Overcoming Non-monotonicity in Transducer-based Streaming Generation
作者: Zhengrui Ma, Yang Feng, Min Zhang
分类: cs.CL, cs.AI
发布日期: 2024-11-26 (更新: 2025-05-28)
备注: ICML25; Codes: https://github.com/ictnlp/MonoAttn-Transducer
💡 一句话要点
提出MonoAttn-Transducer,解决Transducer在非单调对齐流式生成任务中的问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 流式生成 Transducer 非单调对齐 单调注意力 同步翻译
📋 核心要点
- Transducer架构在流式生成任务中应用广泛,但其输入同步解码机制难以处理非单调对齐问题。
- 论文提出MonoAttn-Transducer,通过可学习的单调注意力机制,将Transducer解码与输入流历史信息结合。
- 实验结果表明,该方法能有效处理非单调对齐,为复杂生成任务提供更鲁棒的解决方案。
📝 摘要(中文)
流式生成模型被广泛应用于各个领域,其中Transducer架构在工业应用中尤为流行。然而,其输入同步解码机制在需要非单调对齐的任务中,例如同步翻译,面临挑战。本研究通过将Transducer的解码与输入流的历史信息相结合,并引入可学习的单调注意力机制来解决这个问题。我们的方法利用前向-后向算法推断预测器状态和输入时间戳之间对齐的后验概率,然后使用该概率估计单调上下文表示,从而避免了在训练期间枚举指数级的对齐空间。大量实验表明,我们的MonoAttn-Transducer有效地处理了流式场景中的非单调对齐,为复杂的生成任务提供了一个鲁棒的解决方案。
🔬 方法详解
问题定义:Transducer模型在流式生成任务中表现出色,但其固有的输入同步解码机制使其难以处理需要非单调对齐的任务,例如同步翻译。传统的Transducer模型强制输入和输出之间保持严格的单调对齐,这限制了其在需要重新排序或延迟的任务中的应用。现有方法难以在保证流式生成效率的同时,有效处理非单调对齐问题。
核心思路:论文的核心思路是通过引入一个可学习的单调注意力机制(MonoAttn),将Transducer的解码过程与输入流的历史信息相结合。MonoAttn允许模型在生成每个输出token时,动态地关注输入序列的不同部分,从而打破了严格的单调对齐约束。通过学习输入和输出之间的软对齐关系,模型能够更好地处理非单调对齐的情况。
技术框架:MonoAttn-Transducer的整体框架包括三个主要模块:编码器、预测器和连接网络。编码器负责将输入序列转换为隐藏表示;预测器根据之前的输出序列生成下一个输出的预测;连接网络将编码器的输出和预测器的输出结合起来,生成最终的输出概率分布。关键在于,在预测器和连接网络之间,引入了MonoAttn模块。该模块利用前向-后向算法计算预测器状态和输入时间戳之间的对齐后验概率,并使用该概率来加权输入序列的隐藏表示,从而生成单调上下文表示。
关键创新:论文最重要的技术创新点是MonoAttn模块。与传统的硬性单调对齐方法不同,MonoAttn允许模型学习输入和输出之间的软对齐关系,从而能够处理非单调对齐的情况。此外,通过使用前向-后向算法计算对齐后验概率,避免了枚举指数级的对齐空间,提高了训练效率。与现有方法的本质区别在于,MonoAttn-Transducer不再强制输入和输出之间的严格单调对齐,而是允许模型根据输入流的历史信息动态地调整对齐方式。
关键设计:MonoAttn模块的关键设计包括:1) 使用前向-后向算法计算对齐后验概率;2) 使用计算得到的后验概率来加权输入序列的隐藏表示,生成单调上下文表示;3) 将单调上下文表示与预测器的输出结合起来,作为连接网络的输入。损失函数采用标准的Transducer损失函数,并增加了一个正则化项,以鼓励MonoAttn学习到更加单调的对齐关系。具体的网络结构和参数设置在实验部分进行了详细描述。
🖼️ 关键图片

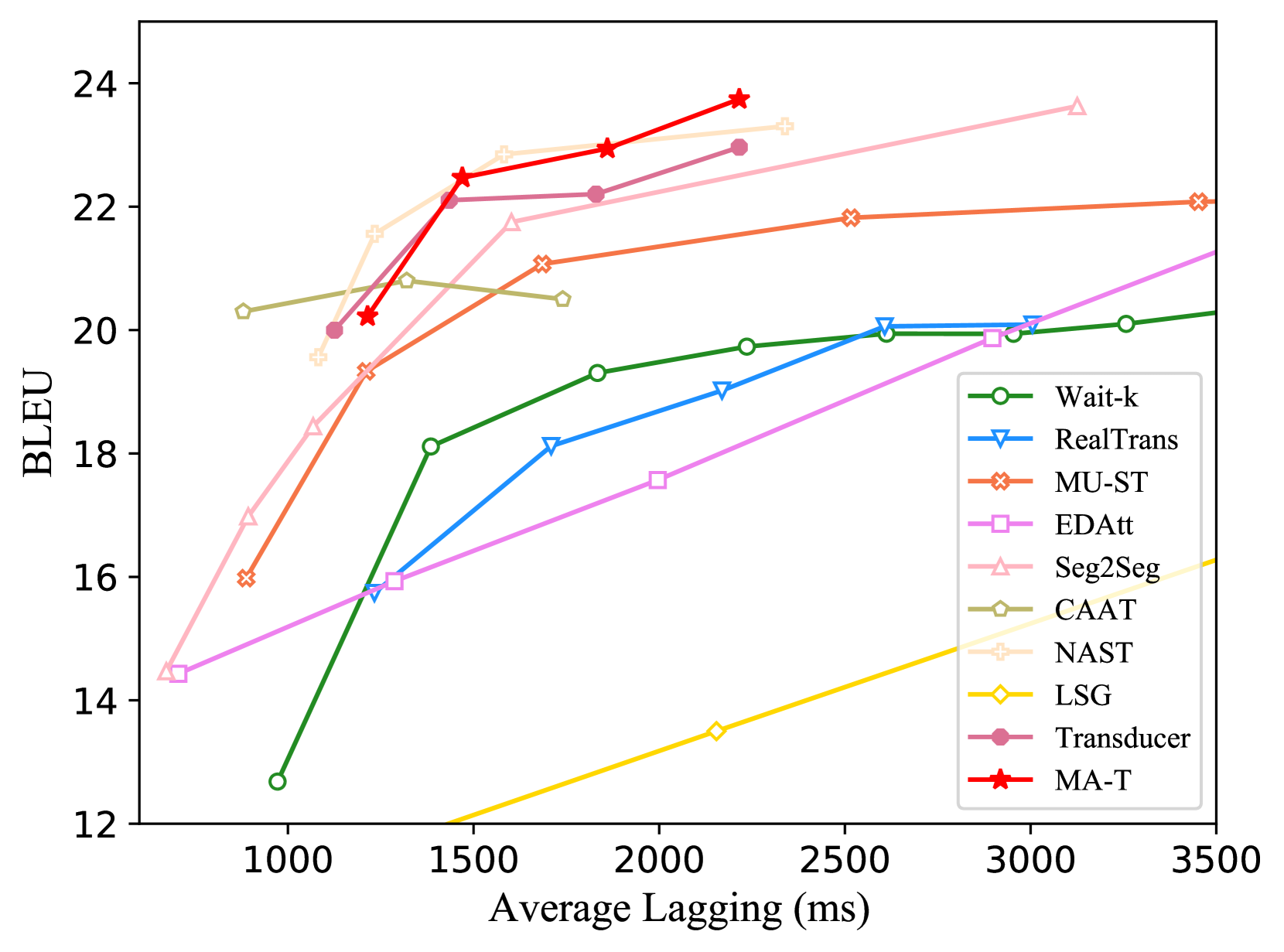
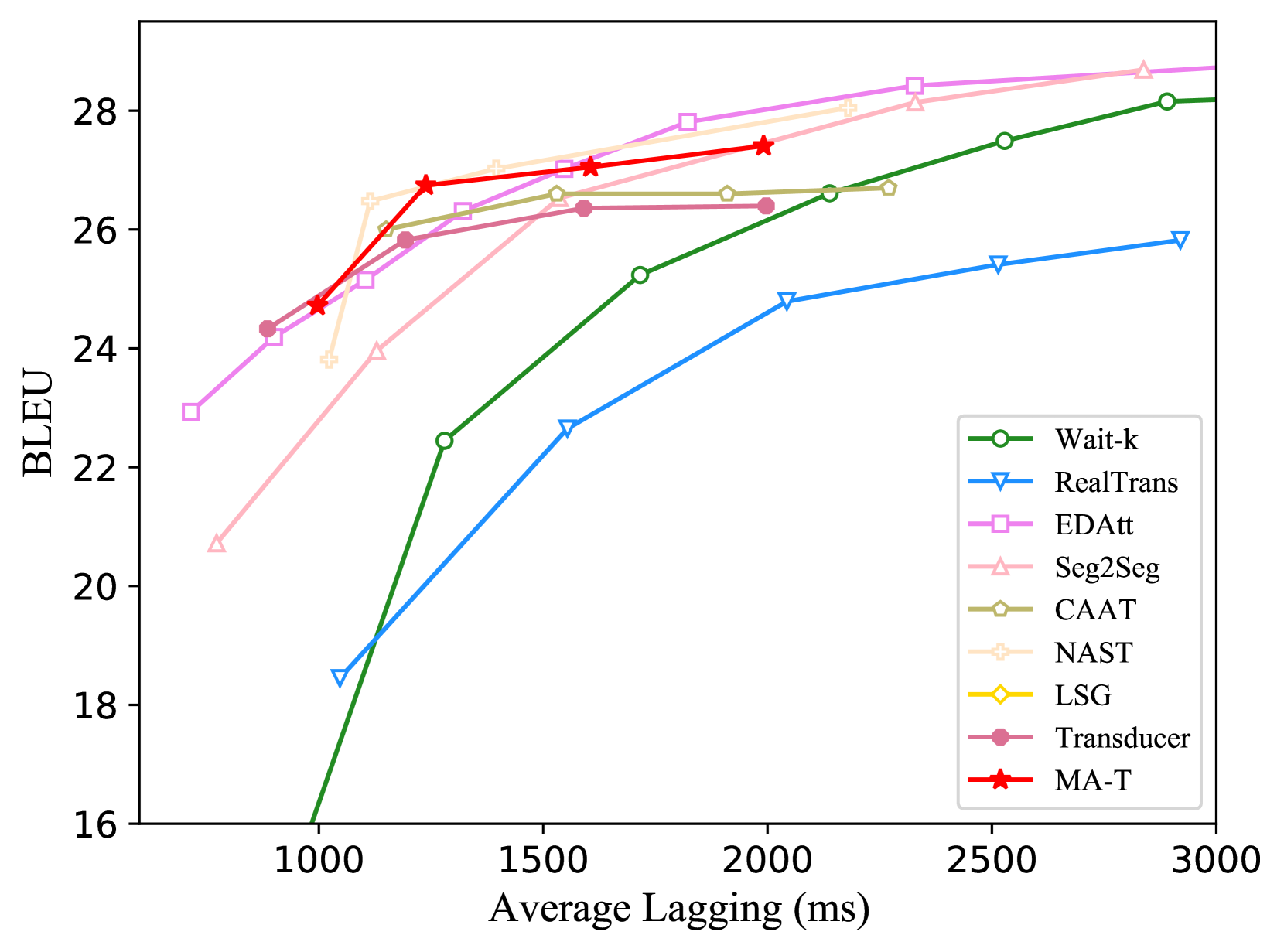
📊 实验亮点
论文通过大量实验验证了MonoAttn-Transducer的有效性。实验结果表明,在同步翻译任务中,MonoAttn-Transducer在保持较低延迟的同时,显著提高了翻译质量。与基线Transducer模型相比,MonoAttn-Transducer在BLEU得分上取得了显著提升。此外,实验还表明,MonoAttn-Transducer对不同的输入序列长度和噪声具有较强的鲁棒性。
🎯 应用场景
该研究成果可广泛应用于需要流式生成和非单调对齐的场景,例如同步翻译、语音识别和文本摘要等。在同步翻译中,该方法可以允许模型在接收到完整的输入句子之前就开始生成翻译,从而减少延迟。在语音识别中,该方法可以更好地处理语音中的停顿和重复,提高识别准确率。该研究的实际价值在于提高了流式生成模型的性能和鲁棒性,为实时应用提供了更好的支持。未来,该方法可以进一步扩展到其他需要处理非单调对齐的任务中。
📄 摘要(原文)
Streaming generation models are utilized across fields, with the Transducer architecture being popular in industrial applications. However, its input-synchronous decoding mechanism presents challenges in tasks requiring non-monotonic alignments, such as simultaneous translation. In this research, we address this issue by integrating Transducer's decoding with the history of input stream via a learnable monotonic attention. Our approach leverages the forward-backward algorithm to infer the posterior probability of alignments between the predictor states and input timestamps, which is then used to estimate the monotonic context representations, thereby avoiding the need to enumerate the exponentially large alignment space during training. Extensive experiments show that our MonoAttn-Transducer effectively handles non-monotonic alignments in streaming scenarios, offering a robust solution for complex generation tasks.