Zero-shot Slot Filling in the Age of LLMs for Dialogue Systems
作者: Mansi Rana, Kadri Hacioglu, Sindhuja Gopalan, Maragathamani Boothalingam
分类: cs.CL
发布日期: 2024-11-28
备注: To appear in Proceedings of COLING 2025
💡 一句话要点
针对对话系统,提出基于LLM零样本槽填充方法,提升对话场景下的性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 零样本学习 槽填充 对话系统 大型语言模型 知识蒸馏
📋 核心要点
- 现有零样本槽填充方法难以应对对话数据中主题转换、中断和隐式引用等复杂情况。
- 提出利用自动数据标注和黑盒知识蒸馏策略,将大型语言模型的知识迁移到小型模型。
- 实验结果表明,该方法在内部数据集和呼叫中心场景下均显著优于现有方法。
📝 摘要(中文)
零样本槽填充是自然语言理解(NLU)中一个成熟的子任务。然而,现有方法主要关注单轮文本数据,忽略了会话对话的复杂性。会话数据具有高度动态性,常包含突发的主题转换、中断和隐式引用,这使得即使是大型语言模型(LLM)也难以直接应用零样本槽填充技术。本文通过提出自动数据标注策略(包括槽归纳)以及从教师LLM到小型模型的黑盒知识蒸馏(KD)来解决这些挑战,在内部数据集上,F1值绝对提升了26%,优于直接使用LLM。此外,我们还引入了一种高效的系统架构,用于呼叫中心产品设置,其F1值相对提升了34%,超过了现成的抽取模型,从而能够在保持低延迟的同时,以更高的准确率对对话流进行近实时推理。
🔬 方法详解
问题定义:论文旨在解决对话系统中零样本槽填充的问题。现有方法主要针对单轮文本数据,无法有效处理对话数据中常见的复杂情况,例如主题突变、用户打断和隐式指代等。直接使用大型语言模型(LLM)进行零样本槽填充,虽然具备一定的能力,但在对话场景下的性能仍然有待提升。
核心思路:论文的核心思路是利用大型语言模型(LLM)的强大能力,通过自动数据标注和知识蒸馏,训练一个更小、更高效的模型,使其能够更好地适应对话场景下的零样本槽填充任务。通过自动标注,可以生成大量的训练数据,弥补零样本学习的不足。知识蒸馏则可以将LLM的知识迁移到小型模型,提高其性能和效率。
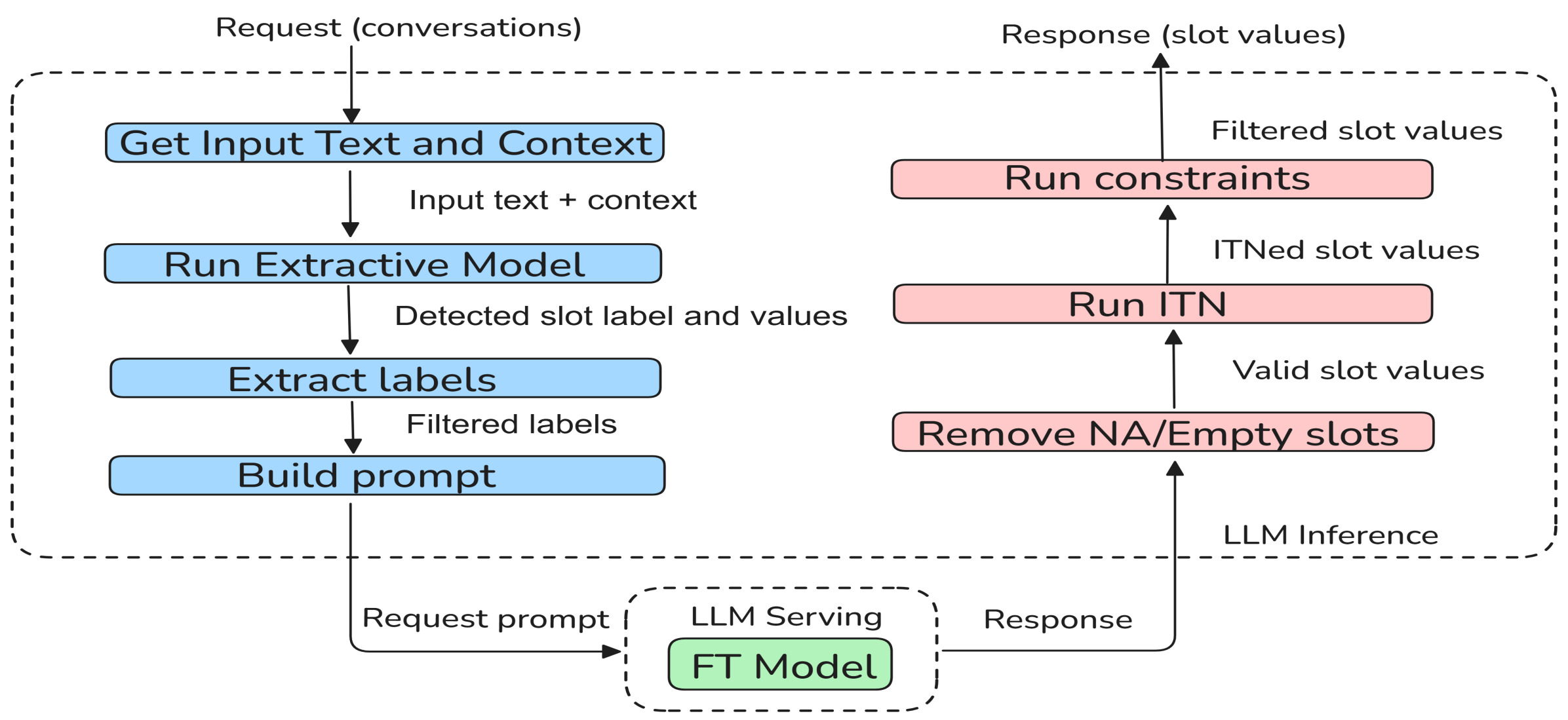
技术框架:整体框架包含以下几个主要阶段:1) 自动数据标注:利用LLM进行槽归纳,自动生成带有槽标注的对话数据。2) 知识蒸馏:将LLM作为教师模型,小型模型作为学生模型,通过黑盒知识蒸馏,将LLM的知识迁移到小型模型。3) 模型训练:使用自动标注的数据和知识蒸馏的信号,训练小型模型。4) 系统部署:针对呼叫中心场景,设计高效的系统架构,实现近实时推理。
关键创新:论文的关键创新在于结合了自动数据标注和黑盒知识蒸馏,有效地利用了LLM的知识,并将其迁移到小型模型,从而在对话场景下的零样本槽填充任务中取得了显著的性能提升。此外,针对呼叫中心场景,论文还提出了高效的系统架构,实现了低延迟的近实时推理。
关键设计:自动数据标注阶段,论文可能使用了特定的prompt工程技术,引导LLM进行准确的槽归纳。知识蒸馏阶段,可能采用了特定的损失函数,例如KL散度,来衡量学生模型和教师模型输出之间的差异。针对呼叫中心场景,系统架构可能采用了流式处理技术,例如Kafka,来实现低延迟的数据传输和处理。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在内部数据集上,F1值绝对提升了26%,优于直接使用LLM。在呼叫中心产品设置中,该方法相对提升了34%的F1值,超过了现成的抽取模型,同时保持了低延迟,实现了近实时推理。这些结果表明,该方法在对话场景下的零样本槽填充任务中具有显著的优势。
🎯 应用场景
该研究成果可广泛应用于智能客服、虚拟助手、对话机器人等领域。通过零样本槽填充技术,系统能够理解用户意图,提取关键信息,从而提供更精准、更个性化的服务。在呼叫中心场景下,可以实现自动化的信息提取和工单生成,提高工作效率,降低运营成本。未来,该技术有望进一步拓展到更多对话式应用场景。
📄 摘要(原文)
Zero-shot slot filling is a well-established subtask of Natural Language Understanding (NLU). However, most existing methods primarily focus on single-turn text data, overlooking the unique complexities of conversational dialogue. Conversational data is highly dynamic, often involving abrupt topic shifts, interruptions, and implicit references that make it difficult to directly apply zero-shot slot filling techniques, even with the remarkable capabilities of large language models (LLMs). This paper addresses these challenges by proposing strategies for automatic data annotation with slot induction and black-box knowledge distillation (KD) from a teacher LLM to a smaller model, outperforming vanilla LLMs on internal datasets by 26% absolute increase in F1 score. Additionally, we introduce an efficient system architecture for call center product settings that surpasses off-the-shelf extractive models by 34% relative F1 score, enabling near real-time inference on dialogue streams with higher accuracy, while preserving low latency.