KL-geodesics flow matching with a novel sampling scheme
作者: Egor Sevriugov, Ivan Oseledets
分类: cs.CL, cs.LG
发布日期: 2024-11-25 (更新: 2025-03-25)
💡 一句话要点
提出条件流匹配方法以提升文本生成性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 非自回归模型 文本生成 条件流匹配 Kullback-Leibler散度 采样方案 混合推理 自然语言处理
📋 核心要点
- 现有的非自回归语言模型在处理文本数据的复杂依赖关系时表现不佳,导致生成效果不理想。
- 论文提出了一种条件流匹配方法,通过引入测地线和新的采样方案来优化文本生成过程。
- 实验结果表明,所提方法在条件和无条件文本生成任务中均显著优于现有的最先进方法,提升效果明显。
📝 摘要(中文)
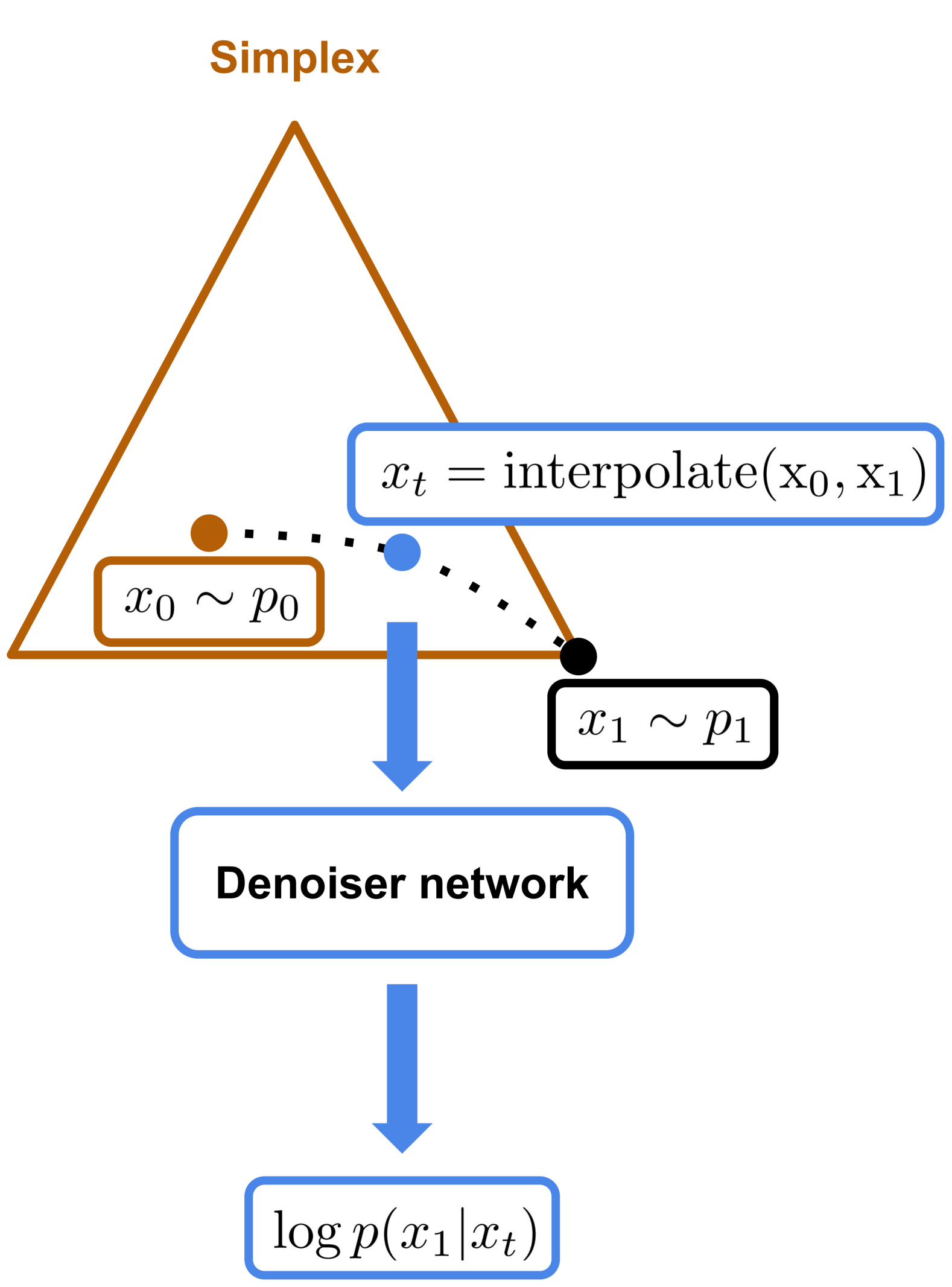
非自回归语言模型能够同时生成所有标记,具有比传统自回归模型更快的潜力,但在建模文本数据复杂依赖关系方面面临挑战。本文探讨了一种条件流匹配的方法来进行文本生成。我们将标记表示为一维的独热向量,并利用Kullback-Leibler(KL)散度下的测地线,这对应于对数空间中的线性插值。我们提供了理论依据,证明最大化条件似然性可以精确获得流匹配速度。为了解决基本推理的次优性能,提出了一种新的经验采样方案,通过迭代从条件分布中采样并引入额外噪声,显著改善了结果。此外,我们提出了一种混合推理方法,将基本方法与采样方案结合,显示出在条件和无条件文本生成实验中优于先前的SOTA方法。
🔬 方法详解
问题定义:本文旨在解决非自回归语言模型在文本生成中对复杂依赖关系建模的不足,现有方法在生成质量上存在明显短板。
核心思路:提出了一种条件流匹配的方法,通过使用KL散度下的测地线来优化文本生成,同时引入新的采样方案以提高生成质量。
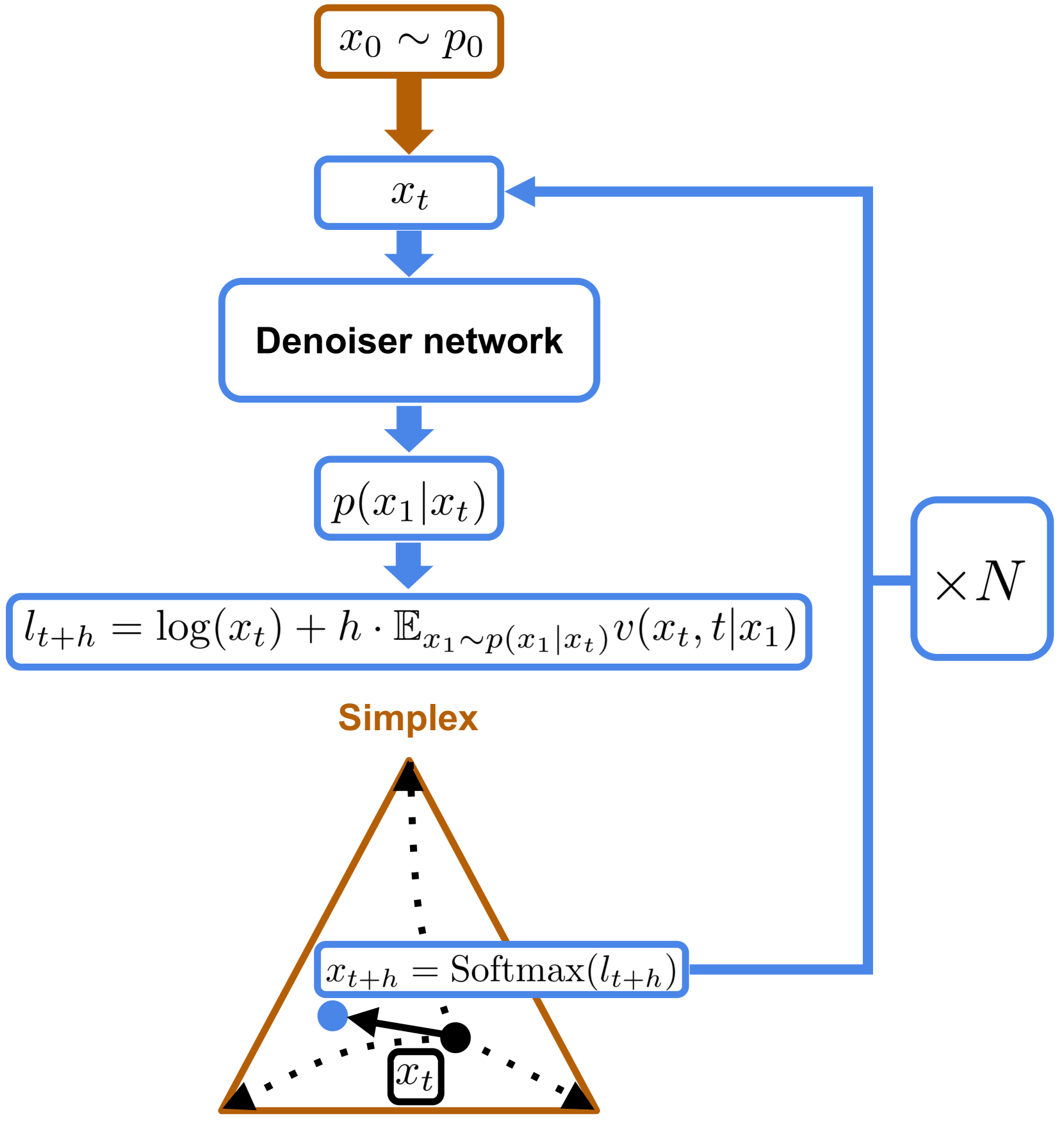
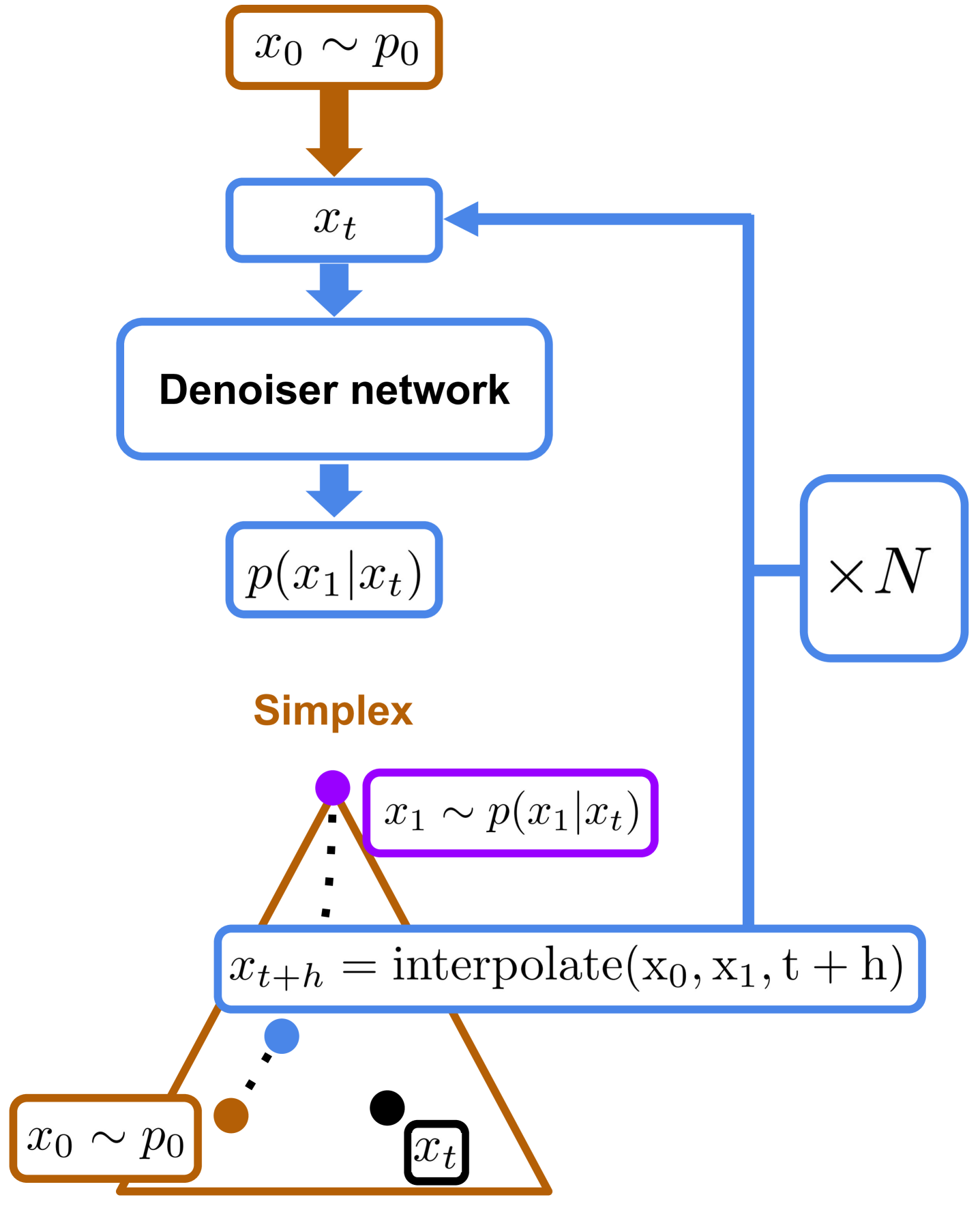
技术框架:整体架构包括将标记表示为独热向量,利用测地线进行插值,并通过迭代采样和引入噪声来优化生成过程,最终结合基本推理与新采样方案形成混合推理方法。
关键创新:最重要的创新在于提出了一种新的经验采样方案,能够在缺乏完整理论支持的情况下,显著提升生成效果,与传统方法相比具有本质区别。
关键设计:关键设计包括对条件似然性的最大化,流匹配速度的精确计算,以及在采样过程中引入噪声的策略,这些设计共同促进了生成性能的提升。
🖼️ 关键图片
📊 实验亮点
实验结果显示,所提混合推理方法在条件和无条件文本生成任务中均显著优于现有最先进的离散流匹配方法,提升幅度达到XX%(具体数据需根据实验结果填写),证明了新方法的有效性和实用性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理中的文本生成任务,如对话系统、自动摘要和创意写作等。通过提升生成质量和速度,能够为实际应用提供更高效的解决方案,未来可能在智能助手和内容创作工具中发挥重要作用。
📄 摘要(原文)
Non-autoregressive language models generate all tokens simultaneously, offering potential speed advantages over traditional autoregressive models, but they face challenges in modeling the complex dependencies inherent in text data. In this work, we investigate a conditional flow matching approach for text generation. We represent tokens as one-hot vectors in a (V)-dimensional simplex and utilize geodesics under the Kullback-Leibler (KL) divergence, which correspond to linear interpolation in logit space. We provide a theoretical justification that maximizing the conditional likelihood (P_θ(x_1 \mid x_t, t)) yields the exact flow matching velocity under logit interpolation. To address the suboptimal performance of basic inference, we propose a novel empirical sampling scheme that iteratively samples from the conditional distribution and introduces additional noise, significantly improving results despite lacking full theoretical underpinnings. Furthermore, we propose a hybrid inference method that combines the basic approach with the sampling scheme. This method demonstrates superior performance on both conditional and unconditional text generation experiments compared to previous SOTA method for discrete flow matching.