Berezinskii--Kosterlitz--Thouless transition in a context-sensitive random language model
作者: Yuma Toji, Jun Takahashi, Vwani Roychowdhury, Hideyuki Miyahara
分类: stat.ML, cond-mat.stat-mech, cs.CL, cs.LG
发布日期: 2024-12-02 (更新: 2026-01-11)
备注: accepted for publication in PRE
💡 一句话要点
构建上下文相关的随机语言模型,揭示自然语言中的BKT相变现象
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自然语言模型 相变 BKT相变 上下文相关文法 统计物理 临界现象 生成模型
📋 核心要点
- 自然语言中存在多种幂律临界性质,类似于物理系统在相变点或附近的标度性质,但缺乏能展示相变的生成语言模型。
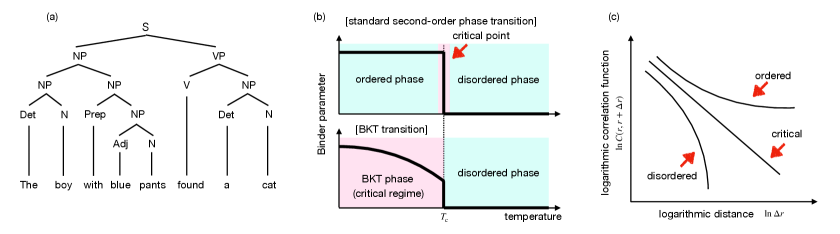
- 受一维Potts模型启发,论文构建上下文相关的随机语言模型,通过调整模型参数,观察序参量的变化来研究相变。
- 数值实验表明,该模型存在明确的相变,并且该相变是BKT相变的一种变体,为理解自然语言的临界性质提供了新视角。
📝 摘要(中文)
本文构建了一种简单的概率语言模型,属于上下文相关文法,称为上下文相关的随机语言模型。该模型受到统计物理学中一维Potts模型的启发。数值结果表明,该模型在自然语言模型的框架下表现出明确的相变。通过精确定义的序参量,捕捉语言模型生成句子中的符号频率偏差,证明了当调整随机语言模型的参数时,该序参量从严格的零值变为严格的非零值(在句子的无限长度极限下),这意味着数学上的奇点。此外,该相变被确定为Berezinskii--Kosterlitz--Thouless (BKT)相变的一种变体,该相变不仅在转变点,而且在整个相中都表现出临界性质。这一发现表明,自然语言中的临界性质可能不需要精细的微调或自组织临界性,而是可以通过语言结构与BKT相之间的潜在联系来解释。
🔬 方法详解
问题定义:论文旨在解决自然语言模型中相变现象的缺失问题。尽管大型语言模型展现出与物理学概念(如标度律和涌现能力)的相似性,但缺乏具体的生成语言模型实例,能够像统计物理学那样展示明确的相变。现有方法难以解释自然语言中观察到的临界性质,以及这些性质与底层语言结构的关系。
核心思路:核心思路是借鉴统计物理学中的一维Potts模型,构建一个上下文相关的随机语言模型,该模型能够通过调整参数来模拟相变。通过定义一个序参量来量化模型生成句子中的符号频率偏差,并观察该序参量随参数变化的规律,从而确定是否存在相变。
技术框架:该模型属于上下文相关文法,其生成过程可以看作是一个马尔可夫过程。模型的核心参数控制了不同符号之间的转移概率,通过调整这些参数,可以改变模型生成句子的统计特性。整个流程包括:1) 定义上下文相关的文法规则;2) 根据文法规则和转移概率生成句子;3) 计算序参量,量化符号频率偏差;4) 分析序参量随参数变化的规律,确定是否存在相变。
关键创新:最重要的创新在于将统计物理学中的相变概念引入到自然语言模型中,并构建了一个能够展示BKT相变的具体语言模型。与以往研究不同,该工作强调了语言结构与BKT相之间的潜在联系,为理解自然语言的临界性质提供了一种新的解释框架。
关键设计:模型的关键设计包括:1) 上下文相关文法的具体规则,这些规则决定了模型能够生成的句子的结构;2) 转移概率的设置,这些概率控制了不同符号之间的转移频率,从而影响了生成句子的统计特性;3) 序参量的定义,该序参量需要能够有效地量化符号频率偏差,从而反映模型的相变行为。
🖼️ 关键图片

📊 实验亮点
论文通过数值实验明确展示了上下文相关的随机语言模型中的相变现象。通过调整模型参数,观察到序参量从严格的零值变为严格的非零值,表明存在数学上的奇点。进一步分析表明,该相变是BKT相变的一种变体,这意味着自然语言中的临界性质可能不需要精细的微调或自组织临界性。
🎯 应用场景
该研究成果可应用于自然语言处理领域,例如,可以帮助我们更好地理解语言的结构和演化规律,设计更有效的语言模型。此外,该研究也可能对其他领域产生影响,例如,可以借鉴该模型的设计思想,构建具有复杂行为的生成模型,用于模拟其他复杂系统。
📄 摘要(原文)
Several power-law critical properties involving different statistics in natural languages -- reminiscent of scaling properties of physical systems at or near phase transitions -- have been documented for decades. The recent rise of large language models has added further evidence and excitement by providing intriguing similarities with notions in physics such as scaling laws and emergent abilities. However, specific instances of classes of generative language models that exhibit phase transitions, as understood by the statistical physics community, are lacking. In this work, inspired by the one-dimensional Potts model in statistical physics, we construct a simple probabilistic language model that falls under the class of context-sensitive grammars, which we call the context-sensitive random language model, and numerically demonstrate an unambiguous phase transition in the framework of a natural language model. We explicitly show that a precisely defined order parameter -- that captures symbol frequency biases in the sentences generated by the language model -- changes from strictly zero to a strictly nonzero value (in the infinite-length limit of sentences), implying a mathematical singularity arising when tuning the parameter of the stochastic language model we consider. Furthermore, we identify the phase transition as a variant of the Berezinskii--Kosterlitz--Thouless (BKT) transition, which is known to exhibit critical properties not only at the transition point but also in the entire phase. This finding leads to the possibility that critical properties in natural languages may not require careful fine-tuning nor self-organized criticality, but are generically explained by the underlying connection between language structures and the BKT phases.