Neutralizing Backdoors through Information Conflicts for Large Language Models
作者: Chen Chen, Yuchen Sun, Xueluan Gong, Jiaxin Gao, Kwok-Yan Lam
分类: cs.CL
发布日期: 2024-11-27
💡 一句话要点
提出基于信息冲突的大语言模型后门防御方法,有效消除恶意行为。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 后门攻击防御 信息冲突 模型安全 对抗性攻击
📋 核心要点
- 现有后门防御方法在大型语言模型中存在不足,无法有效应对高级攻击,且依赖于对触发器的严格假设。
- 该论文提出通过构建内部和外部信息冲突来消除LLM中的后门行为,从而中和恶意行为。
- 实验结果表明,该方法在降低攻击成功率和保持清洁数据准确率方面优于现有技术,并对自适应攻击具有鲁棒性。
📝 摘要(中文)
大型语言模型(LLMs)在自然语言处理(NLP)任务中取得了显著进展,但在后门攻击面前仍然脆弱。后门攻击指模型在正常查询下表现良好,但在特定触发器激活时产生有害响应或意外输出。现有的后门防御方法通常存在缺陷,例如侧重于检测而非移除、依赖于对触发器属性的严格假设,或对高级攻击(如多触发器后门)无效。本文提出了一种新方法,通过构建内部和外部的信息冲突来消除LLM中的后门行为。在内部,我们利用轻量级数据集训练冲突模型,然后将其与后门模型合并,通过在模型的参数记忆中嵌入矛盾信息来中和恶意行为。在外部,我们将令人信服的矛盾证据纳入提示中,以挑战模型内部的后门知识。在4个广泛使用的LLM上的分类和对话任务的实验结果表明,我们的方法优于8个最先进的后门防御基线。我们能够将高级后门攻击的攻击成功率降低高达98%,同时保持超过90%的干净数据准确率。此外,我们的方法已被证明对自适应后门攻击具有鲁棒性。代码将在发布后开源。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中后门攻击的防御问题。现有的防御方法存在以下痛点:一是侧重于检测,无法有效移除后门;二是依赖于对触发器属性的先验知识,对未知或复杂的触发器无效;三是在面对高级攻击(如多触发器后门)时效果不佳。
核心思路:论文的核心思路是通过构建信息冲突来消除后门行为。具体而言,通过在模型内部嵌入矛盾信息,以及在外部提示中引入矛盾证据,来挑战和削弱模型对后门触发器的响应。这种方法不依赖于对触发器的具体了解,而是通过制造认知失调来抑制后门行为。
技术框架:该方法包含两个主要组成部分:内部冲突构建和外部冲突构建。内部冲突构建涉及训练一个冲突模型,该模型学习与后门模型行为相矛盾的信息。然后,将冲突模型与后门模型合并,从而在模型的参数记忆中嵌入矛盾信息。外部冲突构建则是在输入提示中加入与后门触发器相关的矛盾信息,以挑战模型内部的后门知识。
关键创新:该方法的关键创新在于利用信息冲突来中和后门行为,而不是依赖于检测和移除触发器。这种方法具有更强的泛化能力和鲁棒性,可以有效应对各种类型的后门攻击,包括高级攻击和自适应攻击。此外,该方法不需要对触发器属性进行假设,因此更具实用性。
关键设计:内部冲突构建的关键在于选择合适的冲突数据集和训练策略。论文使用轻量级数据集,并采用特定的训练目标,以确保冲突模型能够有效地干扰后门模型的行为,同时保持对干净数据的良好性能。外部冲突构建的关键在于设计有效的矛盾提示,这些提示需要足够令人信服,才能挑战模型内部的后门知识。具体的参数设置和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片


📊 实验亮点
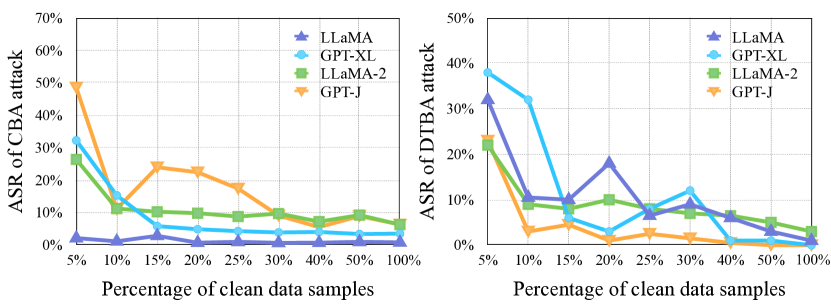
实验结果表明,该方法在四个广泛使用的LLM上优于八个最先进的后门防御基线。该方法能够将高级后门攻击的攻击成功率降低高达98%,同时保持超过90%的清洁数据准确率。此外,该方法对自适应后门攻击具有鲁棒性,表明其具有良好的泛化能力。
🎯 应用场景
该研究成果可应用于提升大型语言模型在各种实际应用场景中的安全性,例如智能客服、文本生成、机器翻译等。通过有效防御后门攻击,可以防止模型被恶意利用,保障用户的信息安全和系统稳定。该方法还有助于提高LLM的可信度和可靠性,促进其在更广泛领域的应用。
📄 摘要(原文)
Large language models (LLMs) have seen significant advancements, achieving superior performance in various Natural Language Processing (NLP) tasks, from understanding to reasoning. However, they remain vulnerable to backdoor attacks, where models behave normally for standard queries but generate harmful responses or unintended output when specific triggers are activated. Existing backdoor defenses often suffer from drawbacks that they either focus on detection without removal, rely on rigid assumptions about trigger properties, or prove to be ineffective against advanced attacks like multi-trigger backdoors. In this paper, we present a novel method to eliminate backdoor behaviors from LLMs through the construction of information conflicts using both internal and external mechanisms. Internally, we leverage a lightweight dataset to train a conflict model, which is then merged with the backdoored model to neutralize malicious behaviors by embedding contradictory information within the model's parametric memory. Externally, we incorporate convincing contradictory evidence into the prompt to challenge the model's internal backdoor knowledge. Experimental results on classification and conversational tasks across 4 widely used LLMs demonstrate that our method outperforms 8 state-of-the-art backdoor defense baselines. We can reduce the attack success rate of advanced backdoor attacks by up to 98% while maintaining over 90% clean data accuracy. Furthermore, our method has proven to be robust against adaptive backdoor attacks. The code will be open-sourced upon publication.