Unveiling Performance Challenges of Large Language Models in Low-Resource Healthcare: A Demographic Fairness Perspective
作者: Yue Zhou, Barbara Di Eugenio, Lu Cheng
分类: cs.CL, cs.AI
发布日期: 2024-11-30 (更新: 2024-12-07)
备注: Accepted to the main conference of COLING 2025
💡 一句话要点
揭示大语言模型在低资源医疗场景中的性能挑战与人口公平性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 医疗保健 公平性 低资源 人口统计偏见
📋 核心要点
- 现有大语言模型在低资源医疗场景中应用面临性能瓶颈,且在不同人口群体中存在公平性问题。
- 论文通过实验分析,揭示了直接应用LLM解决医疗任务的局限性,并探究了人口信息对模型预测的影响。
- 实验表明,即使赋予LLM访问最新指南的能力,也难以保证其在医疗任务上的性能提升,公平性问题依然存在。
📝 摘要(中文)
本文研究了大型语言模型(LLMs)在解决真实医疗任务中的性能,特别关注人口公平性。我们评估了最先进的LLMs在六个不同的医疗任务中,使用三种流行的学习框架,发现将LLMs应用于真实医疗任务存在重大挑战,并且在不同人口群体中存在持续的公平性问题。我们还发现,显式提供人口统计信息会产生好坏参半的结果,而LLM推断此类细节的能力引发了对有偏见的健康预测的担忧。将LLMs用作可以访问最新指南的自主代理并不能保证性能的提高。我们认为这些发现揭示了LLMs在医疗公平性方面的关键局限性,以及该领域迫切需要专门研究。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在低资源医疗保健领域应用时面临的性能挑战,特别是关于人口统计公平性的问题。现有方法直接将通用LLMs应用于医疗任务,忽略了医疗领域的特殊性和数据稀缺性,导致模型性能不佳,且可能产生对特定人口群体有偏见的预测。
核心思路:论文的核心思路是通过实验评估不同LLMs在多个医疗任务上的表现,并分析其在不同人口群体中的公平性。通过控制变量,例如是否显式提供人口统计信息,来探究LLMs的偏见来源和影响。此外,还尝试将LLMs作为自主代理,赋予其访问最新医疗指南的能力,以期提高性能和公平性。
技术框架:论文采用实验驱动的研究方法,主要包含以下几个阶段:1) 选择多个具有代表性的医疗任务;2) 选择最先进的LLMs作为评估对象;3) 设计不同的学习框架,例如直接预测、微调等;4) 评估LLMs在不同任务和人口群体上的性能和公平性;5) 分析实验结果,揭示LLMs的局限性和潜在偏见。
关键创新:论文的主要创新在于:1) 系统性地评估了LLMs在低资源医疗场景中的性能和公平性;2) 揭示了LLMs在医疗领域应用中存在的偏见问题,并探究了其来源;3) 验证了将LLMs作为自主代理并不能有效解决性能和公平性问题。
关键设计:论文的关键设计包括:1) 选择了六个不同的医疗任务,涵盖了不同的医疗领域和任务类型;2) 选择了多个最先进的LLMs,包括不同规模和架构的模型;3) 采用了多种评估指标,包括准确率、召回率、F1值等,以及公平性指标,例如差异影响(Disparate Impact)和平均机会差异(Average Odds Difference);4) 通过控制变量,例如是否显式提供人口统计信息,来探究LLMs的偏见来源和影响。
🖼️ 关键图片

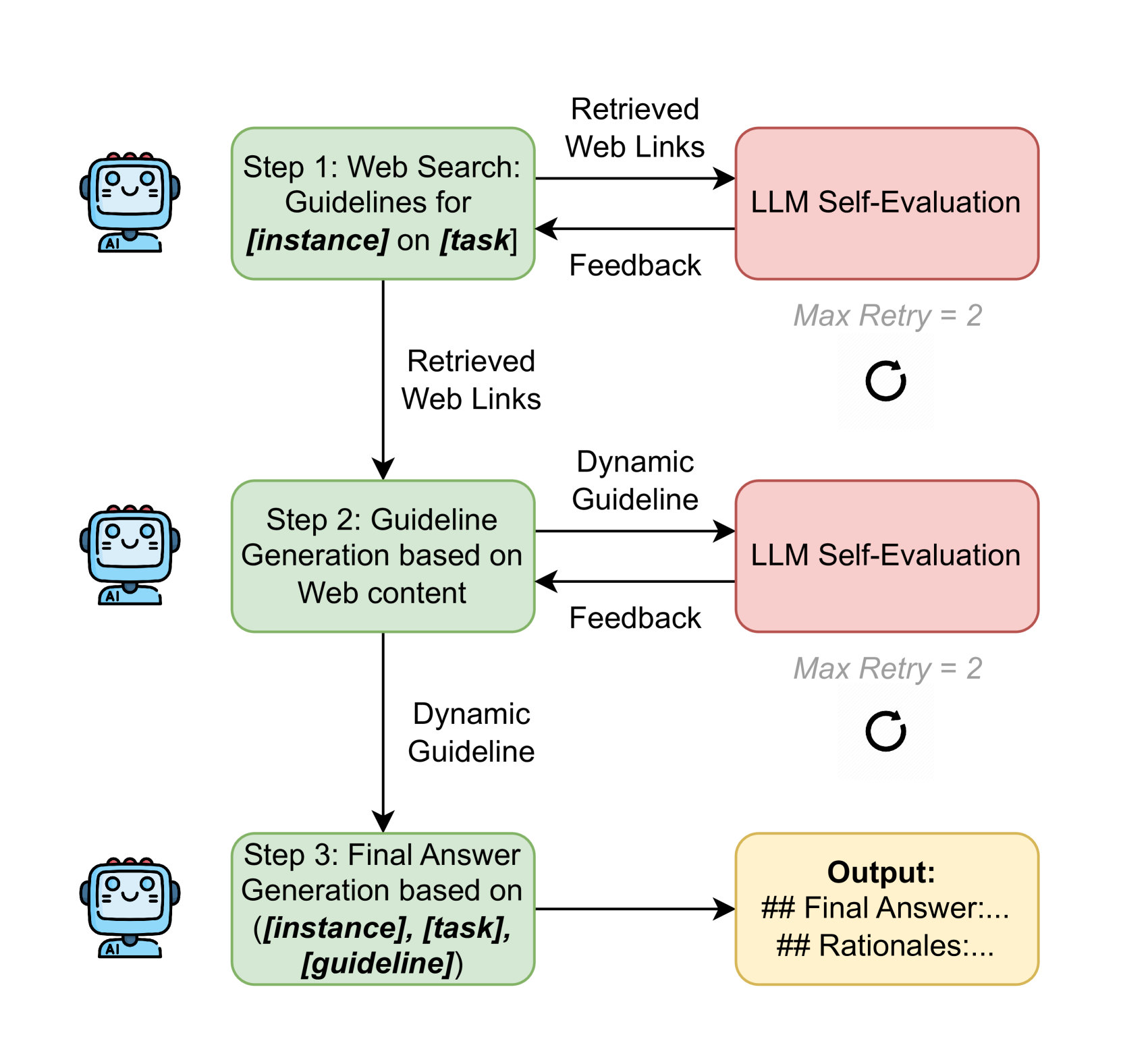

📊 实验亮点
实验结果表明,LLMs在低资源医疗场景中面临显著的性能挑战,且在不同人口群体中存在持续的公平性问题。显式提供人口统计信息对模型性能的影响不一致,而LLM推断此类信息的能力引发了对有偏见的健康预测的担忧。即使赋予LLM访问最新指南的能力,也难以保证性能的提高。
🎯 应用场景
该研究成果可应用于指导LLMs在医疗领域的安全和公平部署。通过了解LLMs的局限性和潜在偏见,可以开发更有效的算法和干预措施,以提高LLMs在医疗诊断、治疗建议和患者支持等方面的性能和公平性。此外,该研究还可以促进医疗领域对AI伦理和公平性的关注,推动相关政策的制定。
📄 摘要(原文)
This paper studies the performance of large language models (LLMs), particularly regarding demographic fairness, in solving real-world healthcare tasks. We evaluate state-of-the-art LLMs with three prevalent learning frameworks across six diverse healthcare tasks and find significant challenges in applying LLMs to real-world healthcare tasks and persistent fairness issues across demographic groups. We also find that explicitly providing demographic information yields mixed results, while LLM's ability to infer such details raises concerns about biased health predictions. Utilizing LLMs as autonomous agents with access to up-to-date guidelines does not guarantee performance improvement. We believe these findings reveal the critical limitations of LLMs in healthcare fairness and the urgent need for specialized research in this area.