Evaluating the Consistency of LLM Evaluators
作者: Noah Lee, Jiwoo Hong, James Thorne
分类: cs.CL
发布日期: 2024-11-30
备注: Accepted to COLING 2025
💡 一句话要点
评估LLM评估器的一致性:揭示强大模型未必可靠的评估能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM评估器 一致性评估 自洽性 跨尺度一致性 自动评估 模型评估 可靠性
📋 核心要点
- 现有研究主要关注LLM评估器与人类标注的相关性,忽略了其自身评估结果的一致性,这对其可靠性构成挑战。
- 该论文通过研究LLM评估器的自洽性(SC)和跨尺度一致性(IC),来评估其作为评估者的一致性。
- 实验结果表明,即使是强大的专有LLM,也可能不具备良好的一致性,强调了评估LLM评估器一致性的必要性。
📝 摘要(中文)
大型语言模型(LLM)作为通用评估器展现出潜力,其速度和成本优势显而易见。虽然它们与人类标注者之间的相关性已被广泛研究,但作为评估者的一致性仍未得到充分研究,这引发了对LLM评估器可靠性的担忧。在本文中,我们对LLM评估的两个一致性方面进行了广泛研究,即自洽性(SC)和跨尺度一致性(IC),针对不同的评分尺度和标准粒度,使用了开源和专有模型。我们的综合分析表明,强大的专有模型不一定是始终如一的评估器,突显了在评估LLM评估器的能力时考虑一致性的重要性。
🔬 方法详解
问题定义:论文旨在解决LLM作为评估器时,其评估结果一致性不足的问题。现有研究主要关注LLM与人类标注的相关性,忽略了LLM自身评估结果在不同情境下是否一致。这种一致性缺失会影响LLM评估结果的可靠性,限制其在实际应用中的价值。
核心思路:论文的核心思路是通过量化LLM评估器的自洽性(Self-Consistency, SC)和跨尺度一致性(Inter-scale Consistency, IC)来评估其一致性。自洽性衡量的是LLM在相同输入下,多次评估结果的一致程度;跨尺度一致性衡量的是LLM在不同评分尺度或标准粒度下,评估结果的一致程度。
技术框架:论文的技术框架主要包括以下几个步骤:1) 选择不同的LLM作为评估器,包括开源模型和专有模型;2) 设计不同的评估任务和数据集,涵盖不同的评分尺度和标准粒度;3) 使用相同的输入,多次运行LLM评估器,记录其评估结果;4) 计算LLM评估器的自洽性和跨尺度一致性指标;5) 分析不同LLM评估器的一致性表现,并进行比较。
关键创新:论文的关键创新在于提出了自洽性和跨尺度一致性这两个指标来量化LLM评估器的一致性。以往研究主要关注LLM与人类标注的相关性,而忽略了LLM自身评估结果的一致性。通过引入这两个指标,可以更全面地评估LLM作为评估器的能力。
关键设计:论文的关键设计包括:1) 选择具有代表性的开源和专有LLM,以覆盖不同类型的模型;2) 设计多样化的评估任务和数据集,以涵盖不同的应用场景;3) 使用多种一致性指标,以全面评估LLM评估器的一致性;4) 对实验结果进行深入分析,以揭示不同因素对LLM评估器一致性的影响。
🖼️ 关键图片
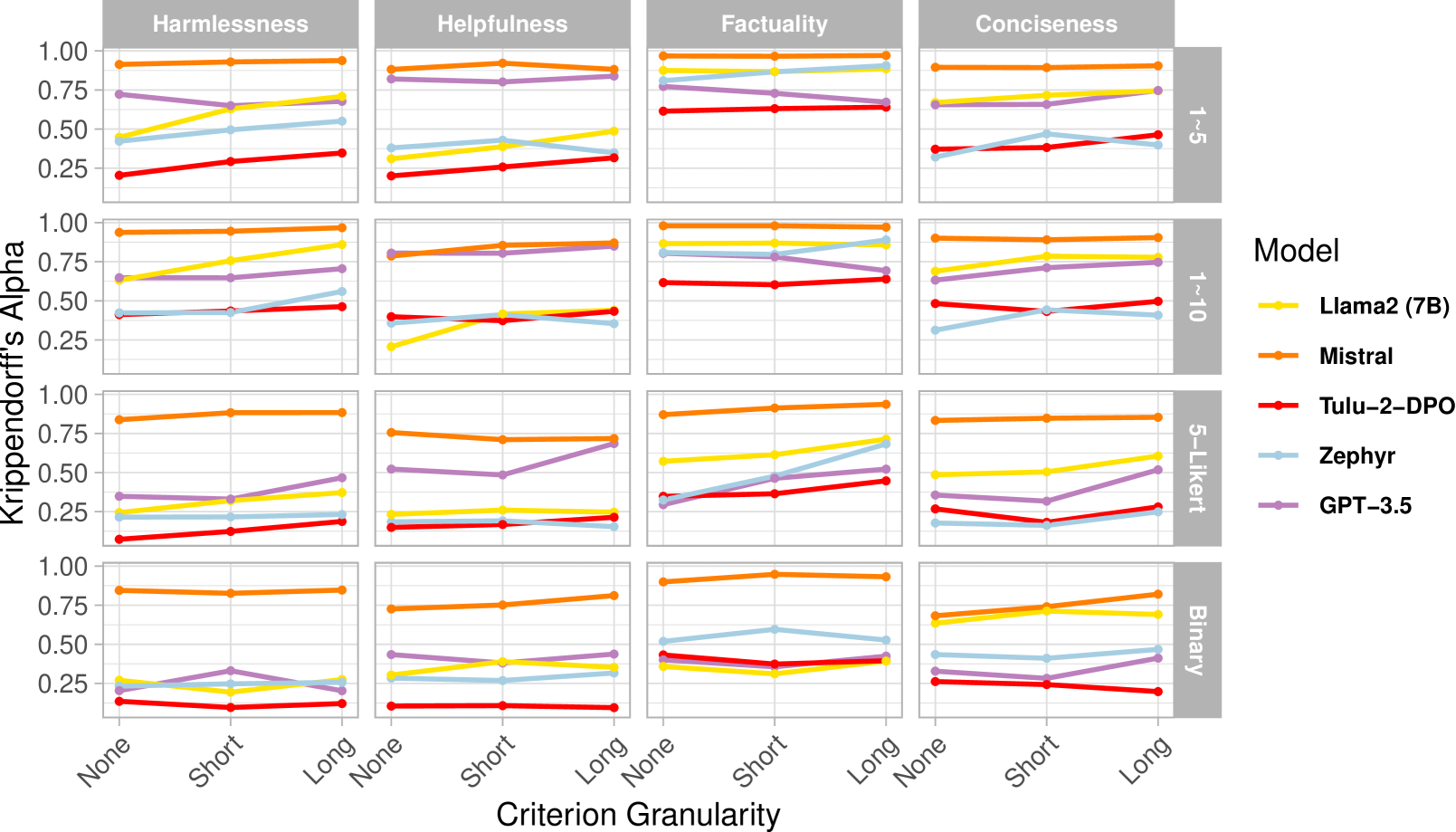


📊 实验亮点
实验结果表明,即使是强大的专有LLM,在自洽性和跨尺度一致性方面也可能表现不佳。例如,某些专有模型在细粒度评分标准下的一致性明显低于粗粒度评分标准。这些发现强调了在评估LLM评估器能力时,不能仅仅关注其与人类标注的相关性,而需要综合考虑其一致性。
🎯 应用场景
该研究成果可应用于自动评估、模型选择和质量控制等领域。通过评估LLM评估器的一致性,可以选择更可靠的LLM进行自动评估,提高模型选择的准确性,并改进质量控制流程。未来,该研究可以扩展到更复杂的评估任务和更多类型的LLM,推动LLM在评估领域的应用。
📄 摘要(原文)
Large language models (LLMs) have shown potential as general evaluators along with the evident benefits of speed and cost. While their correlation against human annotators has been widely studied, consistency as evaluators is still understudied, raising concerns about the reliability of LLM evaluators. In this paper, we conduct extensive studies on the two aspects of consistency in LLM evaluations, Self-Consistency (SC) and Inter-scale Consistency (IC), on different scoring scales and criterion granularity with open-source and proprietary models. Our comprehensive analysis demonstrates that strong proprietary models are not necessarily consistent evaluators, highlighting the importance of considering consistency in assessing the capability of LLM evaluators.