How do Multimodal Foundation Models Encode Text and Speech? An Analysis of Cross-Lingual and Cross-Modal Representations
作者: Hyunji Lee, Danni Liu, Supriti Sinhamahapatra, Jan Niehues
分类: cs.CL
发布日期: 2024-11-26 (更新: 2025-02-20)
备注: NAACL 2025
💡 一句话要点
分析多模态模型如何编码文本与语音,揭示跨语言和跨模态表征差异
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 跨语言表征 跨模态表征 语音识别 文本理解 表征分析 深度学习模型
📋 核心要点
- 现有方法在多模态表征学习中,未能充分理解跨语言和跨模态的表征差异,阻碍了模型的泛化能力。
- 该论文通过分析多模态模型内部表征,研究文本和语音在不同语言和模态下的语义等价性,揭示模型编码机制。
- 实验结果表明,跨模态表征随模型层加深而收敛,但语音的跨语言差异大于文本,模态差距比语言差距更显著。
📝 摘要(中文)
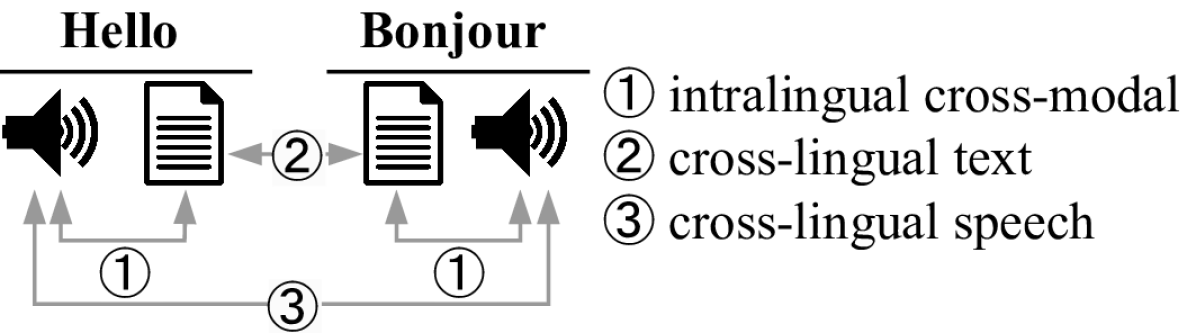
多模态基础模型旨在创建一个统一的表征空间,从而消除诸如语言语法或模态差异等表面特征的影响。为了研究这一点,我们分析了三个最新模型的内部表征,研究了来自文本和语音模态中语义等价句子的模型激活。我们的发现表明:1)跨模态表征在模型层上逐渐收敛,但在专门用于文本和语音处理的初始层中除外。2)长度自适应对于减少文本和语音之间的跨模态差距至关重要,但当前方法的有效性主要限于高资源语言。3)语音表现出比文本更大的跨语言差异。4)对于未明确训练用于模态无关表征的模型,模态差距比语言差距更为突出。
🔬 方法详解
问题定义:现有的多模态基础模型虽然在各种任务上表现出色,但其内部如何编码和处理不同语言和模态的信息仍然是一个黑盒。现有方法缺乏对模型内部表征的深入分析,难以理解模型如何实现跨语言和跨模态的语义对齐。这阻碍了我们对模型能力的理解,也限制了模型在低资源语言和跨模态场景下的泛化能力。
核心思路:该论文的核心思路是通过分析多模态模型在处理语义等价的文本和语音数据时的内部激活,来揭示模型如何编码语言和模态信息。通过比较不同语言和模态下的表征差异,可以了解模型是否以及如何在内部实现跨语言和跨模态的语义对齐。这种分析方法可以帮助我们理解模型的优势和局限性,并为改进模型设计提供指导。
技术框架:该研究的技术框架主要包括以下几个步骤:1)选择三个代表性的多模态基础模型;2)构建包含多种语言和模态(文本和语音)的语义等价句子数据集;3)将数据集输入到模型中,提取不同层的激活值;4)使用各种分析方法(例如,计算表征相似度、可视化等)来比较不同语言和模态下的表征差异。
关键创新:该论文的关键创新在于其分析方法,即通过比较语义等价的文本和语音数据在模型内部的表征差异,来揭示模型的编码机制。这种方法能够深入了解模型如何处理不同语言和模态的信息,并发现模型在跨语言和跨模态语义对齐方面的优势和局限性。与以往主要关注模型性能的研究不同,该论文侧重于理解模型内部的工作原理。
关键设计:论文的关键设计包括:1)选择具有代表性的多模态模型,例如,同时处理文本和语音的模型;2)构建高质量的语义等价句子数据集,确保不同语言和模态下的句子具有相同的语义;3)选择合适的分析方法,例如,使用余弦相似度来衡量表征的相似性,使用可视化技术来展示表征的分布。
🖼️ 关键图片


📊 实验亮点
实验结果表明,跨模态表征在模型深层逐渐收敛,但在浅层存在显著差异,反映了模型对文本和语音的初步处理。长度自适应对减少跨模态差距有帮助,但主要限于高资源语言。语音的跨语言差异大于文本,且对于未明确训练模态无关表征的模型,模态差距比语言差距更明显。
🎯 应用场景
该研究成果可应用于改进多模态基础模型的设计,提升其跨语言和跨模态的泛化能力。例如,可以根据研究结果调整模型的训练策略,使其更好地处理不同语言和模态的差异。此外,该研究还可以应用于开发更有效的跨语言语音识别、机器翻译等应用。
📄 摘要(原文)
Multimodal foundation models aim to create a unified representation space that abstracts away from surface features like language syntax or modality differences. To investigate this, we study the internal representations of three recent models, analyzing the model activations from semantically equivalent sentences across languages in the text and speech modalities. Our findings reveal that: 1) Cross-modal representations converge over model layers, except in the initial layers specialized at text and speech processing. 2) Length adaptation is crucial for reducing the cross-modal gap between text and speech, although current approaches' effectiveness is primarily limited to high-resource languages. 3) Speech exhibits larger cross-lingual differences than text. 4) For models not explicitly trained for modality-agnostic representations, the modality gap is more prominent than the language gap.