BatchLLM: Optimizing Large Batched LLM Inference with Global Prefix Sharing and Throughput-oriented Token Batching
作者: Zhen Zheng, Xin Ji, Taosong Fang, Fanghao Zhou, Chuanjie Liu, Gang Peng
分类: cs.CL, cs.AI, cs.DC, cs.LG
发布日期: 2024-11-29 (更新: 2025-01-17)
💡 一句话要点
BatchLLM:通过全局前缀共享和吞吐量导向的Token Batching优化大规模批量LLM推理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 批量推理 前缀共享 吞吐量优化 Token Batching
📋 核心要点
- 现有LLM推理引擎在处理具有前缀共享特性的大批量任务时存在局限性,无法充分利用共享前缀的KV上下文,导致GPU利用率不足。
- BatchLLM通过显式识别全局公共前缀,并调度共享相同前缀的请求,最大化KV上下文的重用,从而优化批量推理。
- 实验结果表明,BatchLLM在不同硬件环境下,相比vLLM和SGLang,在一系列测试中性能提升了1.3倍到10.8倍。
📝 摘要(中文)
大型语言模型(LLM)在各种信息处理和管理任务中扮演着越来越重要的角色。许多此类任务以大批量甚至离线方式执行,其性能指标是吞吐量。这些任务通常表现出前缀共享的特性,即不同的提示输入可以部分显示公共前缀。然而,现有的LLM推理引擎倾向于优化流式请求,并且在支持具有前缀共享特性的大批量任务方面存在局限性。现有的解决方案使用基于LRU的缓存来重用请求之间公共前缀的KV上下文。由于隐式的缓存管理,即将被重用的KV上下文可能会过早地被驱逐。此外,面向流的系统没有利用请求批次信息,并且无法最好地将解码token与预填充块混合以用于批量场景,因此无法使GPU饱和。我们提出了BatchLLM来解决上述问题。BatchLLM显式地全局识别公共前缀。共享相同前缀的请求将被一起调度,以最大程度地重用KV上下文。BatchLLM重新排序请求,并优先调度解码比例较大的请求,以便更好地将解码token与后面的预填充块混合,并应用以内存为中心的token batching来扩大token批次大小,这有助于提高GPU利用率。最后,BatchLLM通过水平融合优化了前缀共享的Attention内核,以减少尾部效应和内核启动开销。广泛的评估表明,在不同的硬件环境下,在一组微基准测试和一个典型的行业工作负载上,BatchLLM的性能优于vLLM和SGLang,提升幅度为1.3倍至10.8倍。
🔬 方法详解
问题定义:论文旨在解决大规模批量LLM推理中,由于请求间存在前缀共享,而现有推理引擎无法有效利用这些共享信息,导致吞吐量受限的问题。现有方法,如vLLM和SGLang,主要面向流式请求优化,对批量任务支持不足,且基于LRU的缓存机制可能导致有用的KV上下文过早被驱逐。
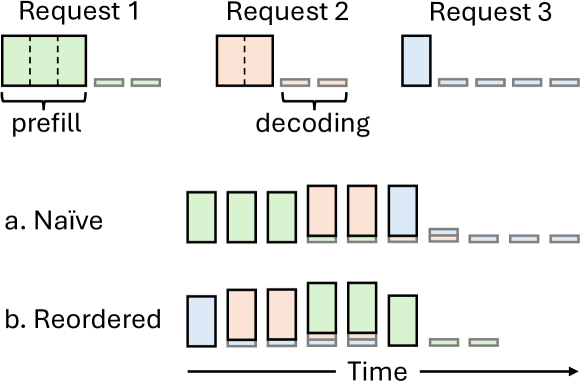
核心思路:BatchLLM的核心思路是显式地识别和利用请求之间的公共前缀,通过全局前缀共享和吞吐量导向的token batching,最大化KV上下文的重用和GPU的利用率。通过重新排序请求,优先处理解码比例大的请求,更好地混合解码token和预填充块,从而提高整体吞吐量。
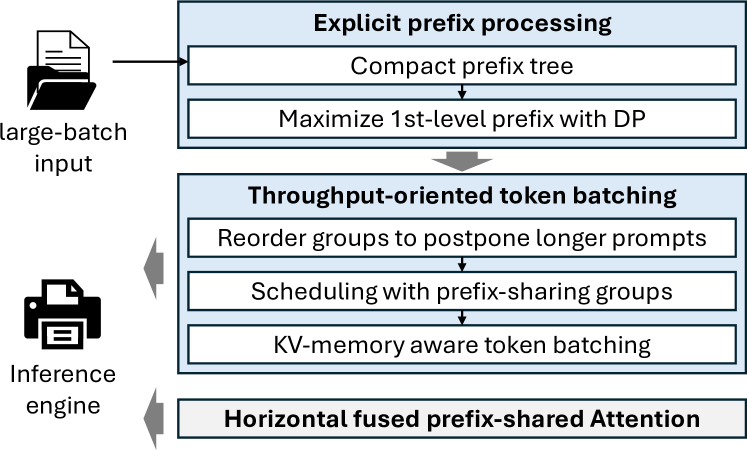
技术框架:BatchLLM的整体框架包括以下几个主要模块:1) 全局前缀识别模块,用于显式地识别请求之间的公共前缀。2) 请求调度模块,根据前缀共享情况和解码比例对请求进行重新排序和调度。3) 内存中心Token Batching模块,用于扩大Token批次大小,提高GPU利用率。4) 优化后的前缀共享Attention内核,通过水平融合减少尾部效应和内核启动开销。
关键创新:BatchLLM的关键创新在于:1) 显式全局前缀共享机制,避免了LRU缓存的局限性。2) 吞吐量导向的请求调度策略,优化了解码token和预填充块的混合。3) 内存中心Token Batching,有效增大了Token批次大小。4) 优化的前缀共享Attention内核,降低了计算开销。
关键设计:BatchLLM的关键设计包括:1) 前缀树结构,用于高效地识别和管理全局公共前缀。2) 基于解码比例的优先级调度算法,优先处理解码比例大的请求。3) 自适应Token Batching策略,根据GPU内存和请求特征动态调整Token批次大小。4) 水平融合Attention内核,通过合并相邻的Attention计算,减少内核启动开销。
🖼️ 关键图片
📊 实验亮点
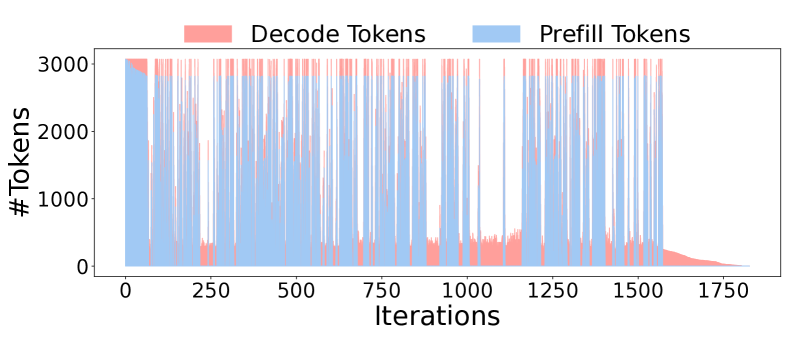
BatchLLM在多个基准测试和实际工业工作负载中均表现出显著的性能提升。在不同的硬件环境下,BatchLLM相比vLLM和SGLang,性能提升了1.3倍到10.8倍。这些结果表明,BatchLLM在优化大规模批量LLM推理方面具有显著优势。
🎯 应用场景
BatchLLM适用于需要大规模批量处理LLM请求的场景,例如离线文档分析、批量文本生成、大规模知识库问答等。该研究可以显著提高LLM推理的吞吐量,降低成本,并为更广泛的LLM应用提供支持。未来,BatchLLM可以进一步扩展到支持更复杂的请求模式和异构硬件环境。
📄 摘要(原文)
Large language models (LLMs) increasingly play an important role in a wide range of information processing and management tasks. Many of these tasks are performed in large batches or even offline, and the performance indictor for which is throughput. These tasks usually show the characteristic of prefix sharing, where different prompt input can partially show the common prefix. However, the existing LLM inference engines tend to optimize the streaming requests and show limitations of supporting the large batched tasks with the prefix sharing characteristic. The existing solutions use the LRU-based cache to reuse the KV context of common prefix between requests. The KV context that are about to be reused may prematurely evicted with the implicit cache management. Besides, the streaming oriented systems do not leverage the request-batch information and can not mix the decoding tokens with the prefill chunks to the best for the batched scenarios, and thus fails to saturate the GPU. We propose BatchLLM to address the above problems. BatchLLM explicitly identifies the common prefixes globally. The requests sharing the same prefix will be scheduled together to reuse the KV context the best. BatchLLM reorders the requests and schedules the requests with larger ratio of decoding first to better mix the decoding tokens with the latter prefill chunks, and applies memory-centric token batching to enlarge the token-batch sizes, which helps to increase the GPU utilization. Finally, BatchLLM optimizes the prefix-shared Attention kernel with horizontal fusion to reduce tail effect and kernel launch overhead. Extensive evaluation shows that BatchLLM outperforms vLLM and SGLang by 1.3$\times$ to 10.8$\times$ on a set of microbenchmarks and a typical industry workload under different hardware environments.