In-Context Learning with Noisy Labels
作者: Junyong Kang, Donghyun Son, Hwanjun Song, Buru Chang
分类: cs.CL
发布日期: 2024-11-29
💡 一句话要点
提出噪声标签下的上下文学习任务,并设计方法提升LLM在现实场景下的泛化能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 噪声标签 大型语言模型 鲁棒性 标签校正
📋 核心要点
- 现有上下文学习研究忽略了现实世界中标签噪声的普遍存在,这会严重影响LLM的性能。
- 本文提出在噪声标签下进行上下文学习,并设计方法来减轻噪声标签对LLM性能的负面影响。
- 实验证明,提出的方法能够有效提升LLM在噪声标签环境下的上下文学习能力,保障模型性能。
📝 摘要(中文)
本文提出了一个新的任务:噪声标签下的上下文学习,旨在解决现实世界中上下文学习面临的标签噪声问题。在真实场景中,任务演示中的标签不可避免地会受到噪声的干扰。针对这一问题,本文提出了一种新的方法,并提供了若干基线方法。实验结果表明,本文提出的方法能够有效防止噪声标签导致的上下文学习性能下降,为LLM在实际应用中提供保障。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在上下文学习中,由于演示数据中存在噪声标签而导致的性能下降问题。现有的上下文学习方法通常假设演示数据是干净的,但在实际应用中,标签噪声是不可避免的,这会严重影响LLMs的泛化能力。
核心思路:论文的核心思路是借鉴学习噪声标签领域的研究成果,设计一种能够识别并纠正噪声标签的方法,从而提高LLMs在噪声环境下的上下文学习能力。通过对演示数据进行处理,降低噪声标签对模型的影响。
技术框架:论文提出了一个针对噪声标签上下文学习的框架,该框架包含以下几个主要步骤:1) 噪声检测:识别演示数据中的潜在噪声标签;2) 标签校正:对识别出的噪声标签进行校正,尽可能恢复真实标签;3) 上下文学习:利用校正后的演示数据进行上下文学习,提升LLMs的性能。具体的技术细节和模块取决于所采用的具体方法。
关键创新:论文的关键创新在于首次将噪声标签问题引入到上下文学习中,并提出了相应的解决方案。与传统的上下文学习方法相比,该方法能够更好地适应现实世界的复杂环境,提高LLMs的鲁棒性和泛化能力。
关键设计:论文的具体方法设计未知,摘要中只提到提出了新方法和基线方法,但未给出具体细节。可能涉及的关键设计包括:噪声检测的阈值设定、标签校正的策略选择(例如,使用其他演示数据进行投票)、以及损失函数的设计(例如,引入对噪声标签的惩罚项)。
🖼️ 关键图片
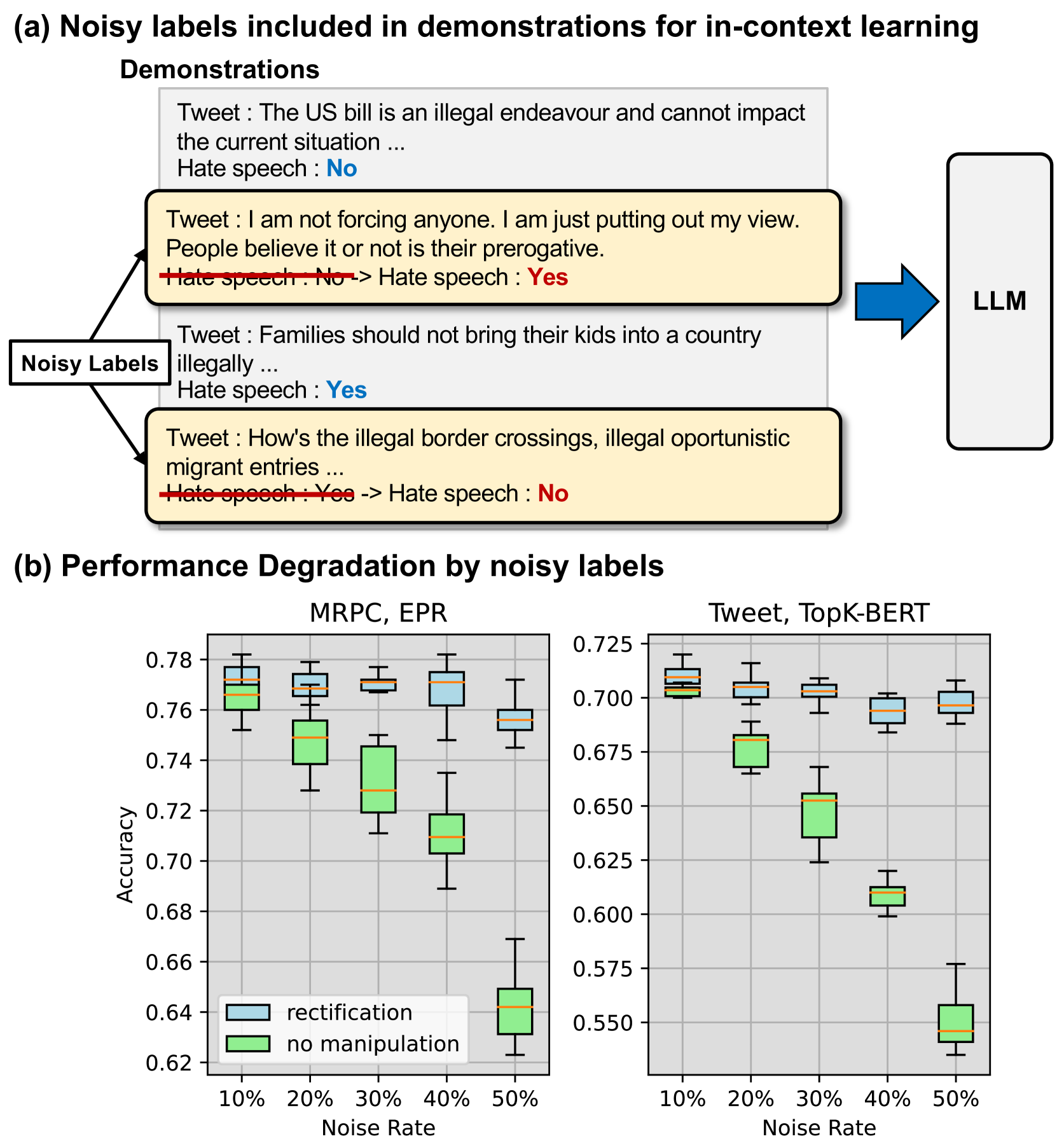

📊 实验亮点
论文通过实验证明,提出的方法能够有效缓解噪声标签对上下文学习性能的影响。具体的性能数据和对比基线未知,但摘要明确指出该方法能够作为一种保障措施,防止噪声标签导致的性能下降。未来的研究可以进一步量化该方法的性能提升幅度,并与其他噪声鲁棒性方法进行比较。
🎯 应用场景
该研究成果可应用于各种需要利用LLM进行上下文学习的实际场景,例如文本分类、情感分析、机器翻译等。尤其是在数据标注质量不高或者存在大量噪声的情况下,该方法能够显著提升LLM的性能和可靠性,具有重要的应用价值和潜力。未来可以进一步探索如何将该方法应用于更复杂的任务和领域。
📄 摘要(原文)
In-context learning refers to the emerging ability of large language models (LLMs) to perform a target task without additional training, utilizing demonstrations of the task. Recent studies aim to enhance in-context learning performance by selecting more useful demonstrations. However, they overlook the presence of inevitable noisy labels in task demonstrations that arise during the labeling process in the real-world. In this paper, we propose a new task, in-context learning with noisy labels, which aims to solve real-world problems for in-context learning where labels in task demonstrations would be corrupted. Moreover, we propose a new method and baseline methods for the new task, inspired by studies in learning with noisy labels. Through experiments, we demonstrate that our proposed method can serve as a safeguard against performance degradation in in-context learning caused by noisy labels.