Automated Extraction of Acronym-Expansion Pairs from Scientific Papers
作者: Izhar Ali, Million Haileyesus, Serhiy Hnatyshyn, Jan-Lucas Ott, Vasil Hnatyshin
分类: cs.CL, cs.IR
发布日期: 2024-12-02
备注: 9 pages, 1 figure
💡 一句话要点
提出一种结合正则表达式和大型语言模型的自动化学术论文缩略语-全称对提取方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 缩略语提取 全称识别 正则表达式 大型语言模型 GPT-4 自然语言处理 文本挖掘
📋 核心要点
- 现有方法难以有效处理学术论文中普遍存在的多义、非局部和模糊缩略语,导致自然语言处理精度下降。
- 该方法结合文档预处理、正则表达式和GPT-4,先用正则表达式识别缩略语,再用GPT-4分析上下文提取全称,提升准确性。
- 实验结果表明,单独使用正则表达式或GPT-4效果不佳,结合使用能更准确地识别和提取缩略语-全称对。
📝 摘要(中文)
本项目旨在解决数字文本中广泛使用缩写和首字母缩略词所带来的挑战。我们提出了一种新颖的方法,该方法结合了文档预处理、正则表达式和大型语言模型,以识别缩写并将它们映射到相应的全称。当正则表达式不足以提取全称时,我们的方法会利用 GPT-4 分析缩略词周围的文本。通过将分析限制在周围文本的一小部分,我们降低了为缩略词获得不正确或多个全称的风险。处理带有缩略词的文本存在若干已知挑战,包括多义缩略词、非局部和模糊缩略词。我们的方法通过自动缩略词识别和消除歧义来提高 NLP 技术的精度和效率。这项研究强调了处理 PDF 文件的挑战以及文档预处理的重要性。此外,这项工作的结果表明,单独使用正则表达式或 GPT-4 都无法表现良好。正则表达式适用于识别缩略词,但由于用于表达缩略词-全称对的各种格式以及作者倾向于省略文本中的全称,因此在论文中查找其全称方面存在局限性。另一方面,GPT-4 是获得全称的绝佳工具,但在正确识别所有相关缩略词方面存在困难。此外,GPT-4 由于其概率性质而带来挑战,这可能导致相同输入的结果略有不同。我们的算法采用预处理来消除文本中的无关信息,使用正则表达式来识别缩略词,并使用大型语言模型来帮助查找缩略词全称,从而提供最准确和一致的结果。
🔬 方法详解
问题定义:论文旨在解决学术论文中缩略语和全称对应关系自动提取的问题。现有方法,如单纯依赖正则表达式,难以处理缩略语表达形式多样、全称缺失等情况。而直接使用大型语言模型,则面临识别不准确、结果不一致等挑战。这些问题降低了自然语言处理的效率和准确性。
核心思路:论文的核心思路是结合正则表达式的精确性和大型语言模型的理解能力,构建一个混合系统。正则表达式负责快速定位潜在的缩略语,而大型语言模型则负责在有限的上下文中寻找或生成对应的全称。这种分工合作旨在克服各自的局限性,提高整体的准确性和鲁棒性。
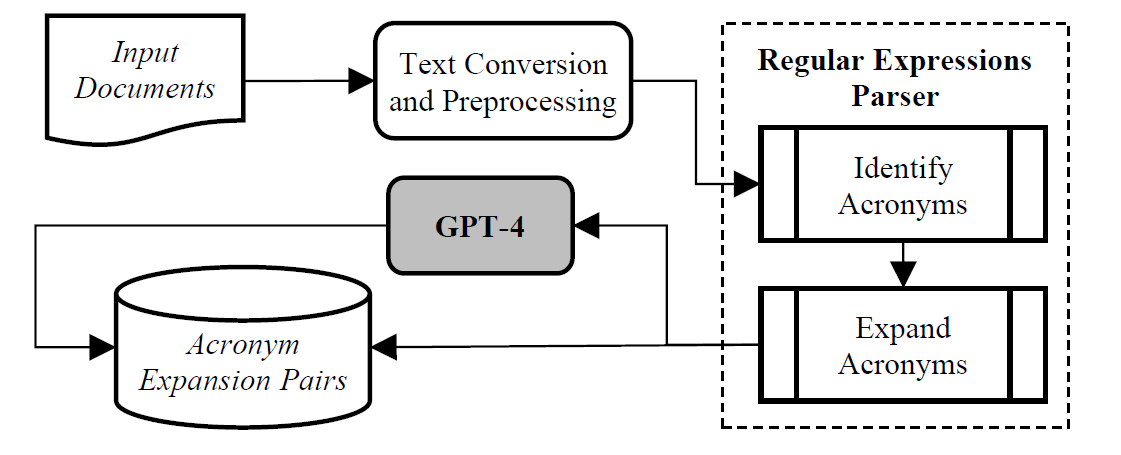
技术框架:该方法的技术框架包含以下几个主要阶段:1) 文档预处理:清洗PDF文档,去除无关信息,为后续处理做准备。2) 缩略语识别:使用正则表达式在文本中识别潜在的缩略语。3) 全称提取:对于每个识别出的缩略语,利用GPT-4分析其周围的文本片段,提取或生成对应的全称。4) 结果验证与输出:对提取的全称进行验证,去除歧义或错误匹配,最终输出缩略语-全称对。
关键创新:该方法最重要的创新点在于将正则表达式和大型语言模型有机结合。正则表达式负责快速定位,大型语言模型负责语义理解和生成。通过限制大型语言模型分析的文本范围,降低了其出错的概率,提高了效率。这种混合方法充分利用了两种技术的优势,克服了各自的不足。
关键设计:在全称提取阶段,一个关键设计是限制GPT-4分析的上下文窗口大小。通过实验确定最佳窗口大小,既能包含足够的信息,又能避免引入噪声。此外,论文可能还涉及一些Prompt工程的设计,以引导GPT-4更准确地生成全称。具体的损失函数和网络结构取决于GPT-4的内部实现,论文可能没有详细描述。
🖼️ 关键图片
📊 实验亮点
论文强调了单独使用正则表达式或GPT-4的局限性,并展示了结合使用二者的优势。虽然没有提供具体的性能数据,但摘要指出该方法能够提高NLP技术的精度和效率,并能更准确、一致地提取缩略语-全称对。该研究突出了文档预处理的重要性,并为未来研究提供了有价值的思路。
🎯 应用场景
该研究成果可应用于信息检索、知识图谱构建、医学文本挖掘等领域。自动提取缩略语-全称对能够提升文本理解的准确性和效率,有助于构建更完善的领域知识库,并为下游任务提供更好的支持。未来,该技术可进一步应用于处理更复杂的文本类型,例如专利文献、法律文书等。
📄 摘要(原文)
This project addresses challenges posed by the widespread use of abbreviations and acronyms in digital texts. We propose a novel method that combines document preprocessing, regular expressions, and a large language model to identify abbreviations and map them to their corresponding expansions. The regular expressions alone are often insufficient to extract expansions, at which point our approach leverages GPT-4 to analyze the text surrounding the acronyms. By limiting the analysis to only a small portion of the surrounding text, we mitigate the risk of obtaining incorrect or multiple expansions for an acronym. There are several known challenges in processing text with acronyms, including polysemous acronyms, non-local and ambiguous acronyms. Our approach enhances the precision and efficiency of NLP techniques by addressing these issues with automated acronym identification and disambiguation. This study highlights the challenges of working with PDF files and the importance of document preprocessing. Furthermore, the results of this work show that neither regular expressions nor GPT-4 alone can perform well. Regular expressions are suitable for identifying acronyms but have limitations in finding their expansions within the paper due to a variety of formats used for expressing acronym-expansion pairs and the tendency of authors to omit expansions within the text. GPT-4, on the other hand, is an excellent tool for obtaining expansions but struggles with correctly identifying all relevant acronyms. Additionally, GPT-4 poses challenges due to its probabilistic nature, which may lead to slightly different results for the same input. Our algorithm employs preprocessing to eliminate irrelevant information from the text, regular expressions for identifying acronyms, and a large language model to help find acronym expansions to provide the most accurate and consistent results.