JPPO: Joint Power and Prompt Optimization for Accelerated Large Language Model Services
作者: Feiran You, Hongyang Du, Kaibin Huang, Abbas Jamalipour
分类: eess.AS, cs.CL, cs.SD
发布日期: 2024-11-27 (更新: 2025-02-22)
💡 一句话要点
提出JPPO框架以解决大语言模型服务中的资源优化问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 提示压缩 功率优化 深度强化学习 无线通信 资源效率 服务质量
📋 核心要点
- 随着大语言模型的应用,计算资源需求和通信负载问题日益突出,现有方法难以满足高效服务的需求。
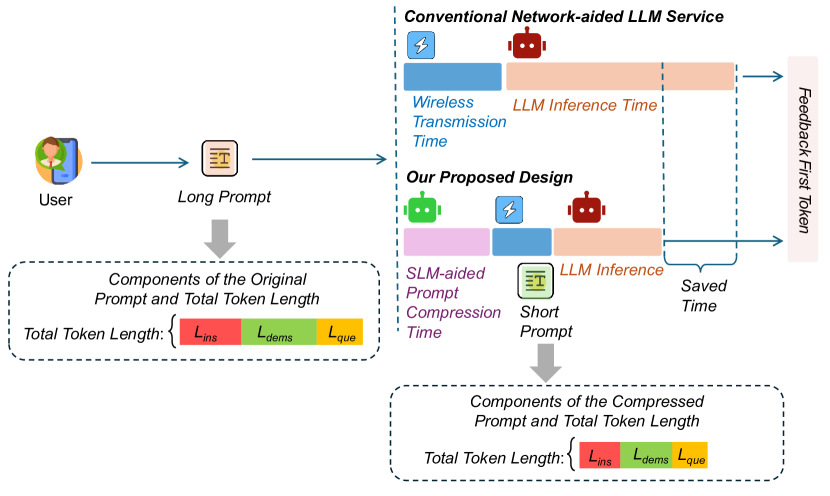
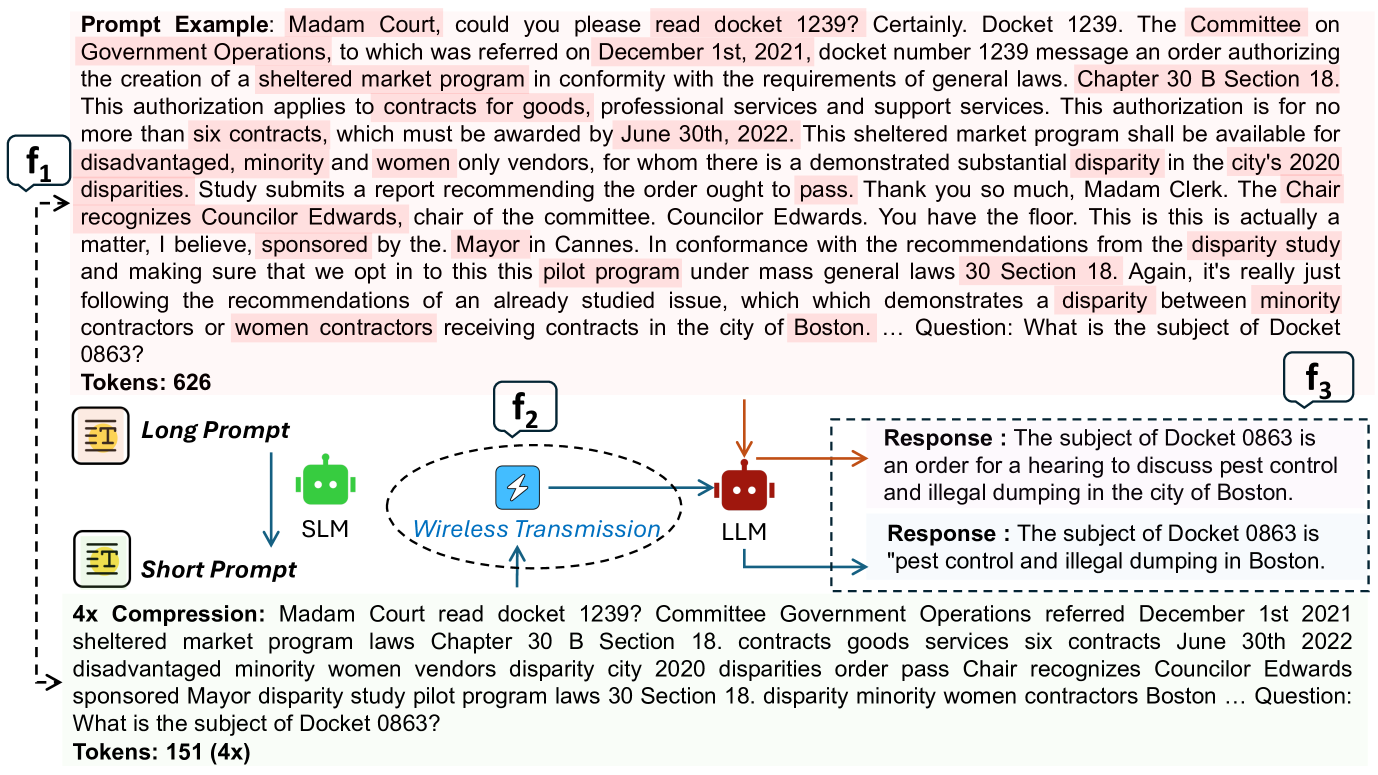
- 本文提出JPPO框架,通过SLM进行提示压缩,并结合深度强化学习优化功率分配,实现资源的高效利用。
- 实验结果显示,JPPO在服务保真度和比特错误率方面表现优异,响应时间平均减少17%,提升效果显著。
📝 摘要(中文)
大语言模型(LLMs)在多种任务中展现出卓越的能力,逐渐被广泛应用于无线网络中的多种用户服务。然而,随着提示长度的增加,计算资源需求和通信负载问题日益突出。为此,本文提出了联合功率与提示优化(JPPO)框架,结合基于小语言模型(SLM)的提示压缩与无线功率分配优化。通过在用户设备上部署SLM进行提示压缩,并采用深度强化学习实现压缩比与传输功率的联合优化,JPPO有效平衡了服务质量与资源效率。实验结果表明,该框架在优化无线LLM服务的功率使用的同时,实现了高服务保真度和低比特错误率,响应时间减少约17%。
🔬 方法详解
问题定义:本文旨在解决大语言模型服务中因提示长度增加而导致的计算资源需求和通信负载过高的问题。现有方法在资源利用效率和服务质量之间存在矛盾,难以满足实际应用需求。
核心思路:JPPO框架通过结合小语言模型(SLM)进行提示压缩与无线功率分配优化,利用深度强化学习实现压缩比和传输功率的联合优化,从而有效提升资源利用效率。
技术框架:JPPO框架主要包括两个模块:一是用户设备上的SLM进行提示压缩,二是通过深度强化学习算法优化无线功率分配。整体流程为:首先进行提示压缩,然后根据压缩后的提示优化功率分配。
关键创新:JPPO的核心创新在于将提示压缩与功率优化进行联合考虑,利用深度强化学习实现两者的动态平衡,这在现有方法中尚属首次。
关键设计:在设计中,SLM的压缩比和传输功率的优化目标通过特定的损失函数进行平衡,网络结构采用了适应性调整机制,以适应不同长度的提示和无线环境。具体参数设置和网络结构细节在实验部分进行了详细说明。
🖼️ 关键图片

📊 实验亮点
实验结果表明,JPPO框架在服务保真度和比特错误率方面表现优异,响应时间平均减少约17%。与基线方法相比,JPPO在资源利用效率上有显著提升,尤其是在处理较长提示时,效果更加明显。
🎯 应用场景
该研究的潜在应用领域包括无线通信、智能设备和云计算服务等。通过优化大语言模型的资源使用,JPPO框架能够提升用户体验,降低服务延迟,具有重要的实际价值和广泛的应用前景,尤其是在资源受限的环境中。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable capabilities in various tasks, leading to their increasing deployment in wireless networks for a wide variety of user services. However, the growing longer prompt setting highlights the crucial issue of computational resource demands and huge communication load. To address this challenge, we propose Joint Power and Prompt Optimization (JPPO), a framework that combines Small Language Model (SLM)-based prompt compression with wireless power allocation optimization. By deploying SLM at user devices for prompt compression and employing Deep Reinforcement Learning for joint optimization of compression ratio and transmission power, JPPO effectively balances service quality with resource efficiency. Experimental results demonstrate that our framework achieves high service fidelity and low bit error rates while optimizing power usage in wireless LLM services. The system reduces response time by about 17%, with the improvement varying based on the length of the original prompt.