AMPS: ASR with Multimodal Paraphrase Supervision
作者: Abhishek Gupta, Amruta Parulekar, Sameep Chattopadhyay, Preethi Jyothi
分类: cs.CL, cs.AI, cs.LG, eess.AS
发布日期: 2024-11-27 (更新: 2025-04-16)
💡 一句话要点
AMPS:利用多模态复述监督提升多语言会话语音识别性能
🎯 匹配领域: 支柱八:物理动画 (Physics-based Animation) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言语音识别 复述监督 多模态学习 会话语音 低资源语言
📋 核心要点
- 现有语音识别系统在处理自发或会话式多语言语音时面临诸多挑战,例如口音、语速和噪声。
- AMPS方法利用参考转录的复述作为额外的监督信号,选择性地应用于识别效果不佳的语句,从而提升模型性能。
- 实验结果表明,AMPS与SeamlessM4T结合使用,在多种语言的语音识别任务中,词错误率显著降低,最高可达5%。
📝 摘要(中文)
本文提出了一种名为AMPS的新技术,旨在通过复述监督来增强多语言多模态自动语音识别(ASR)系统,从而改善包括印地语、马拉地语、马拉雅拉姆语、卡纳达语和尼扬加语在内的多种语言的会话ASR性能。AMPS在训练多模态ASR模型时,将参考转录的复述作为额外的监督信息,并有选择地对ASR性能较差的语句应用这种复述目标。通过将AMPS与最先进的多模态模型SeamlessM4T结合使用,在词错误率(WER)方面获得了高达5%的显著相对降低。本文还使用客观和主观评估指标对系统进行了详细分析。
🔬 方法详解
问题定义:论文旨在解决多语言会话语音识别中,现有ASR系统性能不佳的问题。现有的ASR系统在处理自发性强、口语化的多语言语音时,容易受到口音、语速变化、背景噪声等因素的影响,导致识别准确率下降。此外,数据稀缺也是一个挑战,特别是对于低资源语言。
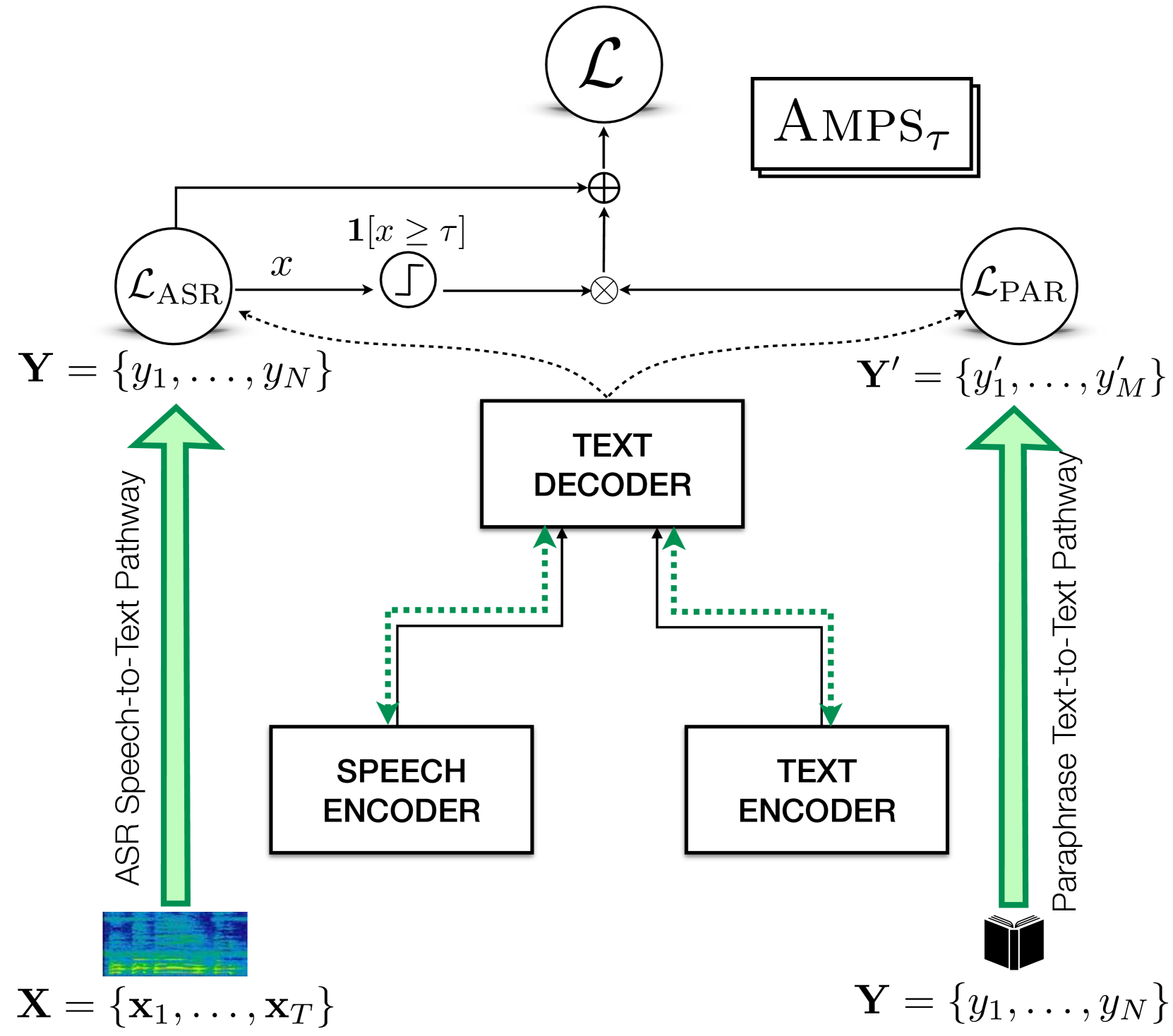
核心思路:论文的核心思路是利用参考转录的复述(paraphrase)作为额外的监督信息来增强ASR模型的训练。复述提供了同一语义的不同表达方式,可以帮助模型更好地学习语音和文本之间的映射关系,提高模型的鲁棒性和泛化能力。通过选择性地对识别效果不佳的语句应用复述监督,可以更有效地利用复述数据,避免对模型造成负面影响。
技术框架:AMPS方法基于一个多模态ASR系统,例如SeamlessM4T。训练过程中,除了使用原始的语音和文本数据外,还引入了参考转录的复述。具体流程如下: 1. 使用原始语音和文本数据训练ASR模型。 2. 对于每个语音片段,计算ASR模型的置信度得分或错误率。 3. 如果置信度得分低于某个阈值,则将该语音片段的参考转录的复述作为额外的监督信息。 4. 使用原始数据和复述数据共同训练ASR模型。
关键创新:AMPS的关键创新在于引入了复述监督,并采用选择性应用策略。与直接使用原始数据训练ASR模型相比,AMPS可以利用复述数据提供的额外信息来提高模型的性能。与对所有语句都应用复述监督相比,选择性应用策略可以更有效地利用复述数据,避免对模型造成负面影响。这种选择性应用是基于模型自身对语音片段的识别置信度。
关键设计:论文中,复述数据的生成方式未知,但可以采用多种方法,例如机器翻译、回译或人工标注。选择性应用策略的关键在于确定置信度阈值。阈值的选择需要根据具体的数据集和模型进行调整。损失函数方面,可以使用交叉熵损失函数或连接时序分类(CTC)损失函数。网络结构方面,可以使用Transformer或Conformer等常用的ASR模型结构。
🖼️ 关键图片
📊 实验亮点
实验结果表明,AMPS与最先进的多模态模型SeamlessM4T结合使用,在包括印地语、马拉地语、马拉雅拉姆语、卡纳达语和尼扬加语在内的多种语言的语音识别任务中,词错误率(WER)显著降低,最高可达5%。这表明AMPS方法能够有效地提高多语言会话语音识别的性能。
🎯 应用场景
AMPS技术可应用于各种多语言语音识别场景,例如多语言客服系统、语音助手、会议记录等。该技术能够提高在嘈杂环境或口音差异下的语音识别准确率,从而改善用户体验。此外,AMPS方法还可以应用于低资源语言的语音识别任务,通过复述数据来增强模型的训练。
📄 摘要(原文)
Spontaneous or conversational multilingual speech presents many challenges for state-of-the-art automatic speech recognition (ASR) systems. In this work, we present a new technique AMPS that augments a multilingual multimodal ASR system with paraphrase-based supervision for improved conversational ASR in multiple languages, including Hindi, Marathi, Malayalam, Kannada, and Nyanja. We use paraphrases of the reference transcriptions as additional supervision while training the multimodal ASR model and selectively invoke this paraphrase objective for utterances with poor ASR performance. Using AMPS with a state-of-the-art multimodal model SeamlessM4T, we obtain significant relative reductions in word error rates (WERs) of up to 5%. We present detailed analyses of our system using both objective and human evaluation metrics.