Enhancing Answer Reliability Through Inter-Model Consensus of Large Language Models
作者: Alireza Amiri-Margavi, Iman Jebellat, Ehsan Jebellat, Seyed Pouyan Mousavi Davoudi
分类: cs.CL, cs.AI
发布日期: 2024-11-25 (更新: 2025-02-24)
备注: 14 pages, 2 figures
💡 一句话要点
提出基于多大型语言模型共识的框架,提升复杂问题回答的可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 模型共识 可靠性评估 统计分析 协作推理
📋 核心要点
- 现有大型语言模型在回答复杂问题时,缺乏明确的ground truth,难以评估其可靠性。
- 论文提出一种多模型协作框架,通过模型间共识来提升回答的可靠性,并评估问题质量。
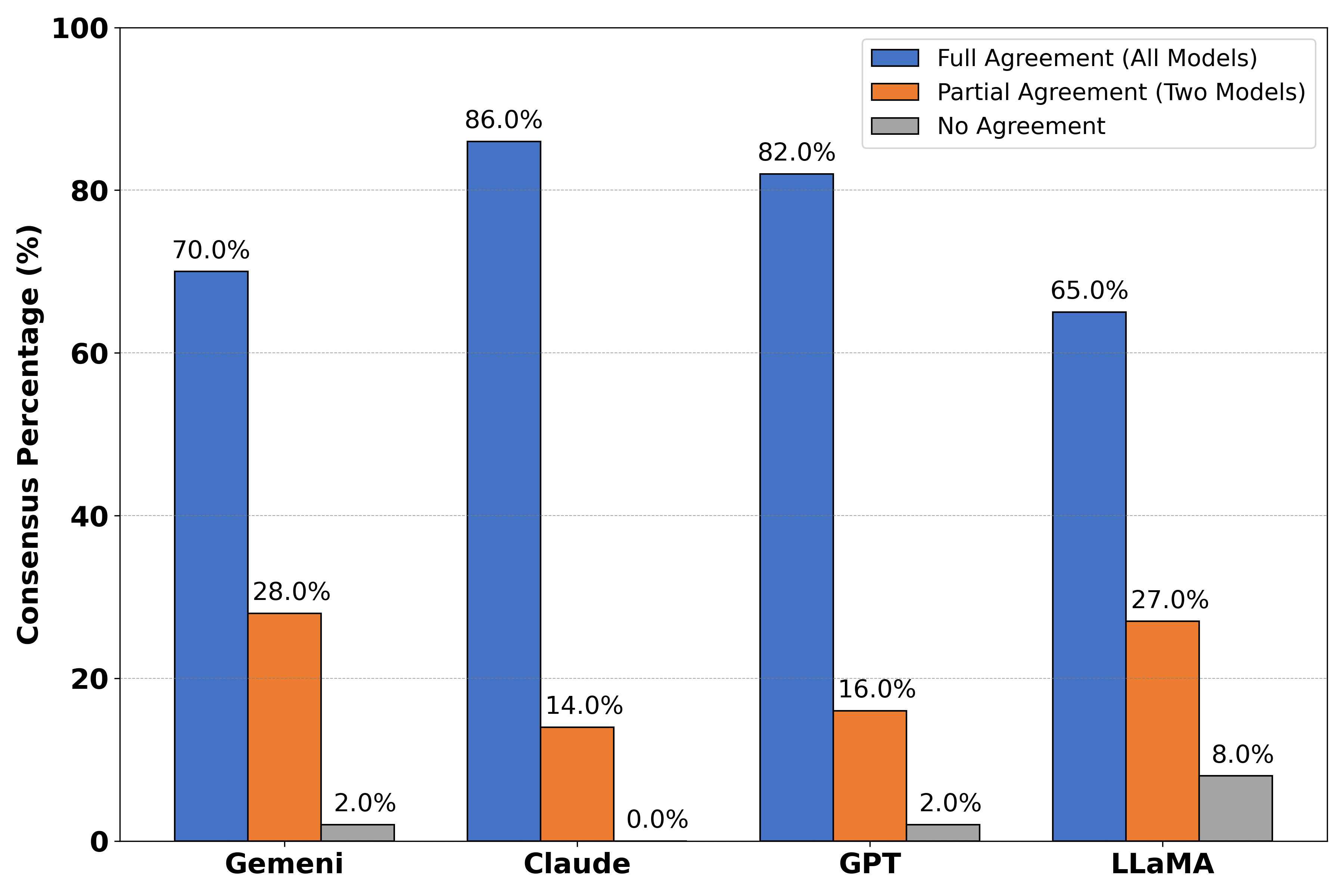
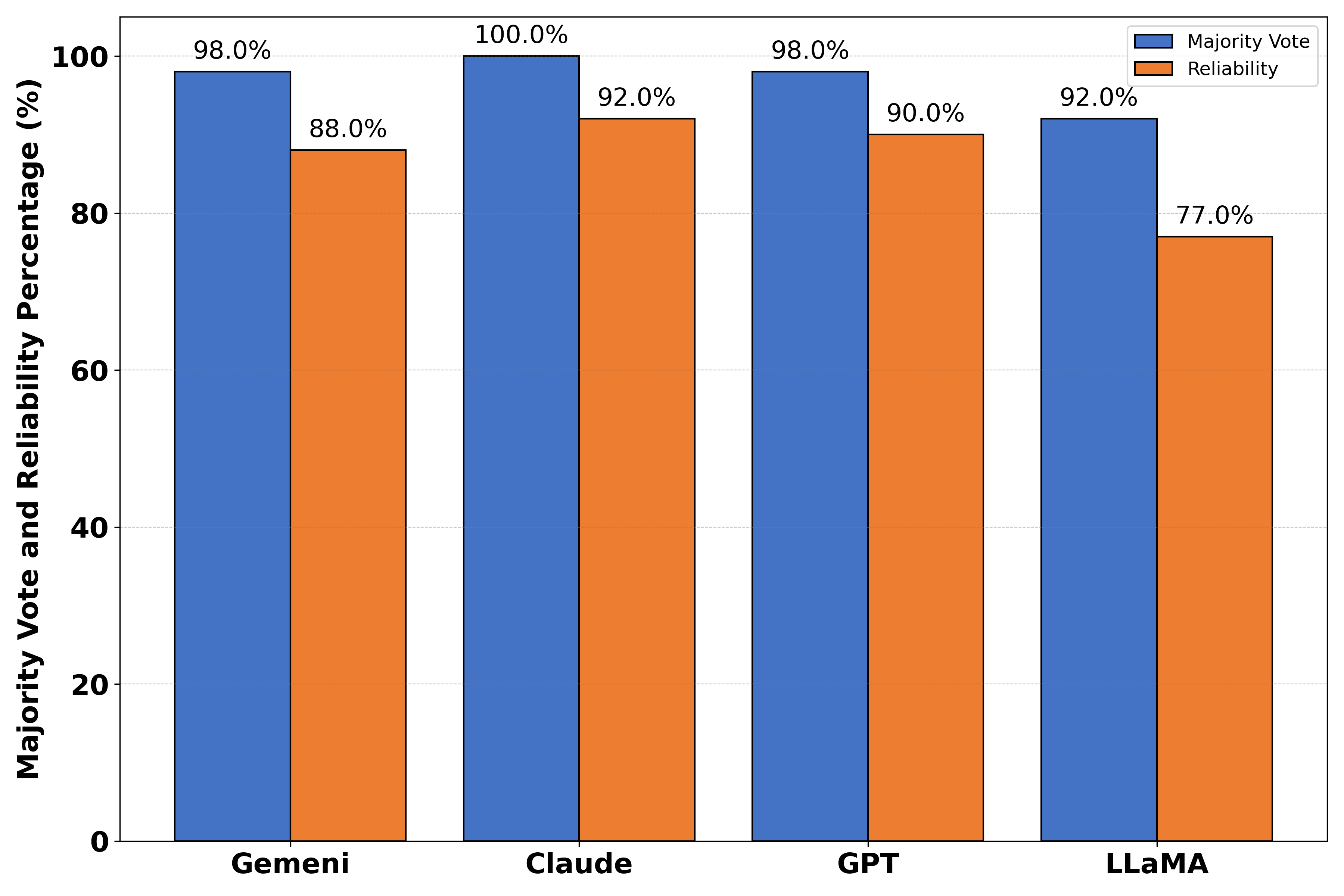
- 实验结果表明,Claude和GPT-4生成的问题结构更好,歧义更少,模型间一致性更高。
📝 摘要(中文)
本文提出了一种协作框架,其中多个大型语言模型(包括GPT-4-0125-preview、Meta-LLaMA-3-70B-Instruct、Claude-3-Opus和Gemini-1.5-Flash)生成并回答复杂的博士级别统计问题,这些问题缺乏明确的ground truth。本研究考察了模型间共识如何提高回答的可靠性,并识别生成问题的质量。通过采用卡方检验、Fleiss' Kappa和置信区间分析,我们量化了共识率和评估者间一致性,以评估回答的准确性和问题质量。主要结果表明,Claude和GPT-4生成结构良好、歧义较少的问题,且评估者间一致性更高,表现为更窄的置信区间和与问题生成模型更高的对齐度。相比之下,Gemini和LLaMA在问题制定方面表现出更大的变异性和更低的可靠性。这些发现表明,大型语言模型之间的协作交互可以提高回答的可靠性,并为优化AI驱动的协作推理系统提供有价值的见解。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在回答复杂、博士级别统计问题时,由于缺乏明确的ground truth而导致的答案可靠性难以评估的问题。现有方法难以有效利用多个LLM的优势,且无法有效评估生成问题的质量。
核心思路:核心思路是利用多个大型语言模型(GPT-4、LLaMA-3、Claude-3、Gemini-1.5)进行协作,通过模型间的共识程度来评估答案的可靠性。同时,通过分析问题生成模型的一致性,来评估问题的质量。
技术框架:整体框架包含问题生成和问题回答两个阶段。首先,由多个LLM生成复杂的统计问题。然后,所有LLM对这些问题进行回答。最后,通过统计分析模型间答案的共识程度,以及问题生成模型间的一致性,来评估答案的可靠性和问题的质量。使用的统计方法包括卡方检验、Fleiss' Kappa和置信区间分析。
关键创新:关键创新在于利用多模型共识作为评估答案可靠性的指标,并结合统计分析方法量化模型间的一致性。这种方法无需依赖ground truth,即可评估LLM在复杂问题上的表现。
关键设计:论文的关键设计包括:1) 选择具有代表性的LLM(GPT-4、LLaMA-3、Claude-3、Gemini-1.5)作为参与者;2) 使用卡方检验评估模型间答案的显著性差异;3) 使用Fleiss' Kappa评估多个模型间答案的一致性程度;4) 使用置信区间分析评估问题生成模型间的一致性,置信区间越窄,一致性越高。
🖼️ 关键图片
📊 实验亮点
实验结果表明,Claude和GPT-4在生成结构良好、歧义较少的问题方面表现更优,评估者间一致性更高,置信区间更窄。相比之下,Gemini和LLaMA在问题制定方面表现出更大的变异性和更低的可靠性。这些发现为选择合适的LLM以及优化AI协作系统提供了重要依据。
🎯 应用场景
该研究成果可应用于构建更可靠的AI协作推理系统,尤其是在缺乏明确ground truth的复杂领域,如科学研究、政策制定等。通过多模型共识,可以提高AI系统决策的准确性和可信度,并为优化AI模型提供有价值的反馈。
📄 摘要(原文)
We propose a collaborative framework in which multiple large language models -- including GPT-4-0125-preview, Meta-LLaMA-3-70B-Instruct, Claude-3-Opus, and Gemini-1.5-Flash -- generate and answer complex, PhD-level statistical questions when definitive ground truth is unavailable. Our study examines how inter-model consensus improves both response reliability and identifies the quality of the generated questions. Employing chi-square tests, Fleiss' Kappa, and confidence interval analysis, we quantify consensus rates and inter-rater agreement to assess both response precision and question quality. Key results indicate that Claude and GPT-4 produce well-structured, less ambiguous questions with a higher inter-rater agreement, as shown by narrower confidence intervals and greater alignment with question-generating models. In contrast, Gemini and LLaMA exhibit greater variability and lower reliability in question formulation. These findings demonstrate that collaborative interactions among large language models enhance response reliability and provide valuable insights for optimizing AI-driven collaborative reasoning systems.