Initialization using Update Approximation is a Silver Bullet for Extremely Efficient Low-Rank Fine-Tuning
作者: Kaustubh Ponkshe, Raghav Singhal, Eduard Gorbunov, Alexey Tumanov, Samuel Horvath, Praneeth Vepakomma
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-29 (更新: 2025-10-02)
备注: Kaustubh Ponkshe and Raghav Singhal contributed equally to this work
🔗 代码/项目: GITHUB
💡 一句话要点
LoRA-SB:通过更新近似初始化实现高效低秩微调,性能超越LoRA-XS
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 低秩微调 参数高效 初始化策略 大型语言模型 LoRA LoRA-XS 梯度近似 更新方向
📋 核心要点
- 现有低秩微调方法难以达到全参数微调的性能,限制了其应用。
- LoRA-SB通过优化初始化策略,在低秩子空间内有效近似全参数微调,提升性能。
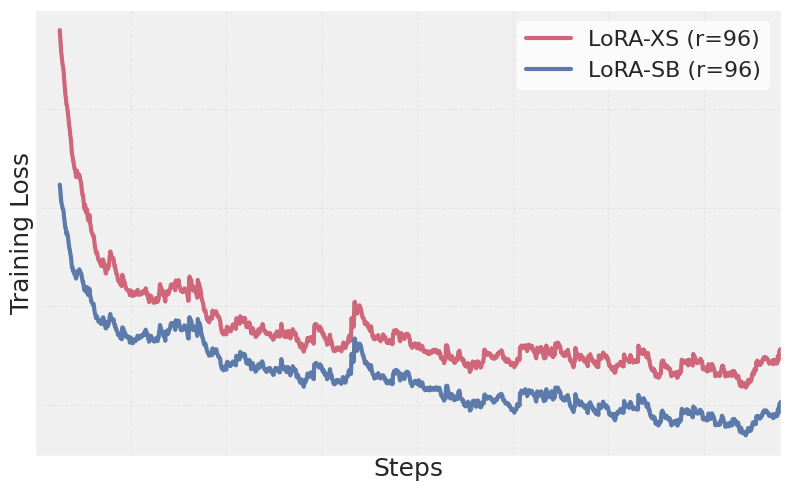
- 实验表明,LoRA-SB在显著减少可学习参数的同时,性能超越LoRA和LoRA-XS。
📝 摘要(中文)
低秩适配器已成为高效微调大型语言模型的标准方法,但通常无法达到全参数微调的性能。本文提出了一种名为LoRA Silver Bullet (LoRA-SB) 的方法,它通过精心设计的初始化策略,在低秩子空间内近似全参数微调。理论证明,LoRA-XS的架构,即在B和A之间插入一个可学习的r x r矩阵,同时保持其他矩阵固定,为这种近似提供了精确的条件。利用其受限的更新空间,实现了高秩梯度更新的最佳缩放,同时消除了对缩放因子调整的需求。证明了提出的初始化方法提供了初始梯度的最佳低秩近似,并在整个训练过程中保持更新方向。在数学推理、常识推理和语言理解任务上的大量实验表明,该方法优于LoRA(和基线),同时使用的可学习参数减少了27-90倍,并全面优于LoRA-XS。研究结果表明,可以在低秩子空间中模拟全参数微调,并在不牺牲性能的情况下实现显著的参数效率提升。
🔬 方法详解
问题定义:论文旨在解决低秩微调方法在性能上与全参数微调存在差距的问题。现有的低秩适配器,如LoRA,虽然参数效率高,但在某些任务上无法达到全参数微调的性能水平,这限制了它们在对性能要求较高的场景中的应用。因此,如何提升低秩微调的性能,使其逼近甚至超越全参数微调,是本文要解决的核心问题。
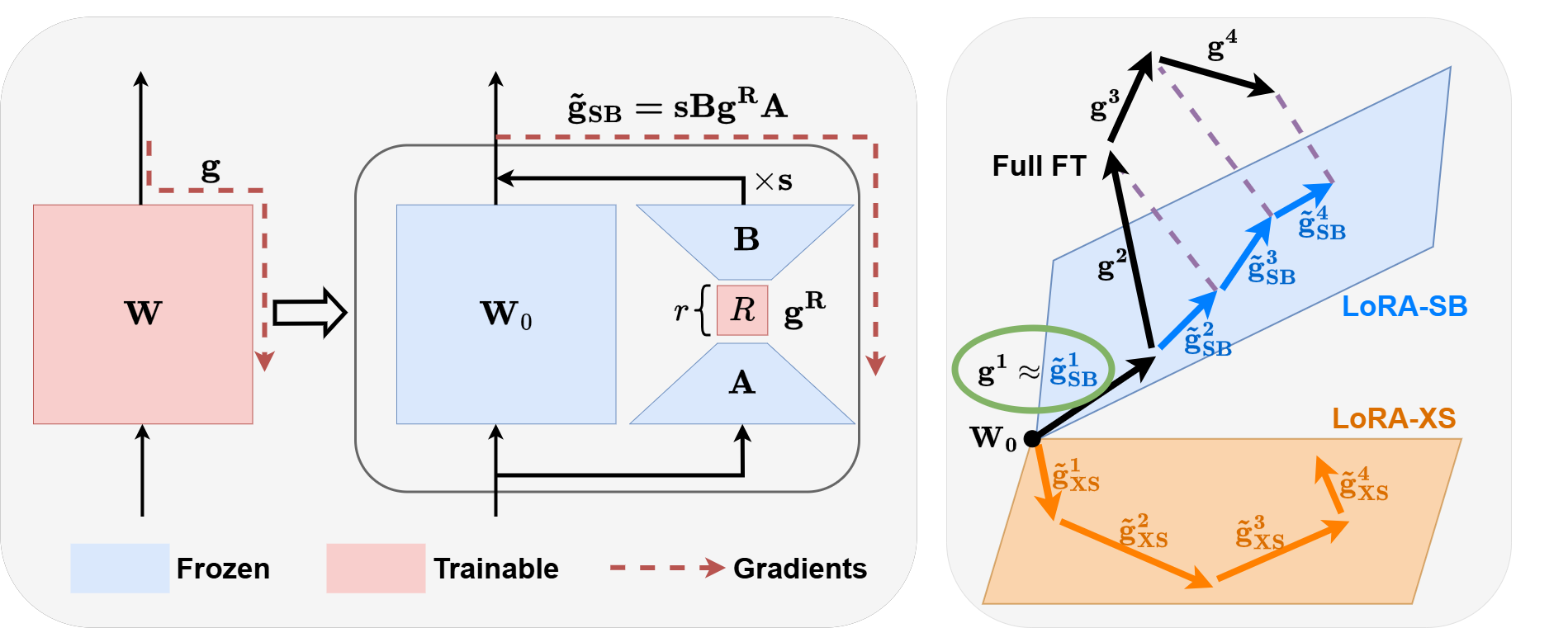
核心思路:LoRA-SB的核心思路是通过精心设计的初始化策略,使得低秩适配器能够更好地近似全参数微调的效果。具体来说,该方法利用LoRA-XS的架构特性,即在矩阵B和A之间插入一个可学习的r x r矩阵,并保持其他矩阵固定,来构建一个受限的更新空间。通过优化这个受限空间内的初始化,可以实现高秩梯度更新的最佳缩放,从而在低秩子空间内模拟全参数微调。
技术框架:LoRA-SB的技术框架主要包括以下几个步骤:1) 选择LoRA-XS架构,确定低秩适配器的位置和维度。2) 设计特定的初始化策略,该策略能够提供初始梯度的最佳低秩近似,并保持更新方向。3) 利用LoRA-XS的受限更新空间,实现高秩梯度更新的最佳缩放,无需手动调整缩放因子。4) 使用标准的优化算法(如Adam)进行训练。
关键创新:LoRA-SB的关键创新在于其初始化策略。该策略能够提供初始梯度的最佳低秩近似,并保持更新方向,从而使得低秩适配器能够更好地模拟全参数微调的效果。此外,LoRA-SB还利用了LoRA-XS的架构特性,实现了高秩梯度更新的最佳缩放,无需手动调整缩放因子,进一步提升了训练效率和性能。与现有方法相比,LoRA-SB的本质区别在于其初始化策略的设计,以及对LoRA-XS架构特性的充分利用。
关键设计:LoRA-SB的关键设计包括:1) 初始化策略:具体如何初始化适配器的权重矩阵,以保证初始梯度近似和更新方向的保持,论文中应该有详细的数学公式或算法描述。2) LoRA-XS架构的选择:为什么选择LoRA-XS,而不是其他低秩适配器架构?LoRA-XS的哪些特性使其更适合实现全参数微调的近似?3) 损失函数和优化器:虽然论文中没有明确提及,但损失函数和优化器的选择也会影响最终的性能。通常会选择交叉熵损失函数和Adam优化器。
🖼️ 关键图片
📊 实验亮点
LoRA-SB在数学推理、常识推理和语言理解任务上均取得了显著的性能提升。实验结果表明,LoRA-SB在使用27-90倍更少的可学习参数的情况下,性能超越了LoRA和LoRA-XS。例如,在某些任务上,LoRA-SB甚至能够达到或超过全参数微调的性能水平,这充分证明了其有效性和优越性。
🎯 应用场景
LoRA-SB具有广泛的应用前景,可用于高效微调各种大型语言模型,尤其是在资源受限的场景下。例如,在移动设备或边缘计算平台上部署大型语言模型时,可以使用LoRA-SB来减少模型大小和计算量,同时保持较高的性能。此外,LoRA-SB还可以应用于个性化推荐、智能客服等领域,通过高效微调来适应不同的用户需求和场景。
📄 摘要(原文)
Low-rank adapters have become standard for efficiently fine-tuning large language models, but they often fall short of achieving the performance of full fine-tuning. We propose a method, LoRA Silver Bullet or LoRA-SB, that approximates full fine-tuning within low-rank subspaces using a carefully designed initialization strategy. We theoretically demonstrate that the architecture of LoRA-XS, which inserts a learnable r x r matrix between B and A while keeping other matrices fixed, provides the precise conditions needed for this approximation. We leverage its constrained update space to achieve optimal scaling for high-rank gradient updates while removing the need for scaling factor tuning. We prove that our initialization offers an optimal low-rank approximation of the initial gradient and preserves update directions throughout training. Extensive experiments across mathematical reasoning, commonsense reasoning, and language understanding tasks demonstrate that our approach exceeds the performance of LoRA (and baselines) while using 27-90 times fewer learnable parameters, and comprehensively outperforms LoRA-XS. Our findings establish that it is possible to simulate full fine-tuning in low-rank subspaces, and achieve significant parameter efficiency gains without sacrificing performance. Our code is publicly available at: https://github.com/CERT-Lab/lora-sb.