To Ensemble or Not: Assessing Majority Voting Strategies for Phishing Detection with Large Language Models
作者: Fouad Trad, Ali Chehab
分类: cs.CL, cs.AI
发布日期: 2024-11-29
备注: Accepted in 4th International Conference on Intelligent Systems and Pattern Recognition (ISPR24)
DOI: 10.1007/978-3-031-82150-9_13
💡 一句话要点
针对钓鱼URL检测,研究LLM集成投票策略的有效性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 钓鱼URL检测 集成学习 多数投票 文本分类
📋 核心要点
- 大型语言模型在钓鱼URL检测中面临提示词选择和模型差异带来的结果不一致性问题。
- 论文提出三种多数投票集成策略:基于提示、基于模型和混合集成,旨在提升检测性能。
- 研究表明,当各组件性能相当时集成有效,否则不如最优个体,为集成策略选择提供指导。
📝 摘要(中文)
大型语言模型(LLM)的有效性在很大程度上取决于接收到的提示词的质量。然而,即使处理相同的提示,由于训练过程的差异,LLM也可能产生不同的结果。为了利用多个LLM的集体智能并提高其性能,本研究调查了三种用于文本分类的多数投票策略,重点是钓鱼URL检测。这些策略包括:(1)基于提示的集成,它利用单个LLM对各种提示生成的响应进行多数投票;(2)基于模型的集成,它需要聚合来自多个LLM对单个提示的响应;(3)混合集成,它结合了这两种方法,将不同的提示发送到多个LLM,然后聚合它们的响应。我们的分析表明,集成策略最适合于各个组件表现水平相当的情况。但是,当个体性能存在显着差异时,集成方法的有效性可能不会超过性能最高的单个LLM或提示。在这种情况下,不建议选择集成技术。
🔬 方法详解
问题定义:论文旨在解决利用大型语言模型(LLM)进行钓鱼URL检测时,由于提示词选择和不同LLM之间的差异导致结果不一致的问题。现有方法依赖于单个LLM或单一提示,无法充分利用多个LLM的集体智能,且缺乏对集成策略有效性的系统评估。
核心思路:论文的核心思路是通过集成多个LLM的预测结果来提高钓鱼URL检测的准确性和鲁棒性。通过多数投票的方式,综合考虑不同LLM在不同提示下的输出,从而降低单个模型或提示的偏差,提升整体性能。
技术框架:论文提出了三种集成策略: 1. 基于提示的集成:对单个LLM使用多个不同的提示,然后对LLM针对同一URL在不同提示下的输出进行多数投票。 2. 基于模型的集成:使用相同的提示,让多个不同的LLM进行预测,然后对这些LLM的输出进行多数投票。 3. 混合集成:结合前两种方法,对多个LLM使用不同的提示,然后对所有LLM和提示的输出进行多数投票。
关键创新:论文的关键创新在于系统性地评估了三种不同的LLM集成策略在钓鱼URL检测任务中的有效性,并分析了集成策略的适用条件。研究结果表明,集成策略并非总是有效,当个体模型性能差异较大时,集成效果可能不如最优个体模型。
关键设计:论文的关键设计包括: 1. 提示词设计:选择具有代表性的提示词,以确保LLM能够充分理解任务并给出准确的预测。 2. 多数投票机制:采用简单的多数投票规则,即选择出现次数最多的类别作为最终预测结果。 3. 性能评估指标:使用准确率、精确率、召回率和F1值等指标来评估不同集成策略的性能。
🖼️ 关键图片


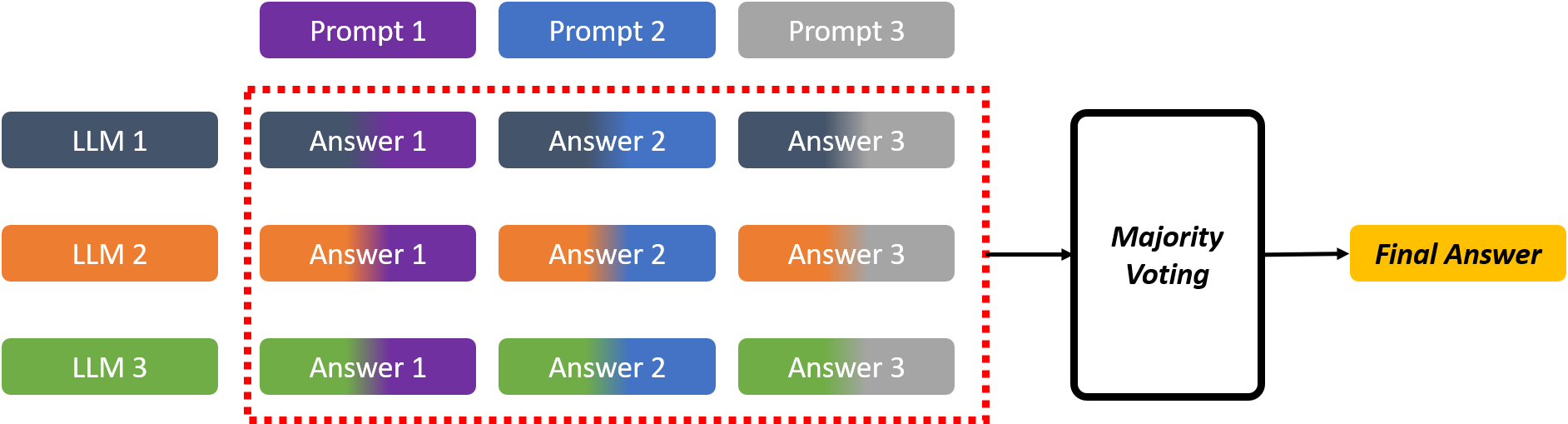
📊 实验亮点
研究表明,当各个LLM的性能水平相当时,集成策略能够有效提升钓鱼URL检测的准确性。然而,当个体LLM的性能存在显著差异时,集成方法的性能可能无法超过最佳的单个LLM或提示。因此,在选择集成策略时,需要仔细评估个体模型的性能。
🎯 应用场景
该研究成果可应用于网络安全领域,提升钓鱼URL检测系统的准确性和可靠性。通过集成多个LLM的智能,可以更有效地识别和拦截恶意链接,保护用户免受网络诈骗的侵害。未来,该方法可以扩展到其他文本分类任务,例如垃圾邮件过滤、情感分析等。
📄 摘要(原文)
The effectiveness of Large Language Models (LLMs) significantly relies on the quality of the prompts they receive. However, even when processing identical prompts, LLMs can yield varying outcomes due to differences in their training processes. To leverage the collective intelligence of multiple LLMs and enhance their performance, this study investigates three majority voting strategies for text classification, focusing on phishing URL detection. The strategies are: (1) a prompt-based ensemble, which utilizes majority voting across the responses generated by a single LLM to various prompts; (2) a model-based ensemble, which entails aggregating responses from multiple LLMs to a single prompt; and (3) a hybrid ensemble, which combines the two methods by sending different prompts to multiple LLMs and then aggregating their responses. Our analysis shows that ensemble strategies are most suited in cases where individual components exhibit equivalent performance levels. However, when there is a significant discrepancy in individual performance, the effectiveness of the ensemble method may not exceed that of the highest-performing single LLM or prompt. In such instances, opting for ensemble techniques is not recommended.