Provable Scaling Laws for the Test-Time Compute of Large Language Models
作者: Yanxi Chen, Xuchen Pan, Yaliang Li, Bolin Ding, Jingren Zhou
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-29 (更新: 2025-10-28)
备注: NeurIPS 2025 camera-ready version
💡 一句话要点
提出两种可证明扩展法则的算法,提升大语言模型测试时计算效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 测试时计算 扩展法则 淘汰赛算法 联赛算法
📋 核心要点
- 现有大语言模型在测试时计算效率较低,需要探索更有效的推理方法。
- 提出两种基于多候选解聚合的算法,分别是淘汰赛式和联赛式,提升了解的质量。
- 实验验证了算法的有效性,证明了其失败概率随着计算量的增加呈指数或幂律衰减。
📝 摘要(中文)
本文提出了两种简单、有原则且实用的算法,它们在大语言模型(LLM)的测试时计算方面具有可证明的扩展法则。第一种是两阶段淘汰赛式算法:给定一个输入问题,它首先生成多个候选解决方案,然后通过淘汰赛的方式聚合这些方案以获得最终输出。假设LLM能够以非零概率生成正确的解决方案,并且在比较正确和不正确的解决方案时优于随机猜测,我们从理论上证明,随着测试时计算量的增加,该算法的失败概率会呈指数或幂律(取决于具体的扩展方式)衰减至零。第二种是两阶段联赛式算法,其中每个候选方案通过其对抗多个对手的平均胜率进行评估,而不是在输给单个对手后就被淘汰。在类似但更稳健的假设下,我们证明其失败概率也会随着更多测试时计算量的增加而呈指数衰减至零。这两种算法都需要一个黑盒LLM,而不需要其他任何东西(例如,验证器或奖励模型)来实现最小化实现,这使得它们对实际应用具有吸引力,并且易于适应不同的任务。通过对各种模型和数据集进行的大量实验,我们验证了所提出的理论,并证明了两种算法的出色扩展特性。
🔬 方法详解
问题定义:论文旨在解决大语言模型在测试阶段计算效率低下的问题。现有方法通常依赖于单个模型的单次推理,无法充分利用模型的潜力,并且容易受到模型自身不确定性的影响。因此,如何利用有限的计算资源,更有效地提升LLM在测试时的性能是一个关键挑战。
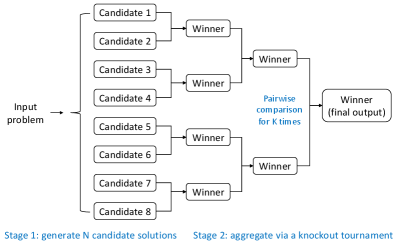
核心思路:论文的核心思路是通过生成多个候选解,然后利用某种聚合策略从这些候选解中选择或组合出最佳答案。这种方法类似于集成学习的思想,通过集思广益来提高最终结果的鲁棒性和准确性。淘汰赛式和联赛式算法是两种不同的聚合策略,分别模拟了体育比赛中的淘汰赛和联赛机制。
技术框架:两种算法都包含两个主要阶段:候选解生成阶段和候选解聚合阶段。在候选解生成阶段,LLM被用来生成多个可能的解决方案。在候选解聚合阶段,淘汰赛式算法通过两两比较,逐步淘汰较差的解,直到剩下最终的解;联赛式算法则通过计算每个候选解的平均胜率来评估其质量,并选择胜率最高的解。
关键创新:论文的关键创新在于提出了两种简单而有效的聚合策略,并从理论上证明了它们具有可证明的扩展法则。这意味着随着测试时计算量的增加(即生成的候选解数量增加),算法的性能会以可预测的方式提升。此外,算法只需要一个黑盒LLM,不需要额外的验证器或奖励模型,降低了实现的复杂度。
关键设计:淘汰赛式算法的关键设计在于如何进行两两比较。论文假设LLM在比较正确和不正确的解决方案时优于随机猜测。联赛式算法的关键设计在于如何选择对手以及如何计算胜率。论文使用平均胜率作为评估候选解质量的指标。两种算法都没有引入额外的参数或复杂的网络结构,而是专注于如何更好地利用现有的LLM能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,两种算法都具有出色的扩展特性。随着测试时计算量的增加,算法的失败概率呈指数或幂律衰减。在多个数据集和模型上的实验都验证了理论预测,并且两种算法在性能上都优于基线方法。例如,在某些任务上,通过增加候选解的数量,可以将模型的准确率提升显著。
🎯 应用场景
该研究成果可广泛应用于各种需要大语言模型进行推理的任务中,例如问答系统、文本生成、代码生成等。通过增加测试时的计算量,可以在不改变模型结构的情况下显著提升模型的性能,从而降低部署成本,提高用户体验。该方法尤其适用于对准确性要求较高的场景。
📄 摘要(原文)
We propose two simple, principled and practical algorithms that enjoy provable scaling laws for the test-time compute of large language models (LLMs). The first one is a two-stage knockout-style algorithm: given an input problem, it first generates multiple candidate solutions, and then aggregate them via a knockout tournament for the final output. Assuming that the LLM can generate a correct solution with non-zero probability and do better than a random guess in comparing a pair of correct and incorrect solutions, we prove theoretically that the failure probability of this algorithm decays to zero exponentially or by a power law (depending on the specific way of scaling) as its test-time compute grows. The second one is a two-stage league-style algorithm, where each candidate is evaluated by its average win rate against multiple opponents, rather than eliminated upon loss to a single opponent. Under analogous but more robust assumptions, we prove that its failure probability also decays to zero exponentially with more test-time compute. Both algorithms require a black-box LLM and nothing else (e.g., no verifier or reward model) for a minimalistic implementation, which makes them appealing for practical applications and easy to adapt for different tasks. Through extensive experiments with diverse models and datasets, we validate the proposed theories and demonstrate the outstanding scaling properties of both algorithms.