ScratchEval: Are GPT-4o Smarter than My Child? Evaluating Large Multimodal Models with Visual Programming Challenges
作者: Rao Fu, Ziyang Luo, Hongzhan Lin, Zhen Ye, Jing Ma
分类: cs.CL, cs.AI, cs.CV
发布日期: 2024-11-28
🔗 代码/项目: GITHUB
💡 一句话要点
提出 ScratchEval 基准,评估大模型在视觉编程中的推理能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉编程 多模态模型 基准测试 逻辑推理 代码生成
📋 核心要点
- 现有图像到代码的基准测试无法充分评估 LMMs 在视觉编程中统一的逻辑推理和多模态理解能力。
- ScratchEval 通过整合视觉元素和编程逻辑,要求模型同时处理视觉信息和代码结构,评估编程意图理解能力。
- ScratchEval 提供了一个更全面和更具挑战性的框架,为 LMMs 在视觉编程领域的发展提供新的评估视角。
📝 摘要(中文)
本文提出 ScratchEval,一个用于评估大型多模态模型(LMMs)视觉编程推理能力的新基准。现有基准主要通过图像到代码的转换来评估 LMMs 的代码生成能力,但忽略了逻辑推理和多模态理解的统一性。ScratchEval 基于 Scratch 语言,一种广泛应用于儿童编程教育的块状视觉编程语言。通过整合视觉元素和嵌入式编程逻辑,ScratchEval 要求模型同时处理视觉信息和代码结构,从而全面评估其对编程意图的理解能力。该评估方法超越了传统的图像到代码的映射,侧重于统一的逻辑思维和问题解决能力,为评估 LMMs 的视觉编程能力提供了一个更全面和更具挑战性的框架。ScratchEval 不仅填补了现有评估方法的空白,也为 LMMs 在视觉编程领域的未来发展提供了新的见解。
🔬 方法详解
问题定义:现有的大型多模态模型(LMMs)在代码生成方面取得了显著进展,但现有的评估基准主要集中在图像到代码的转换上,缺乏对视觉编程中逻辑推理和多模态理解能力的综合评估。这些基准往往将视觉信息处理和代码逻辑推理割裂开来,无法真实反映模型在解决复杂视觉编程问题时的能力。因此,需要一种新的基准来更全面地评估 LMMs 在视觉编程领域的推理能力。
核心思路:ScratchEval 的核心思路是利用 Scratch 这种块状视觉编程语言,创建一个同时包含视觉元素和嵌入式编程逻辑的评估环境。通过要求模型理解视觉场景并生成相应的 Scratch 代码,从而综合评估其视觉理解、逻辑推理和代码生成能力。这种设计能够更真实地模拟实际的视觉编程场景,并更有效地评估模型对编程意图的理解能力。
技术框架:ScratchEval 的整体框架包括以下几个主要部分:首先,构建一个包含各种视觉编程任务的数据集,每个任务都包含一个视觉场景描述和一个对应的 Scratch 代码解决方案。其次,设计一个评估流程,将视觉场景描述输入到 LMMs 中,并要求其生成 Scratch 代码。最后,通过比较生成的代码和标准答案,评估模型的性能。该框架的关键在于数据集的设计,需要确保数据集的多样性和复杂性,以充分评估模型的各种能力。
关键创新:ScratchEval 的最重要创新点在于它将视觉信息和编程逻辑紧密结合,创造了一个更具挑战性和综合性的评估环境。与现有的图像到代码基准相比,ScratchEval 不仅要求模型能够识别图像中的物体,还需要理解物体之间的关系以及如何通过编程来实现特定的功能。这种设计能够更有效地评估模型在视觉编程领域的推理能力。
关键设计:ScratchEval 的关键设计包括:1) 数据集的多样性,涵盖各种视觉编程任务,例如动画、游戏和交互式应用;2) 评估指标的全面性,不仅考虑代码的正确性,还考虑代码的效率和可读性;3) 评估流程的自动化,能够快速评估大量模型的性能。此外,ScratchEval 还提供了一个开源的评估工具包,方便研究人员使用和扩展。
🖼️ 关键图片

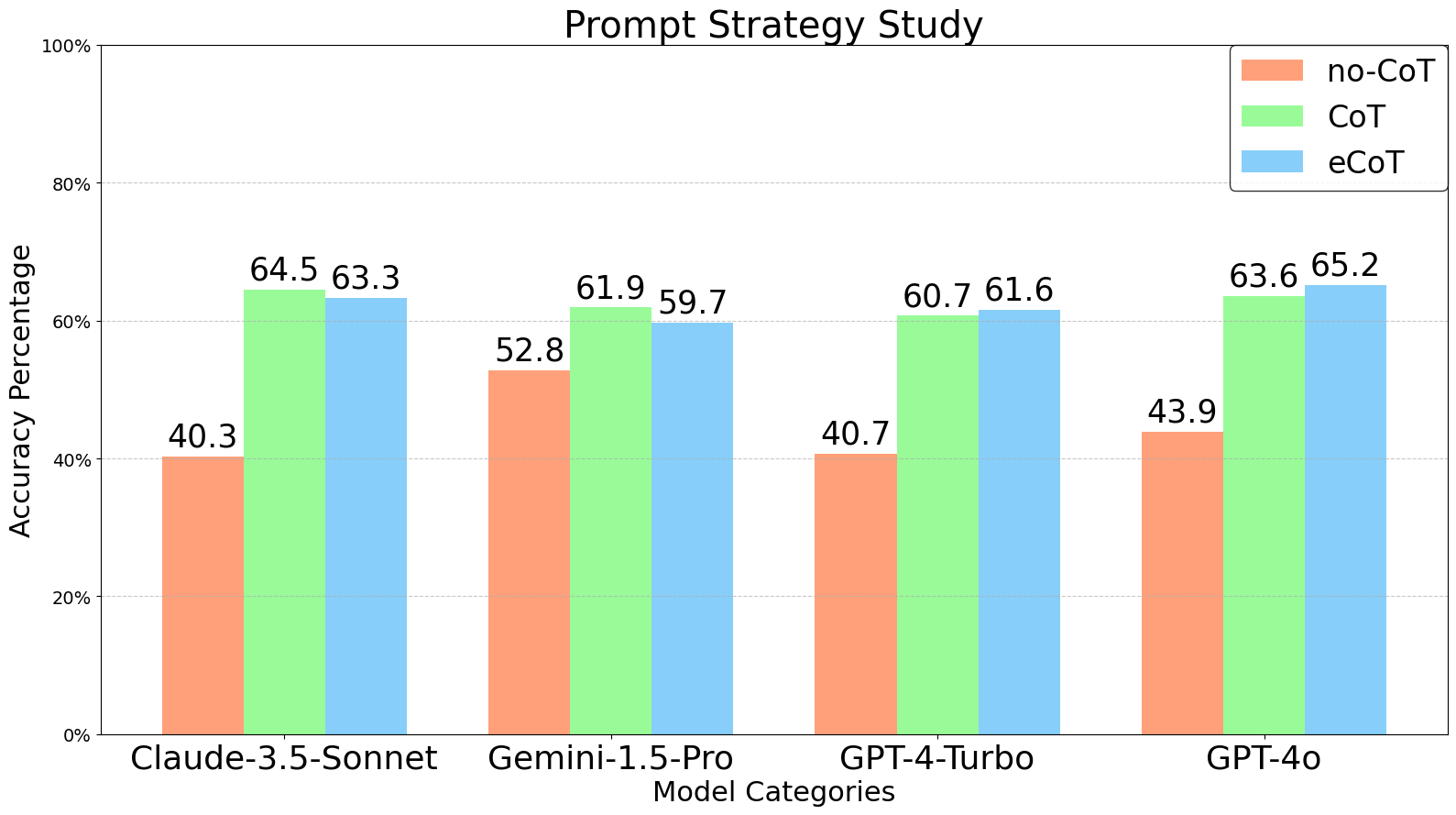

📊 实验亮点
ScratchEval 基准测试表明,即使是 GPT-4o 这样的先进模型,在解决复杂的视觉编程问题时仍然面临挑战。该基准的推出,为未来 LMMs 在视觉编程领域的发展指明了方向,并提供了一个客观的评估平台。
🎯 应用场景
ScratchEval 可用于评估和改进大型多模态模型在视觉编程领域的应用,例如智能教育、机器人控制和自动化设计。通过提高模型在视觉编程方面的能力,可以开发出更智能、更易用的编程工具,降低编程门槛,促进人工智能技术在各个领域的应用。
📄 摘要(原文)
Recent advancements in large multimodal models (LMMs) have showcased impressive code generation capabilities, primarily evaluated through image-to-code benchmarks. However, these benchmarks are limited to specific visual programming scenarios where the logic reasoning and the multimodal understanding capacities are split apart. To fill this gap, we propose ScratchEval, a novel benchmark designed to evaluate the visual programming reasoning ability of LMMs. ScratchEval is based on Scratch, a block-based visual programming language widely used in children's programming education. By integrating visual elements and embedded programming logic, ScratchEval requires the model to process both visual information and code structure, thereby comprehensively evaluating its programming intent understanding ability. Our evaluation approach goes beyond the traditional image-to-code mapping and focuses on unified logical thinking and problem-solving abilities, providing a more comprehensive and challenging framework for evaluating the visual programming ability of LMMs. ScratchEval not only fills the gap in existing evaluation methods, but also provides new insights for the future development of LMMs in the field of visual programming. Our benchmark can be accessed at https://github.com/HKBUNLP/ScratchEval .