Enhancing Character-Level Understanding in LLMs through Token Internal Structure Learning
作者: Zhu Xu, Zhiqiang Zhao, Zihan Zhang, Yuchi Liu, Quanwei Shen, Fei Liu, Yu Kuang, Jian He, Conglin Liu
分类: cs.CL
发布日期: 2024-11-26 (更新: 2025-06-09)
备注: ACL 2025 Main
💡 一句话要点
TIPA:通过学习Token内部结构提升LLM的字符级理解能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 字符级理解 Token内部结构 位置预测 中文拼写纠错
📋 核心要点
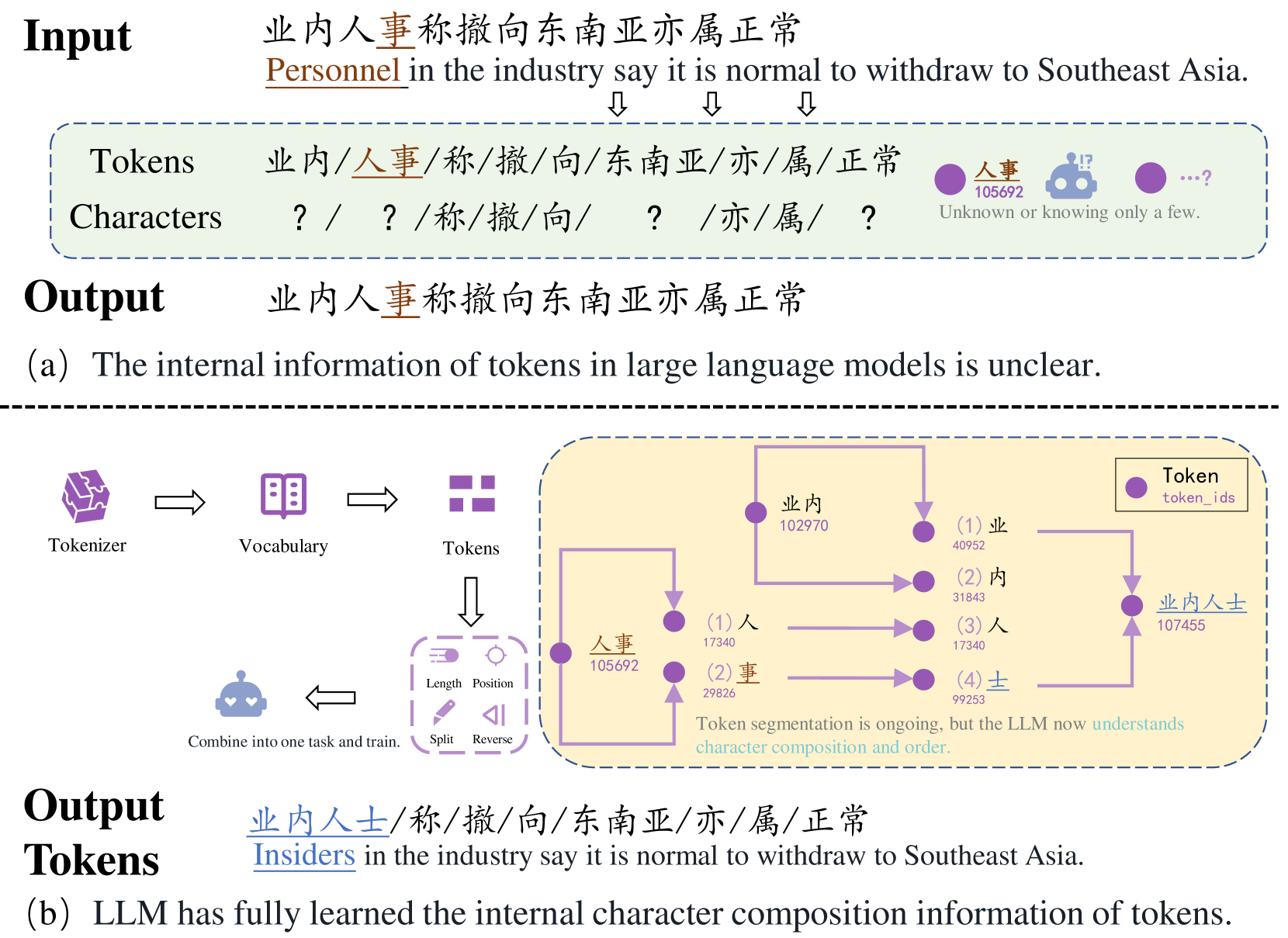
- 现有LLM的分词方法(如BPE)弱化了token内部的字符结构,影响了模型对字符位置的精确预测。
- TIPA通过反向字符预测任务,使LLM学习token内部的字符位置信息,从而增强字符级理解能力。
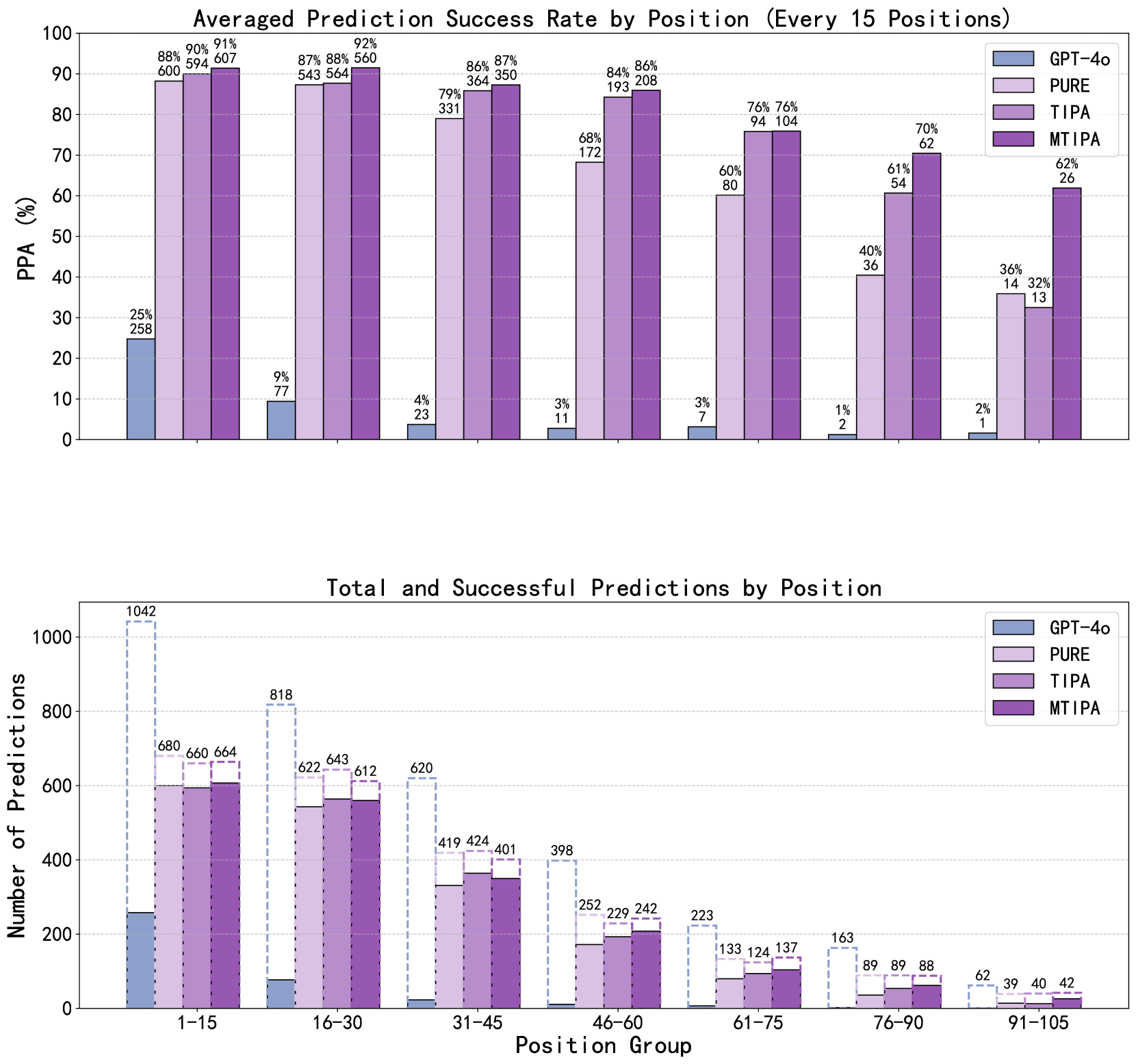
- 实验表明,TIPA提高了LLM在字符位置预测和下游任务中的性能,验证了其有效性和通用性。
📝 摘要(中文)
大型语言模型(LLM)中的Byte-Pair Encoding(BPE)等分词方法虽然提高了计算效率,但常常模糊了token内部的字符结构。这种限制阻碍了LLM预测精确字符位置的能力,这对于中文拼写纠错(CSC)等任务至关重要,因为识别错误字符的位置可以加速纠正过程。我们提出了Token Internal Position Awareness(TIPA),该方法通过使用分词器的词汇表训练模型执行反向字符预测任务,显著提高了模型捕获token内部字符位置的能力。实验表明,TIPA增强了LLM的位置预测准确性,从而能够更精确地识别原始文本中的目标字符。此外,当应用于不需要精确位置预测的下游任务时,TIPA仍然可以提高需要字符级信息的任务的性能,验证了其通用性和有效性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在处理分词后的token时,由于token内部字符结构被模糊化,导致模型难以精确预测字符位置的问题。现有方法无法有效利用token内部的字符信息,限制了LLM在需要字符级理解的任务中的性能,例如中文拼写纠错。
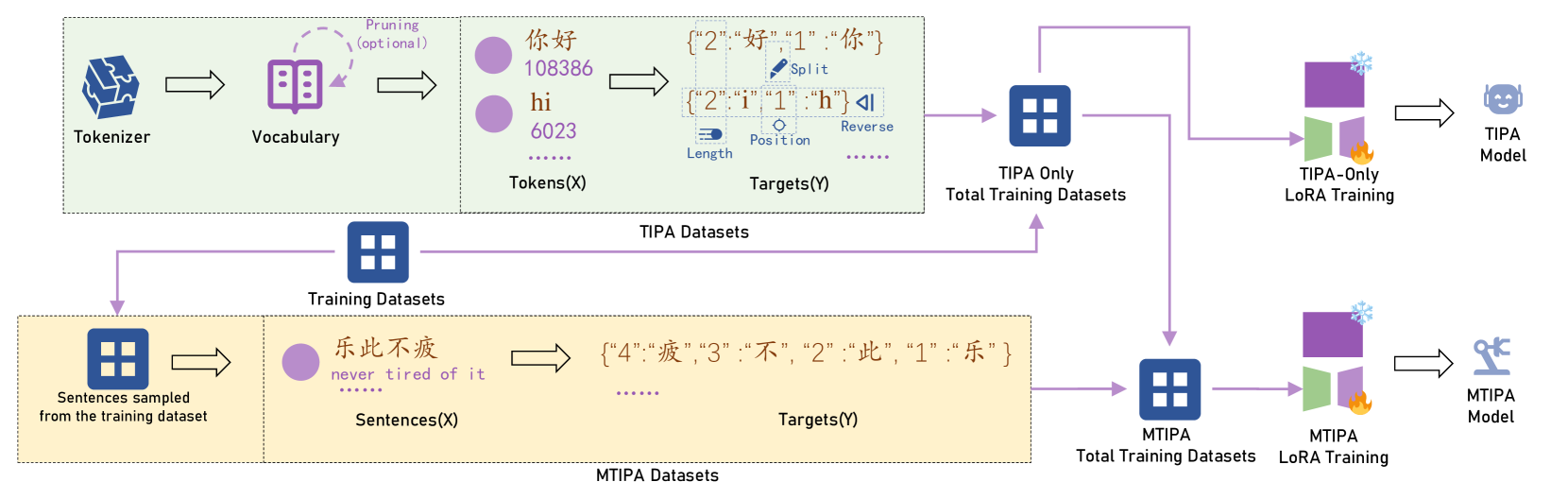
核心思路:论文的核心思路是通过训练LLM学习token内部的字符位置信息,从而增强模型对字符级信息的感知能力。具体而言,通过让模型预测token中每个字符之前的字符,使模型能够理解token内部的字符顺序和位置关系。这样设计的目的是让模型能够更好地利用token内部的字符结构,从而提高字符位置预测的准确性。
技术框架:TIPA方法主要包含以下步骤:1) 使用现有的分词器(如BPE)对文本进行分词;2) 构建反向字符预测任务,即给定token中的一个字符,预测该字符之前的字符;3) 使用分词器的词汇表,训练LLM执行反向字符预测任务;4) 将训练好的LLM应用于下游任务,如中文拼写纠错等。
关键创新:TIPA的关键创新在于它利用了分词器的词汇表,通过反向字符预测任务,显式地训练LLM学习token内部的字符位置信息。与现有方法相比,TIPA不需要修改模型结构或引入额外的参数,而是通过一种简单而有效的方式,增强了LLM对字符级信息的感知能力。
关键设计:在反向字符预测任务中,可以使用交叉熵损失函数来衡量模型的预测结果与真实标签之间的差异。训练过程中,可以调整学习率、batch size等超参数,以获得最佳的训练效果。此外,还可以使用不同的LLM架构(如Transformer)作为基础模型,并根据具体任务的需求进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,TIPA方法显著提高了LLM在字符位置预测任务中的准确性。此外,当应用于中文拼写纠错等下游任务时,TIPA也取得了显著的性能提升,验证了其有效性和通用性。具体性能数据未知,但摘要表明TIPA能够更精确地识别原始文本中的目标字符。
🎯 应用场景
该研究成果可应用于中文拼写纠错、文本校对、机器翻译等领域。通过提高LLM对字符级信息的理解能力,可以提升相关应用的准确性和效率。未来,该方法还可以扩展到其他语言和任务中,为自然语言处理领域的发展做出贡献。
📄 摘要(原文)
Tokenization methods like Byte-Pair Encoding (BPE) enhance computational efficiency in large language models (LLMs) but often obscure internal character structures within tokens. This limitation hinders LLMs' ability to predict precise character positions, which is crucial in tasks like Chinese Spelling Correction (CSC) where identifying the positions of misspelled characters accelerates correction processes. We propose Token Internal Position Awareness (TIPA), a method that significantly improves models' ability to capture character positions within tokens by training them on reverse character prediction tasks using the tokenizer's vocabulary. Experiments demonstrate that TIPA enhances position prediction accuracy in LLMs, enabling more precise identification of target characters in original text. Furthermore, when applied to downstream tasks that do not require exact position prediction, TIPA still boosts performance in tasks needing character-level information, validating its versatility and effectiveness.