KV Shifting Attention Enhances Language Modeling
作者: Mingyu Xu, Wei Cheng, Bingning Wang, Weipeng Chen
分类: cs.CL
发布日期: 2024-11-29 (更新: 2024-12-05)
备注: 22 pages
💡 一句话要点
提出KV移位注意力机制,提升语言模型的归纳能力和建模效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 注意力机制 Transformer 上下文学习 归纳头 KV移位注意力 模型优化
📋 核心要点
- 现有大型语言模型依赖多层注意力实现归纳头机制,计算成本高昂且效率较低。
- 论文提出KV移位注意力,通过移位操作减少对模型深度和宽度的需求,提升归纳效率。
- 实验证明,KV移位注意力有助于学习归纳头和语言建模,实现更好的性能和更快的收敛。
📝 摘要(中文)
当前的大型语言模型主要基于仅解码器结构的Transformer,具有强大的上下文学习(ICL)能力。普遍认为,ICL能力的重要基础是归纳头机制,这至少需要两层注意力。为了更有效地实现模型的归纳能力,我们重新审视了归纳头机制,并提出了一种KV移位注意力。我们从理论上证明,KV移位注意力降低了模型对归纳头机制的深度和宽度的要求。实验结果表明,KV移位注意力有利于学习归纳头和语言建模,从而在从玩具模型到具有超过10B参数的预训练模型的过程中,获得更好的性能或更快的收敛。
🔬 方法详解
问题定义:现有大型语言模型依赖于多层注意力机制来实现归纳头,而归纳头被认为是上下文学习能力的关键。然而,这种方法需要较深和较宽的网络结构,导致计算成本高昂,效率低下。论文旨在解决如何更有效地实现模型的归纳能力,降低模型对深度和宽度的要求。
核心思路:论文的核心思路是通过引入KV移位注意力机制,在单层注意力中模拟多层注意力才能实现的归纳头功能。通过对Key和Value进行移位操作,使得模型能够更容易地学习到输入序列中不同位置之间的关系,从而提升归纳能力。这样设计的目的是减少对模型深度和宽度的依赖,提高计算效率。
技术框架:该方法主要是在Transformer的注意力机制中引入KV移位操作。具体来说,在计算注意力权重之前,对Key和Value进行循环移位。移位的距离可以是一个固定的值,也可以是可学习的参数。移位后的Key和Value再进行正常的注意力计算。整体框架仍然是基于Transformer的解码器结构。
关键创新:最重要的技术创新点是KV移位操作。与传统的注意力机制相比,KV移位注意力能够在单层注意力中模拟多层注意力才能实现的归纳头功能,从而降低了对模型深度和宽度的要求。本质区别在于,传统的注意力机制关注的是Query和Key之间的相似度,而KV移位注意力则关注的是Key和Value之间的相对位置关系。
关键设计:KV移位操作的具体实现方式包括循环移位和可学习的移位参数。循环移位是指将Key和Value的元素进行循环移动,移出边界的元素会重新回到另一端。可学习的移位参数是指移位的距离不是固定的,而是通过学习得到的。损失函数仍然采用交叉熵损失函数,用于训练语言模型。网络结构仍然是基于Transformer的解码器结构,只是在注意力机制中加入了KV移位操作。
🖼️ 关键图片
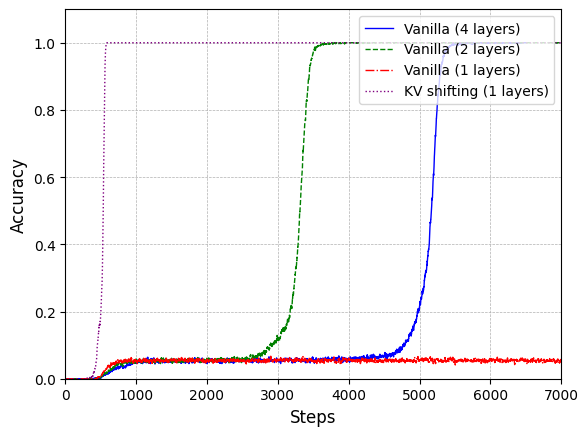
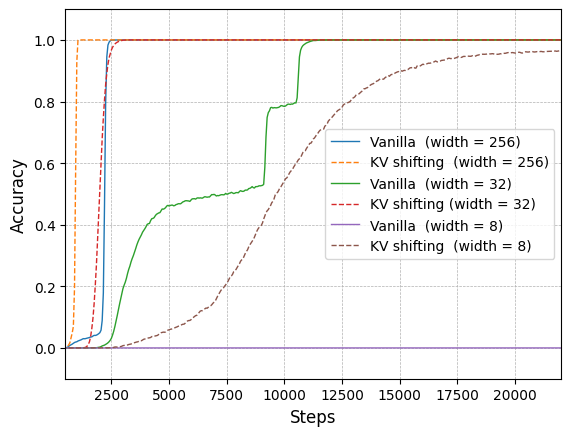
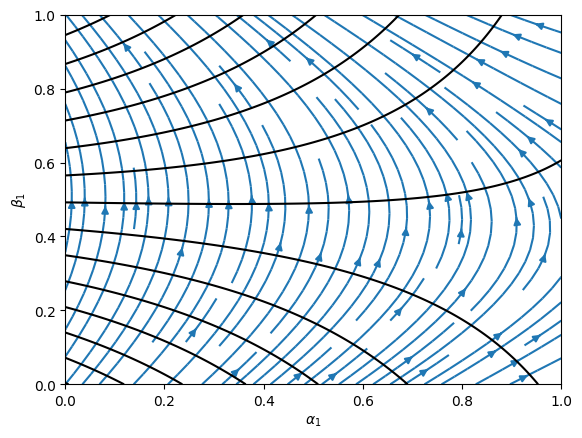
📊 实验亮点
实验结果表明,KV移位注意力能够提升语言模型的性能和收敛速度。在玩具模型和超过10B参数的预训练模型上,使用KV移位注意力的模型均表现出更好的性能或更快的收敛速度。具体性能数据未知,但论文强调了其在学习归纳头和语言建模方面的优势。
🎯 应用场景
该研究成果可应用于各种自然语言处理任务,特别是需要上下文学习能力的场景,如机器翻译、文本摘要、对话系统等。通过降低模型对深度和宽度的要求,可以减少计算资源消耗,提高模型部署效率,并促进大型语言模型在资源受限设备上的应用。未来,该技术有望进一步提升语言模型的推理能力和泛化性能。
📄 摘要(原文)
The current large language models are mainly based on decode-only structure transformers, which have great in-context learning (ICL) capabilities. It is generally believed that the important foundation of its ICL capability is the induction heads mechanism, which requires at least two layers attention. In order to more efficiently implement the ability of the model's induction, we revisit the induction heads mechanism and proposed a KV shifting attention. We theoretically prove that the KV shifting attention reducing the model's requirements for the depth and width of the induction heads mechanism. Our experimental results demonstrate that KV shifting attention is beneficial to learning induction heads and language modeling, which lead to better performance or faster convergence from toy models to the pre-training models with more than 10 B parameters.