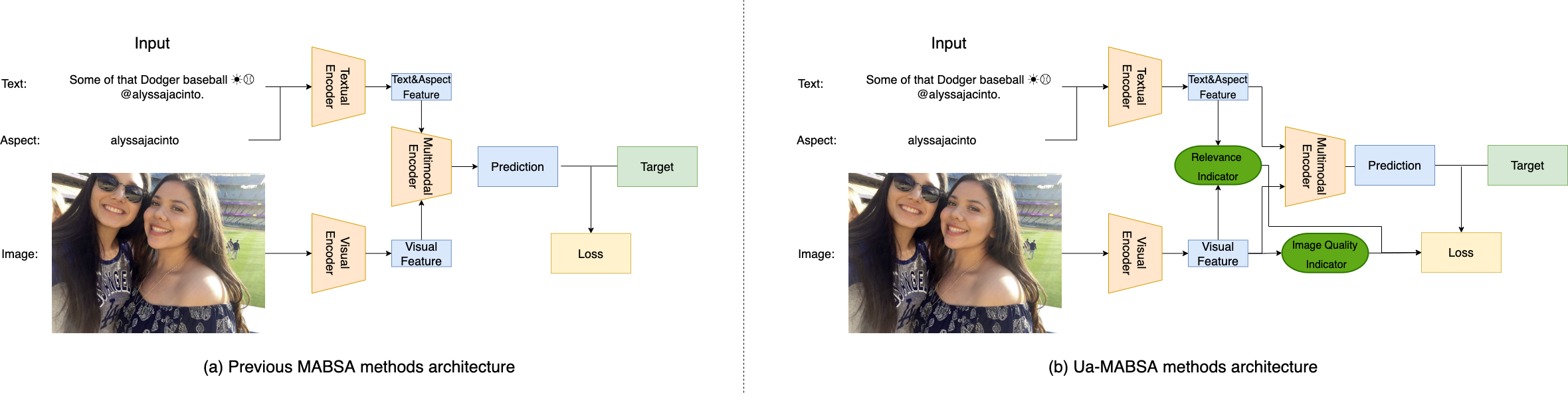
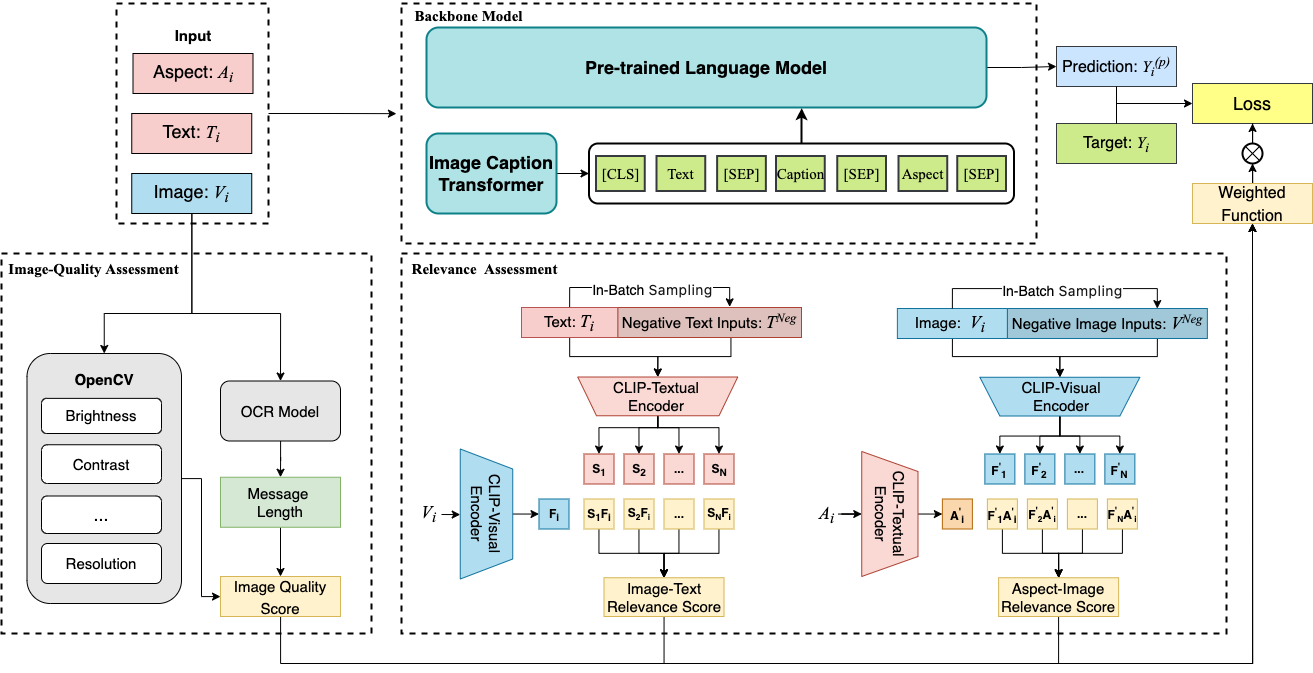
技术框架:UA-MABSA的整体框架包含以下几个主要模块:1) 特征提取模块:用于提取文本和图像的特征表示。2) 跨模态融合模块:用于融合文本和图像特征,捕捉跨模态信息。3) 质量评估模块:用于评估样本的质量,包括图像质量和方面相关的跨模态相关性。4) 情感分类模块:用于预测给定方面的情感极性。5) 损失加权模块:根据样本质量和难度,对损失函数进行加权。
关键创新:UA-MABSA的关键创新在于提出了数据不确定性感知的学习策略,并设计了一种新颖的质量评估方法。与现有方法不同,UA-MABSA能够根据样本质量动态调整其在训练过程中的权重,从而使模型更关注高质量和具有挑战性的样本。这种方法能够有效提高模型在低质量数据上的鲁棒性,并提升整体性能。
关键设计:质量评估模块是UA-MABSA的关键组成部分。该模块同时考虑了图像质量和方面相关的跨模态相关性。图像质量可以通过现有的图像质量评估算法进行评估。方面相关的跨模态相关性可以通过计算方面词的文本特征与图像特征之间的相似度来衡量。损失加权模块根据样本质量和难度,对交叉熵损失函数进行加权。高质量和具有挑战性的样本具有更高的权重,而低质量的样本具有较低的权重。具体的权重计算公式未知,需要在实验中进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,UA-MABSA在Twitter-2015数据集上取得了SOTA性能,显著优于现有的MABSA方法。具体提升幅度未知,但论文强调了质量评估策略的有效性。实验分析表明,UA-MABSA能够有效识别高质量和具有挑战性的样本,并给予更高的关注,从而提高整体性能。
🎯 应用场景
该研究成果可应用于各种需要处理多模态数据的情感分析场景,例如社交媒体情感监控、产品评论分析、舆情分析等。通过考虑数据质量,可以提高情感分析系统在真实世界复杂数据上的准确性和鲁棒性。未来,该方法可以扩展到其他多模态任务,例如图像描述生成、视频理解等。
📄 摘要(原文)
As a fine-grained task, multimodal aspect-based sentiment analysis (MABSA) mainly focuses on identifying aspect-level sentiment information in the text-image pair. However, we observe that it is difficult to recognize the sentiment of aspects in low-quality samples, such as those with low-resolution images that tend to contain noise. And in the real world, the quality of data usually varies for different samples, such noise is called data uncertainty. But previous works for the MABSA task treat different quality samples with the same importance and ignored the influence of data uncertainty. In this paper, we propose a novel data uncertainty-aware multimodal aspect-based sentiment analysis approach, UA-MABSA, which weighted the loss of different samples by the data quality and difficulty. UA-MABSA adopts a novel quality assessment strategy that takes into account both the image quality and the aspect-based cross-modal relevance, thus enabling the model to pay more attention to high-quality and challenging samples. Extensive experiments show that our method achieves state-of-the-art (SOTA) performance on the Twitter-2015 dataset. Further analysis demonstrates the effectiveness of the quality assessment strategy.