Systematic Reward Gap Optimization for Mitigating VLM Hallucinations
作者: Lehan He, Zeren Chen, Zhelun Shi, Tianyu Yu, Jing Shao, Lu Sheng
分类: cs.CL, cs.CV
发布日期: 2024-11-26 (更新: 2025-11-24)
备注: 34 pages, 12 figures, Accepted by NeurIPS 2025
💡 一句话要点
提出主题级偏好重写(TPR)框架,系统优化奖励差距以缓解VLM幻觉问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视觉语言模型 幻觉缓解 直接偏好优化 奖励差距优化 主题级重写
📋 核心要点
- 现有VLM幻觉缓解方法难以系统优化奖励差距,缺乏对偏好对中奖励差距配置的精确控制。
- 提出主题级偏好重写(TPR)框架,通过主题级控制实现对VLM响应的细粒度语义重写,优化奖励差距。
- 实验表明TPR在多个幻觉基准测试中达到SOTA,平均提升20%,在ObjectHal-Bench上幻觉减少高达93%。
📝 摘要(中文)
直接偏好优化(DPO)在缓解视觉语言模型(VLM)幻觉方面的成功,关键在于偏好对中真实的奖励差距。然而,目前的方法通常依赖于排序或重写策略,难以系统地优化数据标注过程中这些奖励差距。核心难点在于精确地表征和策略性地操纵整体奖励差距配置,即如何精心设计数据中每个偏好对内的奖励差距。为了解决这个问题,我们引入了主题级偏好重写(TPR),这是一个用于系统优化奖励差距配置的新框架。通过选择性地用模型自身重采样的候选对象替换VLM响应中的语义主题以进行有针对性的重写,TPR可以提供对细粒度语义细节的主题级控制。这种精确的控制实现了高级数据标注策略,例如逐步调整被拒绝响应的难度,从而塑造有效的奖励差距配置,引导模型克服具有挑战性的幻觉。全面的实验表明,TPR在多个幻觉基准测试中实现了最先进的性能,平均优于以前的方法20%。值得注意的是,它在ObjectHal-Bench上显著减少了高达93%的幻觉,并且还表现出卓越的数据效率,从而实现了稳健且经济高效的VLM对齐。
🔬 方法详解
问题定义:论文旨在解决视觉语言模型(VLM)中存在的幻觉问题,即模型生成不真实或与输入图像不符的内容。现有方法,如基于排序或重写的策略,在数据标注过程中难以系统地优化奖励差距,无法精确控制偏好对之间的奖励差异,导致模型难以有效学习避免幻觉。
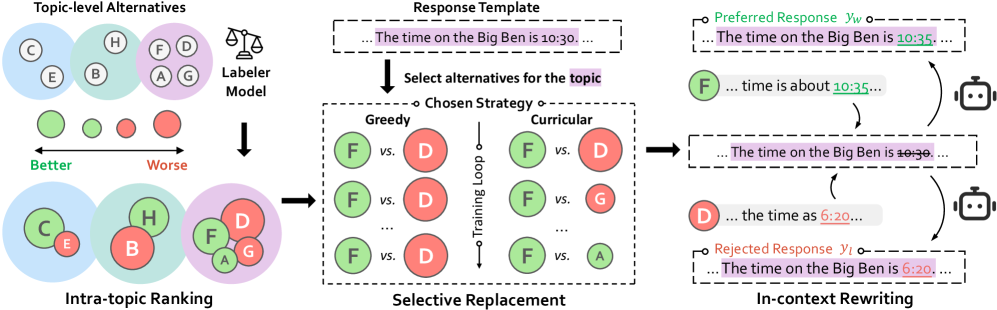
核心思路:论文的核心思路是通过更精细的控制VLM生成响应的语义内容,从而更有效地塑造奖励差距。具体来说,通过识别响应中的关键“主题”,并用模型重新采样的候选主题替换它们,可以逐步调整被拒绝响应的难度,从而引导模型学习更准确的视觉语言关联。
技术框架:TPR框架包含以下主要步骤:1) 主题识别:识别VLM生成响应中的关键语义主题。2) 候选重采样:使用VLM自身对识别出的主题进行重采样,生成多个候选替换主题。3) 偏好重写:选择性地用重采样的候选主题替换原始响应中的主题,生成新的响应。4) 奖励差距优化:使用DPO等方法,基于原始响应和重写后的响应之间的偏好关系,优化模型的奖励函数。
关键创新:TPR的关键创新在于其主题级别的控制能力。与传统的整体重写方法不同,TPR允许对响应的特定语义部分进行修改,从而可以更精细地调整奖励差距,并引导模型关注关键的视觉语言关联。这种细粒度的控制使得数据标注过程更加高效和有效。
关键设计:TPR框架的关键设计包括:1) 主题识别方法:可以使用现有的命名实体识别(NER)或关键词提取技术来识别主题。2) 重采样策略:可以使用不同的采样策略来生成候选主题,例如top-k采样或nucleus采样。3) 偏好选择策略:需要设计一种策略来选择哪些重写后的响应作为负样本,例如可以选择与原始响应语义差异最大的响应。
🖼️ 关键图片
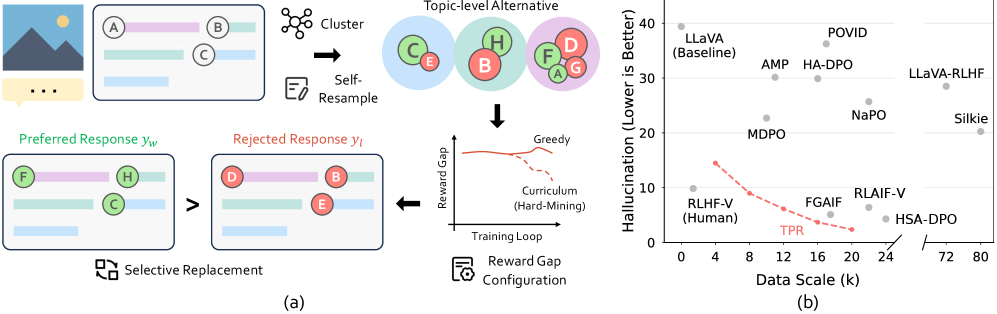

📊 实验亮点
TPR在多个幻觉基准测试中取得了显著的性能提升,平均优于现有方法20%。在ObjectHal-Bench上,TPR将幻觉减少了高达93%。此外,实验还表明TPR具有更高的数据效率,可以使用更少的数据实现更好的性能,从而降低了VLM对齐的成本。
🎯 应用场景
该研究成果可应用于各种需要可靠视觉语言理解的场景,例如图像描述生成、视觉问答、机器人导航和自动驾驶等。通过减少VLM的幻觉,可以提高这些应用的安全性和可靠性,并增强用户信任度。此外,该方法还可以用于改进VLM的数据标注流程,降低标注成本。
📄 摘要(原文)
The success of Direct Preference Optimization (DPO) in mitigating hallucinations in Vision Language Models (VLMs) critically hinges on the true reward gaps within preference pairs. However, current methods, typically relying on ranking or rewriting strategies, often struggle to optimize these reward gaps in a systematic way during data curation. A core difficulty lies in precisely characterizing and strategically manipulating the overall reward gap configuration, that is, the deliberate design of how to shape these reward gaps within each preference pair across the data. To address this, we introduce Topic-level Preference Rewriting(TPR), a novel framework designed for the systematic optimization of reward gap configuration. Through selectively replacing semantic topics within VLM responses with model's own resampled candidates for targeted rewriting, TPR can provide topic-level control over fine-grained semantic details. This precise control enables advanced data curation strategies, such as progressively adjusting the difficulty of rejected responses, thereby sculpting an effective reward gap configuration that guides the model to overcome challenging hallucinations. Comprehensive experiments demonstrate TPR achieves state-of-the-art performance on multiple hallucination benchmarks, outperforming previous methods by an average of 20%. Notably, it significantly reduces hallucinations by up to 93% on ObjectHal-Bench, and also exhibits superior data efficiency towards robust and cost-effective VLM alignment. Code and datasets are available at https://tpr-dpo.github.io .