One Mind, Many Tongues: A Deep Dive into Language-Agnostic Knowledge Neurons in Large Language Models
作者: Pengfei Cao, Yuheng Chen, Zhuoran Jin, Yubo Chen, Kang Liu, Jun Zhao
分类: cs.CL
发布日期: 2024-11-26
💡 一句话要点
提出MATRICE方法,解决大语言模型中语言无关知识神经元定位不确定性问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言无关知识神经元 多语言模型 知识定位 不确定性估计 集成梯度 跨语言知识编辑 RML-LAMA
📋 核心要点
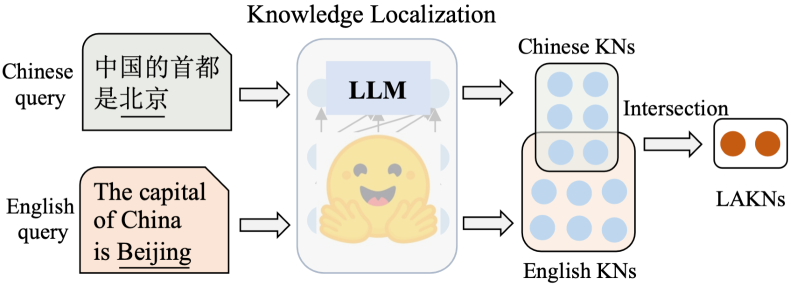
- 现有方法在定位语言无关知识神经元时,依赖prompt,但LLM对语义等价查询的回答不一致,导致定位结果不确定。
- 论文提出MATRICE方法,通过量化跨语言和查询的不确定性,更准确地定位语言无关的知识神经元。
- 实验表明,MATRICE能更准确地定位知识神经元,并验证其在跨语言知识编辑、增强和注入中的作用。
📝 摘要(中文)
大型语言模型(LLMs)通过大规模语料库上的自监督预训练学习了大量的 factual knowledge。同时,LLMs也展示了卓越的多语言能力,能够用多种语言表达所学到的知识。然而,LLMs中的知识存储机制仍然很神秘。一些研究人员试图从知识神经元的角度来揭示LLMs中的 factual knowledge,并随后发现了语言无关的知识神经元,这些神经元以一种超越语言障碍的形式存储 factual knowledge。然而,初步的研究结果存在两个局限性:1)定位结果的高度不确定性。现有的研究只使用基于 prompt 的探针来定位每个事实的知识神经元,而LLMs无法为语义等价的查询提供一致的答案。因此,导致了不准确的定位结果,具有高度的不确定性。2)缺乏对更多语言的分析。该研究仅分析了英语和中文数据上的语言无关知识神经元,而没有探索更多的语系和语言。自然地,这限制了研究结果的普遍性。为了解决上述问题,我们首先构建了一个名为 Rephrased Multilingual LAMA (RML-LAMA) 的新基准,其中包含高质量的 cloze-style 多语言并行查询。然后,我们提出了一种名为 Multilingual Integrated Gradients with Uncertainty Estimation (MATRICE) 的新方法,该方法量化了知识定位过程中跨查询和语言的不确定性。大量的实验表明,我们的方法可以准确地定位语言无关的知识神经元。我们还进一步研究了语言无关知识神经元在跨语言知识编辑、知识增强和新知识注入中的作用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型中语言无关知识神经元定位不准确的问题。现有方法主要依赖于prompt,通过观察模型对特定prompt的响应来确定知识神经元的位置。然而,大型语言模型对于语义等价的prompt可能会给出不一致的答案,这导致基于prompt的定位方法具有很高的不确定性,从而影响了定位结果的准确性。此外,现有研究主要集中在英语和中文,缺乏对更多语言的分析,限制了结论的泛化性。
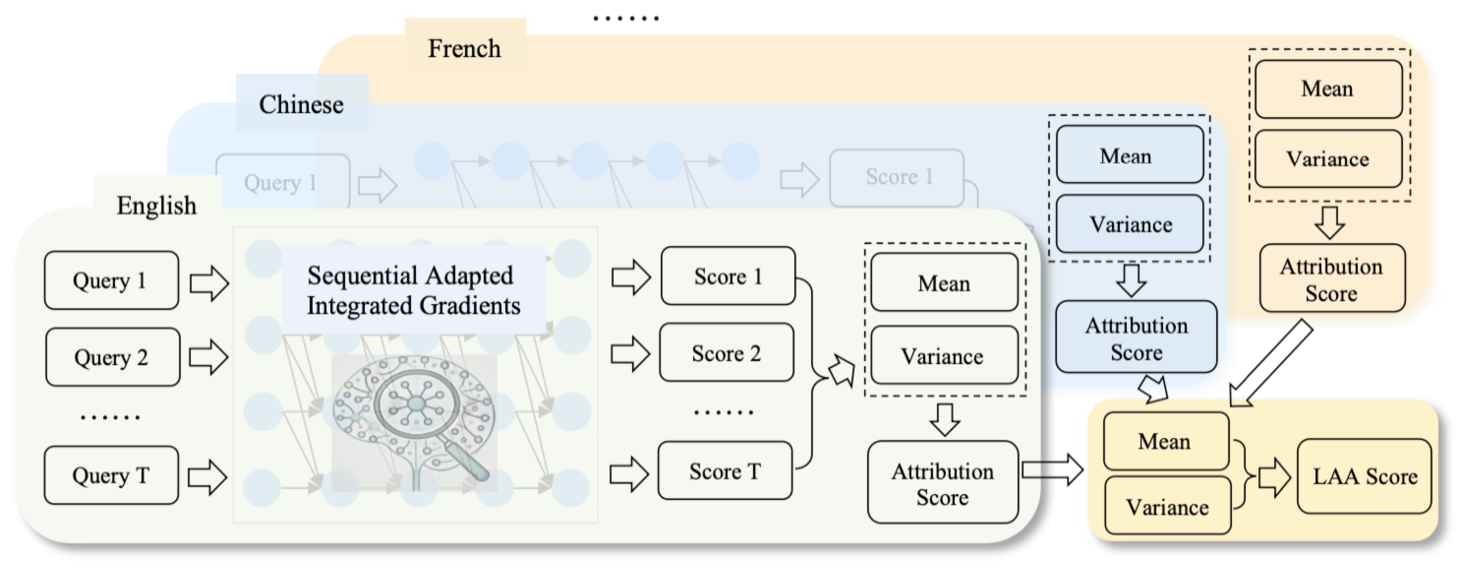
核心思路:论文的核心思路是通过量化知识定位过程中的不确定性来提高定位的准确性。具体来说,论文提出了一种名为Multilingual Integrated Gradients with Uncertainty Estimation (MATRICE) 的方法,该方法利用多语言数据和集成的梯度方法来估计定位结果的不确定性。通过考虑不同语言和查询之间的差异,MATRICE能够更稳健地识别出真正具有语言无关特性的知识神经元。
技术框架:MATRICE方法主要包含以下几个阶段:1) 构建多语言基准数据集RML-LAMA,包含多种语言的同义改写query;2) 使用多语言集成梯度方法计算每个神经元对于特定事实的贡献度;3) 通过统计不同语言和查询之间的梯度差异来估计定位结果的不确定性;4) 基于不确定性估计,筛选出置信度高的知识神经元。整体流程旨在降低prompt依赖性,提高定位的准确性和泛化性。
关键创新:MATRICE方法的关键创新在于引入了不确定性估计的概念,并将其应用于知识神经元的定位过程中。与传统的基于prompt的方法不同,MATRICE不仅考虑了神经元对特定事实的贡献度,还考虑了这种贡献度在不同语言和查询之间的稳定性。通过量化不确定性,MATRICE能够更准确地识别出真正具有语言无关特性的知识神经元,从而提高了定位的准确性和可靠性。
关键设计:RML-LAMA基准数据集的设计,包含多种语言的同义改写query,用于评估模型在不同语言环境下的知识表示能力。MATRICE方法使用Integrated Gradients来计算神经元的重要性得分,并采用蒙特卡洛方法来估计不确定性。损失函数的设计目标是最小化不确定性,同时最大化神经元对特定事实的贡献度。具体参数设置未知。
🖼️ 关键图片

📊 实验亮点
实验结果表明,MATRICE方法能够更准确地定位语言无关的知识神经元。与现有方法相比,MATRICE在RML-LAMA基准数据集上取得了显著的性能提升,具体提升幅度未知。此外,实验还验证了语言无关知识神经元在跨语言知识编辑、知识增强和新知识注入中的有效性,表明该方法具有实际应用价值。
🎯 应用场景
该研究成果可应用于提升多语言知识图谱的构建质量,改进跨语言信息检索和问答系统,并促进大型语言模型在多语言环境下的知识迁移和共享。通过更准确地定位知识神经元,可以实现更有效的知识编辑、增强和注入,从而提高模型的性能和泛化能力。此外,该研究还有助于深入理解大型语言模型内部的知识表示机制。
📄 摘要(原文)
Large language models (LLMs) have learned vast amounts of factual knowledge through self-supervised pre-training on large-scale corpora. Meanwhile, LLMs have also demonstrated excellent multilingual capabilities, which can express the learned knowledge in multiple languages. However, the knowledge storage mechanism in LLMs still remains mysterious. Some researchers attempt to demystify the factual knowledge in LLMs from the perspective of knowledge neurons, and subsequently discover language-agnostic knowledge neurons that store factual knowledge in a form that transcends language barriers. However, the preliminary finding suffers from two limitations: 1) High Uncertainty in Localization Results. Existing study only uses a prompt-based probe to localize knowledge neurons for each fact, while LLMs cannot provide consistent answers for semantically equivalent queries. Thus, it leads to inaccurate localization results with high uncertainty. 2) Lack of Analysis in More Languages. The study only analyzes language-agnostic knowledge neurons on English and Chinese data, without exploring more language families and languages. Naturally, it limits the generalizability of the findings. To address aforementioned problems, we first construct a new benchmark called Rephrased Multilingual LAMA (RML-LAMA), which contains high-quality cloze-style multilingual parallel queries for each fact. Then, we propose a novel method named Multilingual Integrated Gradients with Uncertainty Estimation (MATRICE), which quantifies the uncertainty across queries and languages during knowledge localization. Extensive experiments show that our method can accurately localize language-agnostic knowledge neurons. We also further investigate the role of language-agnostic knowledge neurons in cross-lingual knowledge editing, knowledge enhancement and new knowledge injection.