Sensitive Content Classification in Social Media: A Holistic Resource and Evaluation
作者: Dimosthenis Antypas, Indira Sen, Carla Perez-Almendros, Jose Camacho-Collados, Francesco Barbieri
分类: cs.CL
发布日期: 2024-11-29 (更新: 2025-06-24)
备注: Accepted at the 9th Workshop on Online Abuse and Harms (WOAH)
💡 一句话要点
提出用于社交媒体敏感内容分类的统一数据集,并验证微调LLM的有效性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 敏感内容分类 社交媒体审核 大型语言模型 数据集构建 内容安全
📋 核心要点
- 现有内容审核工具在定制性、准确性和隐私方面存在局限,且数据集主要集中于有害言论,忽略了其他敏感类别。
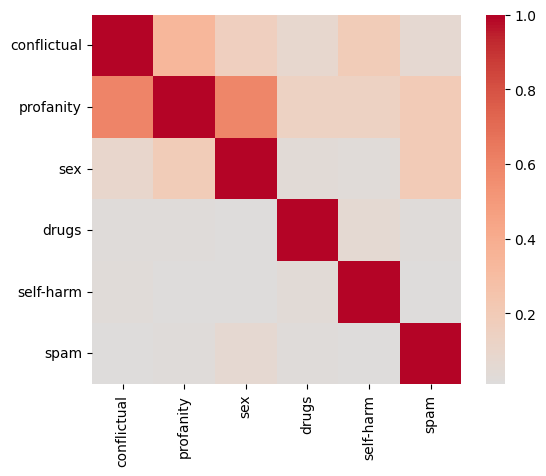
- 论文核心在于构建一个统一的、涵盖多种敏感类别(冲突性言论、亵渎、性内容、涉毒、自残、垃圾信息)的社交媒体数据集。
- 实验结果表明,在该数据集上微调LLM能显著提升敏感内容检测性能,优于现有开源和商业模型。
📝 摘要(中文)
在大规模数据集中检测敏感内容对于确保共享和分析的数据不包含有害信息至关重要。然而,现有的审核工具(如外部API)在定制性、跨不同敏感类别的准确性和隐私方面存在局限性。此外,现有的数据集和开源模型主要关注有害言论,在检测其他敏感类别(如药物滥用或自残)方面存在不足。本文提出了一个统一的数据集,专门用于社交媒体内容审核,涵盖六个敏感类别:冲突性言论、亵渎性言论、露骨的性内容、涉毒内容、自残和垃圾信息。通过采用一致的检索策略和指南收集和标注数据,我们解决了以往研究的不足。分析表明,在这个新数据集上微调大型语言模型(LLM)在检测性能方面比现成的开源模型(如LLaMA)有显著提高,甚至优于专有的OpenAI模型,总体性能差距为10-15%。这种局限性在流行的审核API上更为明显,这些API无法轻易地针对特定的敏感内容类别进行定制。
🔬 方法详解
问题定义:论文旨在解决社交媒体内容审核中,现有工具和数据集在检测多种敏感内容类别时存在的不足。现有方法主要集中于有害言论,忽略了其他重要的敏感类别,并且定制性差,无法满足特定场景的需求。此外,现有API的准确性和隐私性也存在问题。
核心思路:论文的核心思路是构建一个高质量、多类别的敏感内容数据集,并利用该数据集微调大型语言模型(LLM),从而提升模型在各种敏感内容类别上的检测性能。通过统一的数据收集和标注策略,确保数据集的质量和一致性。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 数据收集:采用一致的检索策略从社交媒体平台收集数据。2) 数据标注:人工标注数据,涵盖六个敏感类别。3) 模型训练:使用标注好的数据集微调大型语言模型(LLM)。4) 性能评估:在测试集上评估微调后的模型性能,并与现有模型和API进行比较。
关键创新:论文的关键创新在于构建了一个统一的、多类别的社交媒体敏感内容数据集。该数据集涵盖了六个重要的敏感类别,并采用了统一的数据收集和标注策略,保证了数据集的质量和一致性。此外,论文还验证了在该数据集上微调LLM的有效性,证明了其在敏感内容检测方面的优越性。
关键设计:数据集涵盖六个敏感类别:冲突性言论、亵渎性言论、露骨的性内容、涉毒内容、自残和垃圾信息。数据标注采用一致的指南,确保标注质量。使用大型语言模型(LLM)作为基础模型,并使用标注好的数据集进行微调。性能评估采用常用的指标,如准确率、召回率和F1值。
🖼️ 关键图片

📊 实验亮点
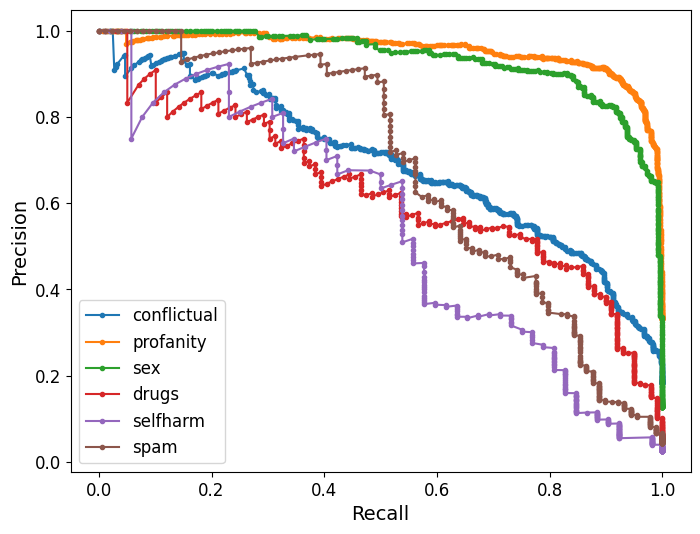
实验结果表明,在该数据集上微调LLM在敏感内容检测性能方面显著优于现成的开源模型(如LLaMA)和专有的OpenAI模型,总体性能提升10-15%。此外,流行的审核API在特定敏感内容类别上的表现也相对较差,表明了定制化数据集和模型的重要性。
🎯 应用场景
该研究成果可应用于社交媒体平台的内容审核,帮助自动识别和过滤敏感内容,从而营造更健康的网络环境。此外,该数据集和微调后的模型也可用于开发更精准的内容审核API,为第三方应用提供支持。未来,该研究可扩展到更多敏感内容类别,并探索更先进的模型和技术。
📄 摘要(原文)
The detection of sensitive content in large datasets is crucial for ensuring that shared and analysed data is free from harmful material. However, current moderation tools, such as external APIs, suffer from limitations in customisation, accuracy across diverse sensitive categories, and privacy concerns. Additionally, existing datasets and open-source models focus predominantly on toxic language, leaving gaps in detecting other sensitive categories such as substance abuse or self-harm. In this paper, we put forward a unified dataset tailored for social media content moderation across six sensitive categories: conflictual language, profanity, sexually explicit material, drug-related content, self-harm, and spam. By collecting and annotating data with consistent retrieval strategies and guidelines, we address the shortcomings of previous focalised research. Our analysis demonstrates that fine-tuning large language models (LLMs) on this novel dataset yields significant improvements in detection performance compared to open off-the-shelf models such as LLaMA, and even proprietary OpenAI models, which underperform by 10-15% overall. This limitation is even more pronounced on popular moderation APIs, which cannot be easily tailored to specific sensitive content categories, among others.