Noro: Noise-Robust One-shot Voice Conversion with Hidden Speaker Representation Learning
作者: Haorui He, Yuchen Song, Yuancheng Wang, Haoyang Li, Xueyao Zhang, Li Wang, Gongping Huang, Eng Siong Chng, Zhizheng Wu
分类: cs.SD, cs.CL, eess.AS
发布日期: 2024-11-29 (更新: 2025-08-28)
备注: Accepted by APSIPA ASC 2025
💡 一句话要点
提出Noro,一种噪声鲁棒的单样本语音转换系统,提升噪声环境下的转换效果。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音转换 单样本学习 噪声鲁棒性 说话人表征学习 对比学习
📋 核心要点
- 单样本语音转换在噪声环境下性能显著下降,原因是参考语音质量受损。
- Noro采用双分支参考编码和噪声无关对比损失,提取更鲁棒的说话人信息。
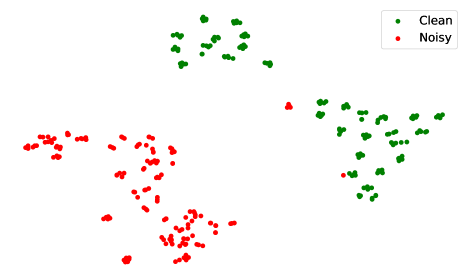
- 实验表明,Noro在噪声环境下优于基线,且编码器在说话人表征学习中表现出色。
📝 摘要(中文)
本文提出了一种噪声鲁棒的单样本语音转换(VC)系统Noro,旨在解决真实场景下参考语音(通常来自互联网)包含各种干扰(如背景噪声)时,语音转换效果下降的问题。Noro采用了专门为噪声参考语音设计的创新组件,包括双分支参考编码模块和噪声无关的对比说话人损失。实验结果表明,Noro在干净和噪声场景下均优于基线系统,突显了其在实际应用中的有效性。此外,通过将基线系统的参考编码器重新用作说话人编码器,我们研究了其隐藏的说话人表征能力。结果表明,在SUPERB设置下,它与几种先进的自监督学习模型在说话人表征方面具有竞争力,突出了通过单样本语音转换任务推进说话人表征学习的潜力。
🔬 方法详解
问题定义:单样本语音转换(One-shot Voice Conversion, VC)在实际应用中面临噪声干扰问题。现有的单样本语音转换方法依赖于干净的参考语音来提取说话人信息,但在真实场景下,参考语音通常包含各种噪声,这会导致提取的说话人信息不准确,从而降低语音转换的质量。因此,如何在噪声环境下实现鲁棒的单样本语音转换是一个关键问题。
核心思路:Noro的核心思路是通过设计一个噪声鲁棒的参考编码器,从噪声参考语音中提取干净的说话人信息。具体来说,Noro采用了双分支结构,一个分支处理原始噪声语音,另一个分支处理降噪后的语音,并通过对比学习来增强编码器的噪声鲁棒性。此外,Noro还引入了噪声无关的对比说话人损失,进一步提高模型在噪声环境下的性能。
技术框架:Noro系统主要包含以下几个模块:1) 双分支参考编码模块:该模块包含两个分支,分别处理原始噪声参考语音和降噪后的参考语音。2) 语音转换模块:该模块负责将输入语音转换为目标说话人的语音,它以输入语音和参考编码器提取的说话人信息作为输入。3) 噪声无关对比说话人损失:该损失函数用于训练参考编码器,使其能够提取噪声鲁棒的说话人信息。整体流程是,首先通过双分支参考编码模块提取参考语音的说话人信息,然后将该信息输入到语音转换模块中,最后通过噪声无关对比说话人损失来优化整个系统。
关键创新:Noro的关键创新在于其噪声鲁棒的参考编码器和噪声无关的对比说话人损失。双分支结构能够有效地利用原始噪声语音和降噪后的语音,从而提取更准确的说话人信息。噪声无关的对比说话人损失能够进一步提高模型在噪声环境下的性能,使得模型能够更好地适应各种噪声条件。
关键设计:双分支参考编码模块的具体实现细节未知,论文可能使用了某种降噪算法(具体算法未知)来生成降噪后的语音。噪声无关对比说话人损失的具体形式未知,但其目标是使得来自同一说话人的语音在特征空间中更接近,而来自不同说话人的语音在特征空间中更远离。具体的网络结构和参数设置在论文中可能有所描述,但此处未知。
🖼️ 关键图片


📊 实验亮点
实验结果表明,Noro在噪声环境下显著优于基线系统,证明了其噪声鲁棒性。此外,研究还发现,Noro的参考编码器在说话人表征学习方面具有竞争力,甚至可以与一些先进的自监督学习模型相媲美,这表明单样本语音转换任务具有促进说话人表征学习的潜力。
🎯 应用场景
Noro可应用于各种需要语音转换的场景,尤其是在用户提供的参考语音质量不高的环境下,例如在线语音克隆、语音助手定制、以及语音内容创作等。该研究有助于提升语音转换技术在实际应用中的可用性和用户体验,并可能推动个性化语音交互技术的发展。
📄 摘要(原文)
The effectiveness of one-shot voice conversion (VC) decreases in real-world scenarios where reference speeches, which are often sourced from the internet, contain various disturbances like background noise. To address this issue, we introduce Noro, a noise-robust one-shot VC system. Noro features innovative components tailored for VC using noisy reference speeches, including a dual-branch reference encoding module and a noise-agnostic contrastive speaker loss. Experimental results demonstrate that Noro outperforms our baseline system in both clean and noisy scenarios, highlighting its efficacy for real-world applications. Additionally, we investigate the hidden speaker representation capabilities of our baseline system by repurposing its reference encoder as a speaker encoder. The results show that it is competitive with several advanced self-supervised learning models for speaker representation under the SUPERB settings, highlighting the potential for advancing speaker representation learning through one-shot VC tasks.