Critical Tokens Matter: Token-Level Contrastive Estimation Enhances LLM's Reasoning Capability
作者: Zicheng Lin, Tian Liang, Jiahao Xu, Qiuzhi Lin, Xing Wang, Ruilin Luo, Chufan Shi, Siheng Li, Yujiu Yang, Zhaopeng Tu
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-29 (更新: 2025-01-13)
备注: Work in progress
🔗 代码/项目: GITHUB
💡 一句话要点
提出基于关键Token对比估计的cDPO方法,提升LLM数学推理能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 数学推理 对比学习 关键Token 直接偏好优化
📋 核心要点
- 现有LLM在数学推理中面临挑战,因为它们难以识别并纠正推理过程中的关键错误步骤。
- 论文提出通过对比学习识别对错误结果影响最大的“关键Token”,并用正确Token替换以提升推理能力。
- 实验表明,该方法在GSM8K和MATH500等数据集上显著提升了Llama-3和Deepseek-math等模型的准确性。
📝 摘要(中文)
大型语言模型(LLM)在数学推理任务中面临巨大挑战,因为这些任务需要精确的逻辑推导和序列分析。本文提出了“关键Token”的概念,即推理轨迹中显著影响错误结果的元素。我们提出了一个新颖的框架,通过rollout sampling识别这些Token,并证明它们与传统错误Token存在显著差异。通过在GSM8K和MATH500等数据集上的大量实验,表明识别和替换关键Token可以显著提高模型准确性。我们提出了一种高效的方法,利用对比估计在大规模数据集中精确定位这些Token,并将此框架扩展到使用直接偏好优化(DPO)增强模型训练过程。在GSM8K和MATH500基准测试中,使用广泛使用的Llama-3(8B和70B)和Deepseek-math(7B)模型进行的实验结果证明了所提出的cDPO方法的有效性。我们的结果强调了利用关键Token减少推理任务中错误的潜力,从而推动能够进行鲁棒逻辑推导的AI系统的发展。我们的代码、带注释的数据集和训练模型可在https://github.com/chenzhiling9954/Critical-Tokens-Matter 获取,以支持和鼓励未来在该有前景的领域的研究。
🔬 方法详解
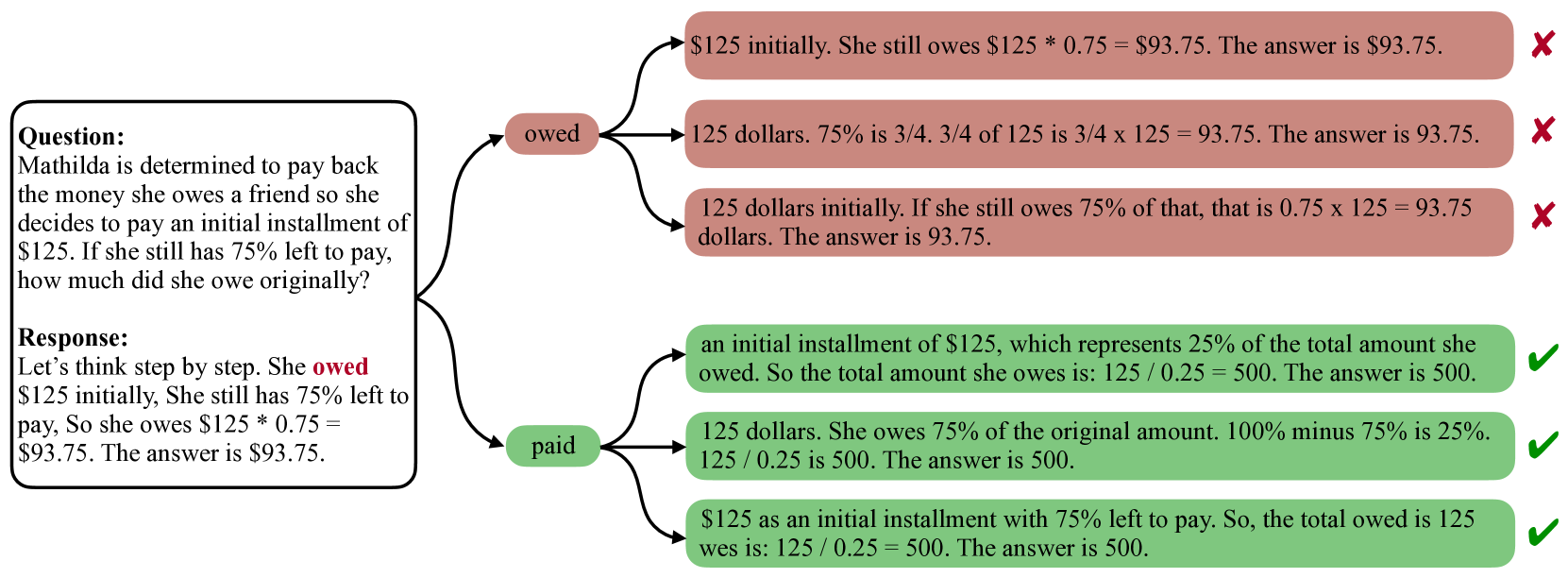
问题定义:LLM在数学推理任务中表现不佳,现有方法难以有效识别并纠正推理过程中的关键错误。传统的错误分析侧重于最终错误结果,忽略了导致错误的中间步骤中的关键Token。这些关键Token对最终结果有重大影响,但难以通过传统方法识别。
核心思路:论文的核心思路是通过对比学习,区分对错误结果影响最大的“关键Token”和不重要的Token。通过rollout sampling生成不同的推理轨迹,并对比不同轨迹中Token对最终结果的影响,从而识别关键Token。这种方法能够更精确地定位导致错误的根本原因。
技术框架:该框架主要包含以下几个阶段:1) Rollout Sampling:通过对LLM进行多次采样,生成不同的推理轨迹。2) 关键Token识别:对比不同轨迹中Token对最终结果的影响,使用对比估计方法识别关键Token。3) 模型训练:使用直接偏好优化(DPO)方法,利用识别出的关键Token进行模型训练,鼓励模型生成包含正确Token的推理轨迹。
关键创新:最重要的技术创新点在于提出了“关键Token”的概念,并设计了一种基于对比估计的方法来识别这些Token。与传统的错误分析方法不同,该方法关注推理过程中的关键步骤,能够更有效地提升模型的推理能力。
关键设计:在关键Token识别阶段,使用了对比损失函数,鼓励模型区分关键Token和非关键Token。在模型训练阶段,使用了DPO方法,通过对比包含正确Token和错误Token的推理轨迹,优化模型的策略。具体的参数设置和损失函数细节在论文中有详细描述,但此处无法完全展开。
🖼️ 关键图片

📊 实验亮点
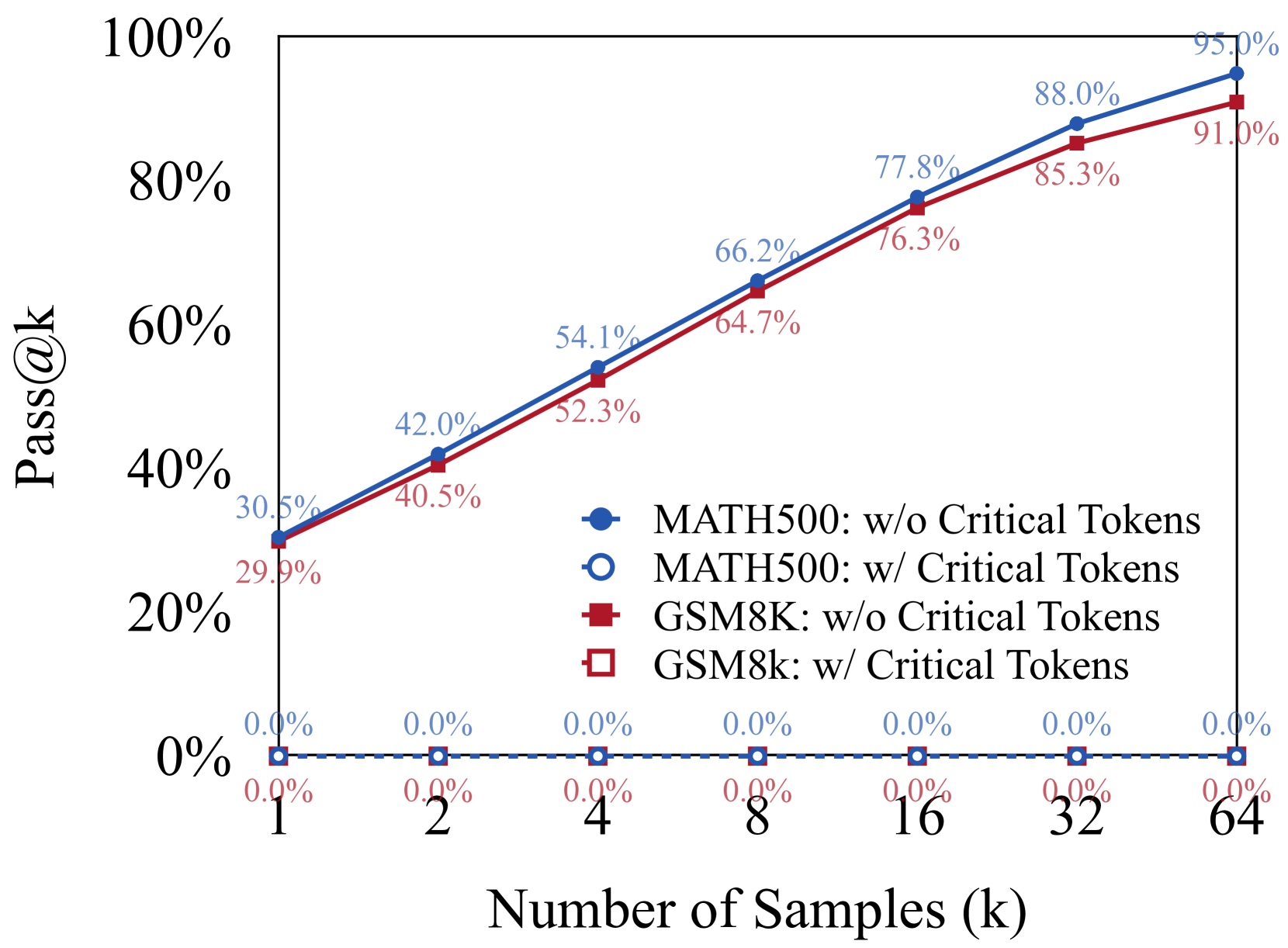
实验结果表明,提出的cDPO方法在GSM8K和MATH500数据集上显著提升了Llama-3(8B和70B)以及Deepseek-math(7B)模型的准确性。具体提升幅度在论文中给出,证明了该方法在提升LLM数学推理能力方面的有效性。代码、数据集和模型已开源。
🎯 应用场景
该研究成果可应用于提升LLM在数学、科学、工程等领域的推理能力,例如自动解题、公式推导、代码生成等。通过识别和纠正推理过程中的关键错误,可以提高AI系统的可靠性和准确性,使其能够更好地服务于教育、科研和工业等领域。
📄 摘要(原文)
Mathematical reasoning tasks pose significant challenges for large language models (LLMs) because they require precise logical deduction and sequence analysis. In this work, we introduce the concept of critical tokens -- elements within reasoning trajectories that significantly influence incorrect outcomes. We present a novel framework for identifying these tokens through rollout sampling and demonstrate their substantial divergence from traditional error tokens. Through extensive experiments on datasets such as GSM8K and MATH500, we show that identifying and replacing critical tokens significantly improves model accuracy. We propose an efficient methodology for pinpointing these tokens in large-scale datasets using contrastive estimation and extend this framework to enhance model training processes with direct preference optimization (DPO). Experimental results on GSM8K and MATH500 benchmarks with the widely used models Llama-3 (8B and 70B) and Deepseek-math (7B) demonstrate the effectiveness of the proposed approach, cDPO. Our results underscore the potential of leveraging critical tokens to reduce errors in reasoning tasks, advancing the development of AI systems capable of robust logical deduction. Our code, annotated datasets, and trained models are available at https://github.com/chenzhiling9954/Critical-Tokens-Matter to support and encourage future research in this promising field.