INCLUDE: Evaluating Multilingual Language Understanding with Regional Knowledge
作者: Angelika Romanou, Negar Foroutan, Anna Sotnikova, Zeming Chen, Sree Harsha Nelaturu, Shivalika Singh, Rishabh Maheshwary, Micol Altomare, Mohamed A. Haggag, Snegha A, Alfonso Amayuelas, Azril Hafizi Amirudin, Viraat Aryabumi, Danylo Boiko, Michael Chang, Jenny Chim, Gal Cohen, Aditya Kumar Dalmia, Abraham Diress, Sharad Duwal, Daniil Dzenhaliou, Daniel Fernando Erazo Florez, Fabian Farestam, Joseph Marvin Imperial, Shayekh Bin Islam, Perttu Isotalo, Maral Jabbarishiviari, Börje F. Karlsson, Eldar Khalilov, Christopher Klamm, Fajri Koto, Dominik Krzemiński, Gabriel Adriano de Melo, Syrielle Montariol, Yiyang Nan, Joel Niklaus, Jekaterina Novikova, Johan Samir Obando Ceron, Debjit Paul, Esther Ploeger, Jebish Purbey, Swati Rajwal, Selvan Sunitha Ravi, Sara Rydell, Roshan Santhosh, Drishti Sharma, Marjana Prifti Skenduli, Arshia Soltani Moakhar, Bardia Soltani Moakhar, Ran Tamir, Ayush Kumar Tarun, Azmine Toushik Wasi, Thenuka Ovin Weerasinghe, Serhan Yilmaz, Mike Zhang, Imanol Schlag, Marzieh Fadaee, Sara Hooker, Antoine Bosselut
分类: cs.CL
发布日期: 2024-11-29
💡 一句话要点
INCLUDE:利用区域知识评估多语言语言理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言理解 区域知识 语言模型评估 QA基准 本地化 考试数据 知识推理
📋 核心要点
- 现有大型语言模型在不同语言间性能差异显著,阻碍其在特定区域的有效应用。
- 论文提出INCLUDE基准,利用本地考试数据,评估LLM在实际语言环境下的知识和推理能力。
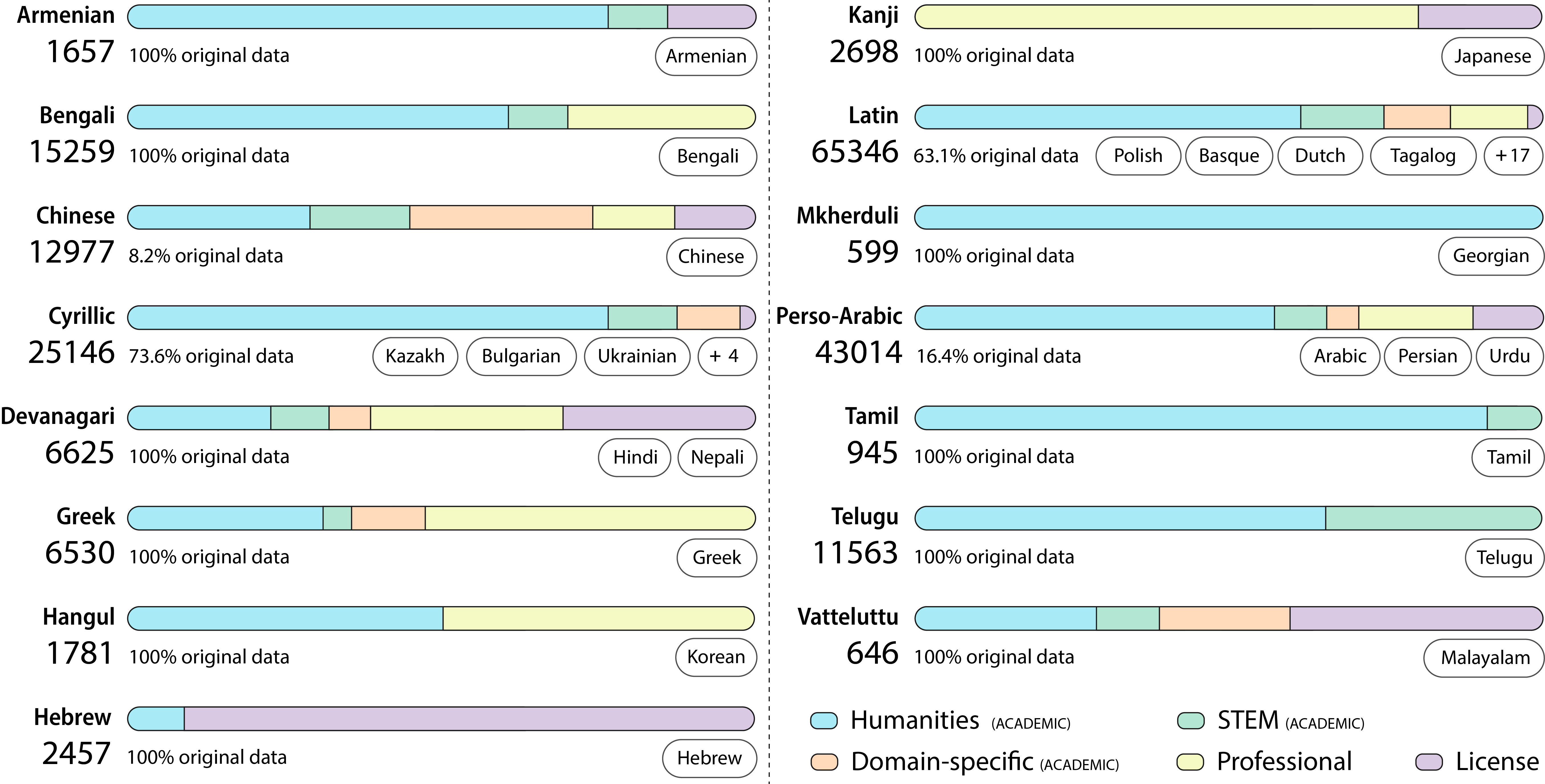
- INCLUDE包含44种语言的近20万个QA对,为多语言LLM的评估提供了一个全面的资源。
📝 摘要(中文)
大型语言模型(LLM)在不同语言之间的性能差异阻碍了它们在许多地区的有效部署,从而限制了生成式AI工具在许多社区的潜在经济和社会价值。多语言LLM的发展受到缺乏英语以外的高质量评估资源的限制。此外,当前的多语言基准构建实践通常翻译英语资源,忽略了多语言系统将被使用的环境的区域和文化知识。本文构建了一个包含197,243个QA对的评估套件,这些QA对来自本地考试资源,用于衡量多语言LLM在各种区域环境中的能力。INCLUDE是一个全面的、以知识和推理为中心的基准,涵盖44种书面语言,用于评估多语言LLM在实际语言环境中的性能。
🔬 方法详解
问题定义:现有的大型语言模型在不同语言环境下的表现存在显著差异,尤其是在处理需要特定区域知识的任务时。现有的多语言评估基准往往是简单地将英文数据翻译成其他语言,忽略了不同区域的文化和知识差异,无法真实反映模型在实际应用中的性能。因此,需要一个能够充分考虑区域知识的多语言评估基准。
核心思路:论文的核心思路是利用各个地区的本地考试数据来构建评估基准。本地考试数据能够反映该地区的文化、历史、地理等方面的知识,从而更准确地评估模型在该地区的语言理解能力。通过在这些数据上评估模型,可以更好地了解模型在实际应用中的表现,并为模型的改进提供指导。
技术框架:INCLUDE基准的构建流程主要包括以下几个步骤:1) 数据收集:从各个地区的本地考试资源中收集QA对。2) 数据清洗:对收集到的数据进行清洗,去除噪声和错误。3) 数据标注:对数据进行标注,例如标注问题的类型、答案的来源等。4) 基准构建:将清洗和标注后的数据整理成基准,并提供评估工具。
关键创新:INCLUDE基准的关键创新在于其数据来源。与以往的基准不同,INCLUDE使用本地考试数据,从而能够更好地反映不同地区的文化和知识差异。这使得INCLUDE能够更准确地评估模型在实际应用中的性能。
关键设计:INCLUDE基准包含44种书面语言,涵盖了广泛的地理区域和文化背景。每个QA对都包含问题、答案和上下文信息。基准还提供了评估工具,可以方便地评估模型在基准上的性能。具体的参数设置、损失函数、网络结构等技术细节取决于被评估的LLM模型。
🖼️ 关键图片

📊 实验亮点
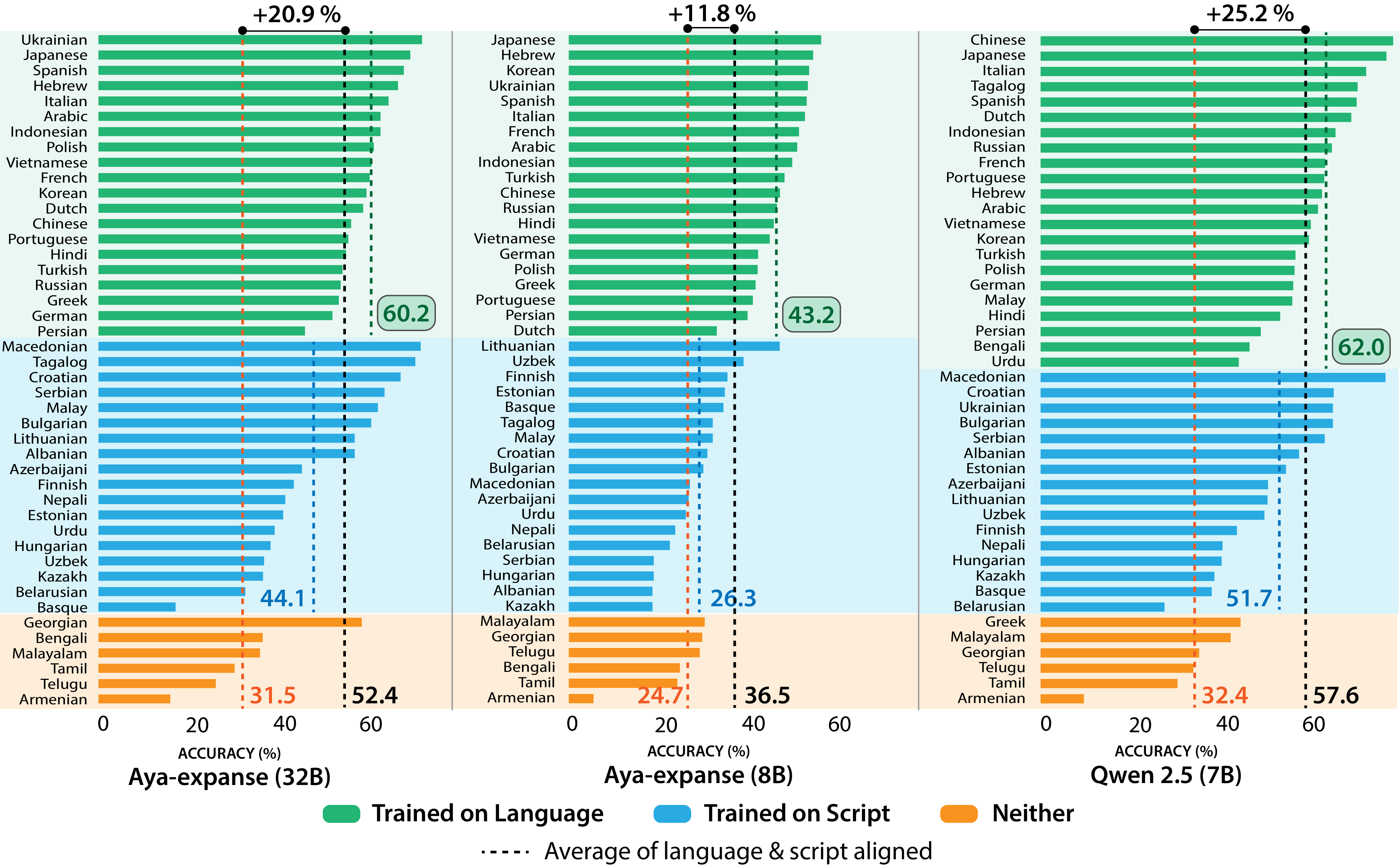
INCLUDE基准包含44种语言的197,243个QA对,是目前规模最大的多语言知识和推理基准之一。通过在INCLUDE上评估多语言LLM,可以更准确地了解模型在不同语言和文化环境下的性能,并为模型的改进提供有价值的反馈。
🎯 应用场景
该研究成果可应用于多语言大型语言模型的开发和评估,尤其是在需要特定区域知识的场景下,例如本地化搜索、智能客服、教育等。INCLUDE基准的发布将促进多语言LLM在各个地区的有效部署,并提升其在实际应用中的性能。
📄 摘要(原文)
The performance differential of large language models (LLM) between languages hinders their effective deployment in many regions, inhibiting the potential economic and societal value of generative AI tools in many communities. However, the development of functional LLMs in many languages (\ie, multilingual LLMs) is bottlenecked by the lack of high-quality evaluation resources in languages other than English. Moreover, current practices in multilingual benchmark construction often translate English resources, ignoring the regional and cultural knowledge of the environments in which multilingual systems would be used. In this work, we construct an evaluation suite of 197,243 QA pairs from local exam sources to measure the capabilities of multilingual LLMs in a variety of regional contexts. Our novel resource, INCLUDE, is a comprehensive knowledge- and reasoning-centric benchmark across 44 written languages that evaluates multilingual LLMs for performance in the actual language environments where they would be deployed.