Natural Language Understanding and Inference with MLLM in Visual Question Answering: A Survey
作者: Jiayi Kuang, Jingyou Xie, Haohao Luo, Ronghao Li, Zhe Xu, Xianfeng Cheng, Yinghui Li, Xika Lin, Ying Shen
分类: cs.CL, cs.CV
发布日期: 2024-11-26
💡 一句话要点
综述:基于多模态大语言模型在视觉问答中的自然语言理解与推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉问答 多模态大语言模型 自然语言理解 知识推理 视觉-语言预训练 图像理解 文本理解
📋 核心要点
- VQA任务结合了NLP和CV,但现有方法在理解图像和问题中的复杂语义关系方面仍有挑战。
- 该综述全面回顾了VQA领域的发展,重点关注了基于MLLM的自然语言理解和知识推理方法。
- 文章总结了VQA数据集和评估指标,并探讨了未来研究方向,为研究者提供了有价值的参考。
📝 摘要(中文)
本综述旨在全面概述视觉问答(VQA)的发展,并详细介绍最新的模型。VQA是一项结合了自然语言处理和计算机视觉技术的挑战性任务,并逐渐成为多模态大语言模型(MLLM)中的基准测试任务。本综述对图像和文本的自然语言理解,以及基于图像-问题信息的知识推理模块在核心VQA任务上的最新进展进行了综合。此外,我们详细阐述了在VQA中,利用视觉-语言预训练模型和多模态大语言模型提取和融合模态信息的最新进展。我们还通过详细描述内部知识的提取和外部知识的引入,全面回顾了VQA中知识推理的进展。最后,我们介绍了VQA的数据集和不同的评估指标,并讨论了未来可能的研究方向。
🔬 方法详解
问题定义:视觉问答(VQA)旨在根据给定的图像和问题,生成准确的答案。现有方法在处理复杂的视觉场景、理解细粒度的语言表达以及进行有效的知识推理方面面临挑战。尤其是在多模态大语言模型(MLLM)兴起后,如何有效利用MLLM提升VQA性能成为新的研究重点。
核心思路:本综述的核心思路是对VQA领域,特别是基于MLLM的VQA方法进行系统性的梳理和总结。通过分析不同模型的架构、训练策略以及在知识推理方面的处理方式,为研究者提供一个全面的视角,从而更好地理解VQA的发展趋势和未来方向。
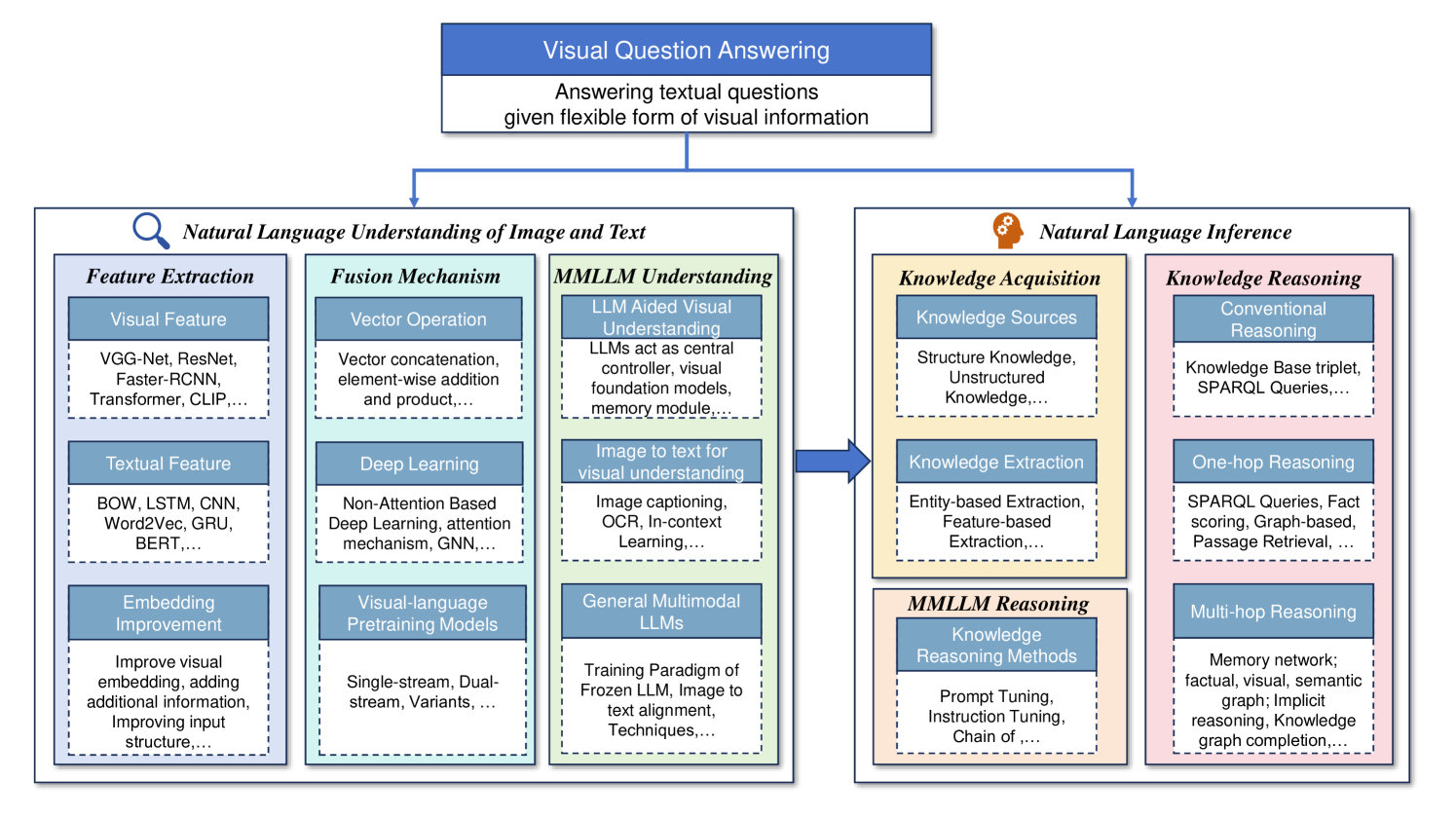
技术框架:该综述的技术框架主要围绕以下几个方面展开:1) VQA任务的概述;2) 基于视觉-语言预训练模型和多模态大语言模型的模态信息提取与融合方法;3) VQA中的知识推理,包括内部知识提取和外部知识引入;4) VQA数据集和评估指标;5) 未来研究方向的展望。
关键创新:该综述的关键创新在于其对基于MLLM的VQA方法的系统性总结和分析。不同于以往的VQA综述,该综述更加关注MLLM在VQA中的应用,并深入探讨了如何利用MLLM提升VQA的自然语言理解和知识推理能力。
关键设计:该综述的关键设计在于其结构化的组织方式,从VQA任务的定义到未来研究方向的展望,每个部分都进行了详细的阐述。此外,该综述还特别关注了VQA中的知识推理问题,并对内部知识提取和外部知识引入进行了深入的分析。
🖼️ 关键图片

📊 实验亮点
该综述总结了VQA领域最新的研究进展,特别是基于多模态大语言模型的方法。它详细分析了不同模型的性能和特点,并指出了未来研究的可能方向。虽然没有提供具体的实验数据,但该综述为研究者提供了一个全面的VQA领域概览,有助于他们更好地了解该领域的发展趋势。
🎯 应用场景
VQA技术具有广泛的应用前景,例如智能客服、图像搜索、辅助诊断等。在智能客服领域,VQA可以帮助机器人理解用户上传的图片并回答相关问题。在图像搜索领域,VQA可以实现基于问题的图像检索。在辅助诊断领域,VQA可以帮助医生分析医学影像并提供诊断建议。未来,随着VQA技术的不断发展,其应用场景将更加广泛。
📄 摘要(原文)
Visual Question Answering (VQA) is a challenge task that combines natural language processing and computer vision techniques and gradually becomes a benchmark test task in multimodal large language models (MLLMs). The goal of our survey is to provide an overview of the development of VQA and a detailed description of the latest models with high timeliness. This survey gives an up-to-date synthesis of natural language understanding of images and text, as well as the knowledge reasoning module based on image-question information on the core VQA tasks. In addition, we elaborate on recent advances in extracting and fusing modal information with vision-language pretraining models and multimodal large language models in VQA. We also exhaustively review the progress of knowledge reasoning in VQA by detailing the extraction of internal knowledge and the introduction of external knowledge. Finally, we present the datasets of VQA and different evaluation metrics and discuss possible directions for future work.