AIDetx: a compression-based method for identification of machine-learning generated text
作者: Leonardo Almeida, Pedro Rodrigues, Diogo Magalhães, Armando J. Pinho, Diogo Pratas
分类: cs.CL, cs.LG
发布日期: 2024-11-29
🔗 代码/项目: GITHUB
💡 一句话要点
AIDetx:一种基于数据压缩的机器学习生成文本识别方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 文本检测 机器生成文本 数据压缩 有限上下文模型 可解释性 计算效率 内容审核
📋 核心要点
- 现有深度学习文本检测方法计算成本高昂,可解释性不足,难以满足实际应用需求。
- AIDetx利用有限上下文模型构建压缩模型,通过比较压缩率来区分人工撰写和AI生成的文本。
- 实验表明,AIDetx在两个基准数据集上取得了优异的F1分数,且无需GPU,降低了计算成本。
📝 摘要(中文)
本文提出了一种名为AIDetx的新方法,该方法利用数据压缩技术来检测机器生成的文本。传统方法,如深度学习分类器,通常面临计算成本高和可解释性有限的问题。为了解决这些局限性,我们提出了一个基于压缩的分类框架,该框架利用有限上下文模型(FCM)。AIDetx为人工撰写和AI生成的文本构建不同的压缩模型,并基于哪个模型实现更高的压缩率来对新输入进行分类。我们在两个基准数据集上评估了AIDetx,分别实现了超过97%和99%的F1分数,突显了其高精度。与当前方法(如大型语言模型(LLM))相比,AIDetx提供了一种更具可解释性和计算效率的解决方案,显著减少了训练时间和硬件要求(例如,无需GPU)。完整的实现可在https://github.com/AIDetx/AIDetx公开获取。
🔬 方法详解
问题定义:论文旨在解决机器学习模型生成文本的自动识别问题。现有方法,特别是基于深度学习的分类器,通常需要大量的计算资源和训练数据,并且其决策过程缺乏透明度,难以解释。这限制了它们在资源受限环境中的应用,并降低了用户对检测结果的信任度。
核心思路:AIDetx的核心思路是利用数据压缩的原理来区分人工撰写和AI生成的文本。其假设是,AI生成的文本通常具有更高的规律性和可预测性,因此可以被压缩得更好。通过构建针对不同类型文本的压缩模型,并比较它们对新文本的压缩率,可以判断文本的来源。
技术框架:AIDetx的整体框架包括以下几个主要步骤:1) 数据预处理:对输入文本进行清洗和格式化。2) 模型构建:分别使用人工撰写和AI生成的文本训练有限上下文模型(FCM),构建两个独立的压缩模型。3) 压缩:使用两个模型分别对新的输入文本进行压缩。4) 分类:比较两个模型的压缩率,选择压缩率更高的模型所对应的文本类型作为最终的分类结果。
关键创新:AIDetx的关键创新在于将数据压缩技术应用于机器学习生成文本的识别。与传统的深度学习方法相比,它具有更高的计算效率和更好的可解释性。此外,AIDetx不需要大量的训练数据,可以在资源受限的环境中部署。
关键设计:AIDetx使用有限上下文模型(FCM)作为其核心的压缩算法。FCM通过统计文本中不同上下文的出现频率来构建压缩模型。模型的关键参数包括上下文的长度和模型的阶数。论文中可能涉及对这些参数的优化,以提高压缩性能和分类准确率。具体的损失函数未知,但目标是最大化压缩率的差异。
🖼️ 关键图片


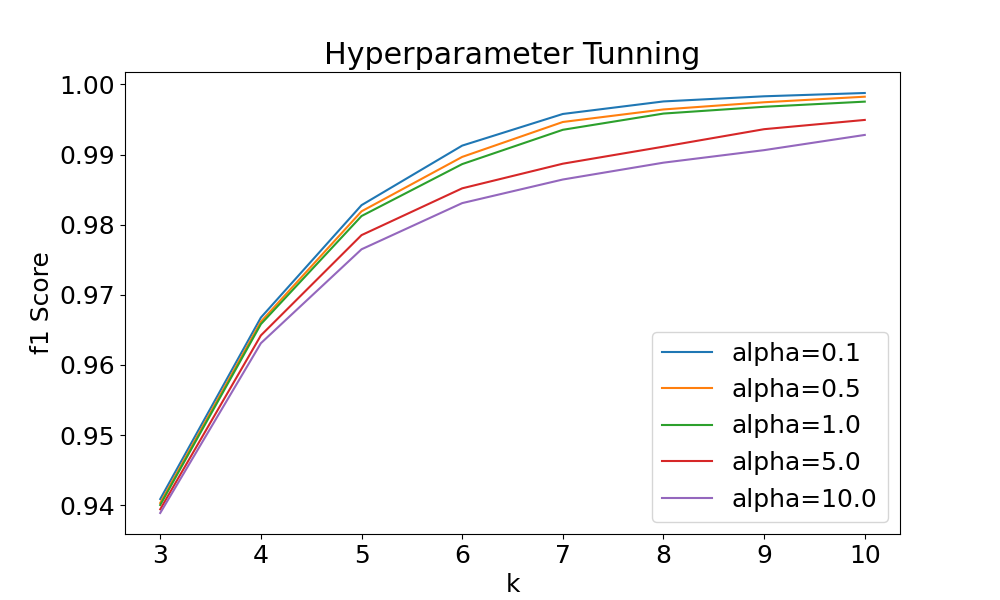
📊 实验亮点
AIDetx在两个基准数据集上取得了显著的成果,F1分数分别超过97%和99%,表明其具有很高的准确性。与需要GPU的大型语言模型相比,AIDetx无需GPU,显著降低了计算成本和硬件要求。这使得AIDetx成为一种更具实用性和可扩展性的解决方案。
🎯 应用场景
AIDetx可应用于检测虚假新闻、学术欺诈、以及自动化内容生成等领域。该方法计算效率高,易于部署,尤其适用于资源受限的场景。未来,AIDetx可集成到内容审核平台、学术诚信检测系统和AI内容溯源工具中,以提高内容质量和可信度。
📄 摘要(原文)
This paper introduces AIDetx, a novel method for detecting machine-generated text using data compression techniques. Traditional approaches, such as deep learning classifiers, often suffer from high computational costs and limited interpretability. To address these limitations, we propose a compression-based classification framework that leverages finite-context models (FCMs). AIDetx constructs distinct compression models for human-written and AI-generated text, classifying new inputs based on which model achieves a higher compression ratio. We evaluated AIDetx on two benchmark datasets, achieving F1 scores exceeding 97% and 99%, respectively, highlighting its high accuracy. Compared to current methods, such as large language models (LLMs), AIDetx offers a more interpretable and computationally efficient solution, significantly reducing both training time and hardware requirements (e.g., no GPUs needed). The full implementation is publicly available at https://github.com/AIDetx/AIDetx.