Self-Generated Critiques Boost Reward Modeling for Language Models
作者: Yue Yu, Zhengxing Chen, Aston Zhang, Liang Tan, Chenguang Zhu, Richard Yuanzhe Pang, Yundi Qian, Xuewei Wang, Suchin Gururangan, Chao Zhang, Melanie Kambadur, Dhruv Mahajan, Rui Hou
分类: cs.CL, cs.AI, cs.LG
发布日期: 2024-11-25 (更新: 2025-02-09)
备注: Accepted to NAACL 2025 (Main Conference)
期刊: NAACL 2025
💡 一句话要点
Critic-RM:利用自生成评判提升语言模型奖励建模能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励建模 语言模型 人类反馈强化学习 自生成评判 自然语言反馈
📋 核心要点
- 现有奖励模型主要输出标量分数,缺乏对语言模型推理过程的细粒度评判能力。
- Critic-RM通过自生成高质量评判,并将其与标量奖励预测相结合,提升奖励模型的性能。
- 实验表明,Critic-RM在奖励建模精度和推理精度上均有显著提升,且具有较高的数据效率。
📝 摘要(中文)
奖励建模对于将大型语言模型(LLM)与人类偏好对齐至关重要,尤其是在基于人类反馈的强化学习(RLHF)中。然而,当前的奖励模型主要产生标量分数,难以自然语言形式融入评判。我们假设预测评判和标量奖励将提高奖励建模能力。为此,我们提出了Critic-RM,一个利用自生成评判来改进奖励模型的框架,无需额外监督。Critic-RM采用两阶段过程:生成和过滤高质量的评判,然后联合微调奖励预测和评判生成。跨基准的实验表明,与标准奖励模型和LLM judges相比,Critic-RM将奖励建模精度提高了3.7%-7.3%,表现出强大的性能和数据效率。其他研究进一步验证了生成的评判在纠正错误推理步骤方面的有效性,在提高推理精度方面获得了2.5%-3.2%的收益。
🔬 方法详解
问题定义:现有奖励模型主要输出标量奖励值,无法提供关于语言模型生成结果的详细反馈,限制了模型对人类偏好的理解和对齐。缺乏细粒度的评判信息使得模型难以纠正推理过程中的错误,从而影响最终的生成质量。
核心思路:Critic-RM的核心思路是让奖励模型不仅预测标量奖励,还要生成对语言模型生成结果的自然语言评判。通过同时预测奖励和评判,模型可以学习到更丰富的关于人类偏好的信息,从而提高奖励建模的准确性和有效性。这种方法无需额外的人工标注评判数据,而是利用模型自身生成评判,降低了训练成本。
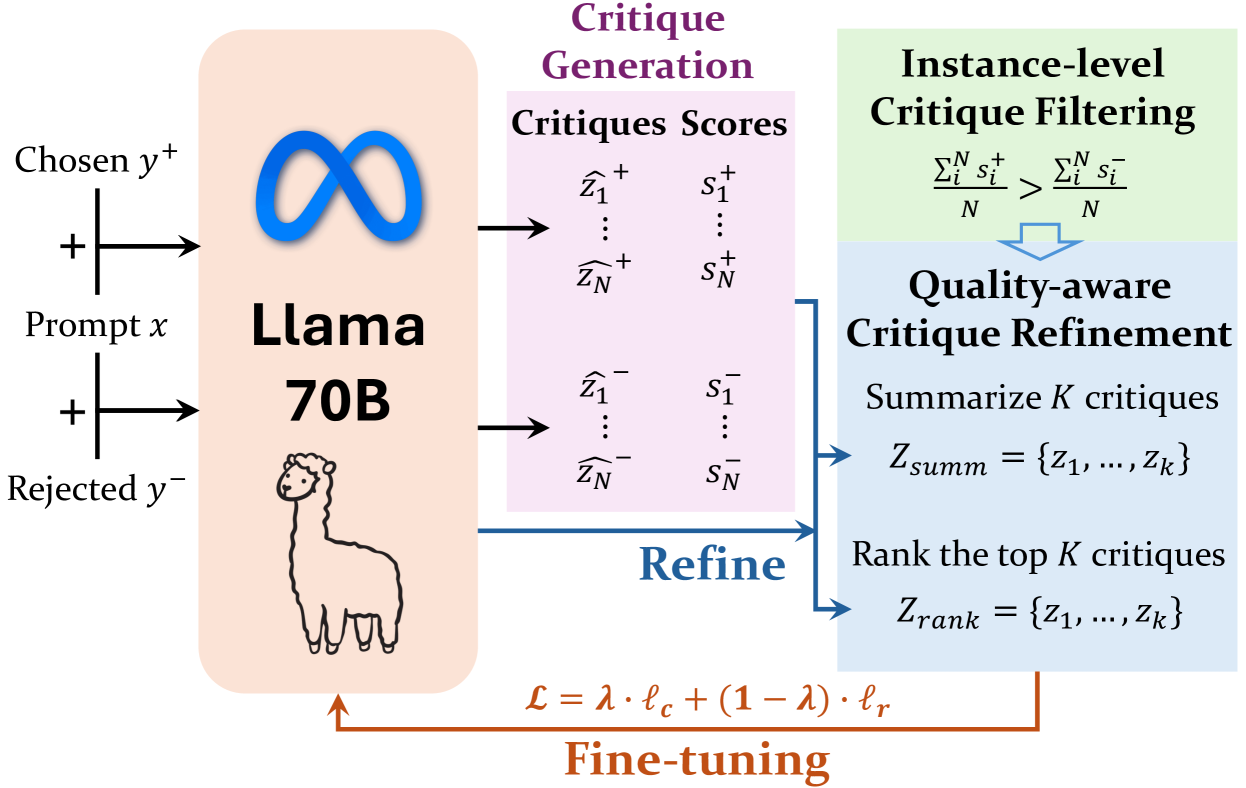
技术框架:Critic-RM包含两个主要阶段:评判生成与过滤和联合微调。在评判生成与过滤阶段,首先使用语言模型生成对不同生成结果的评判,然后使用过滤机制筛选出高质量的评判。在联合微调阶段,将筛选后的评判数据与标量奖励数据结合起来,对奖励模型进行微调,使其能够同时预测奖励和生成评判。
关键创新:Critic-RM的关键创新在于利用自生成评判来增强奖励模型。与传统的只预测标量奖励的奖励模型相比,Critic-RM能够提供更丰富的反馈信息,帮助语言模型更好地理解人类偏好。此外,Critic-RM无需额外的人工标注评判数据,降低了训练成本。
关键设计:在评判生成阶段,可以使用不同的语言模型生成评判,例如,可以使用经过指令微调的LLM。在评判过滤阶段,可以使用各种指标来评估评判的质量,例如,可以使用语言模型的困惑度或基于规则的方法。在联合微调阶段,可以使用不同的损失函数来训练奖励模型,例如,可以使用交叉熵损失函数来训练评判生成模块,并使用均方误差损失函数来训练奖励预测模块。具体的参数设置和网络结构需要根据具体的应用场景进行调整。
🖼️ 关键图片
📊 实验亮点
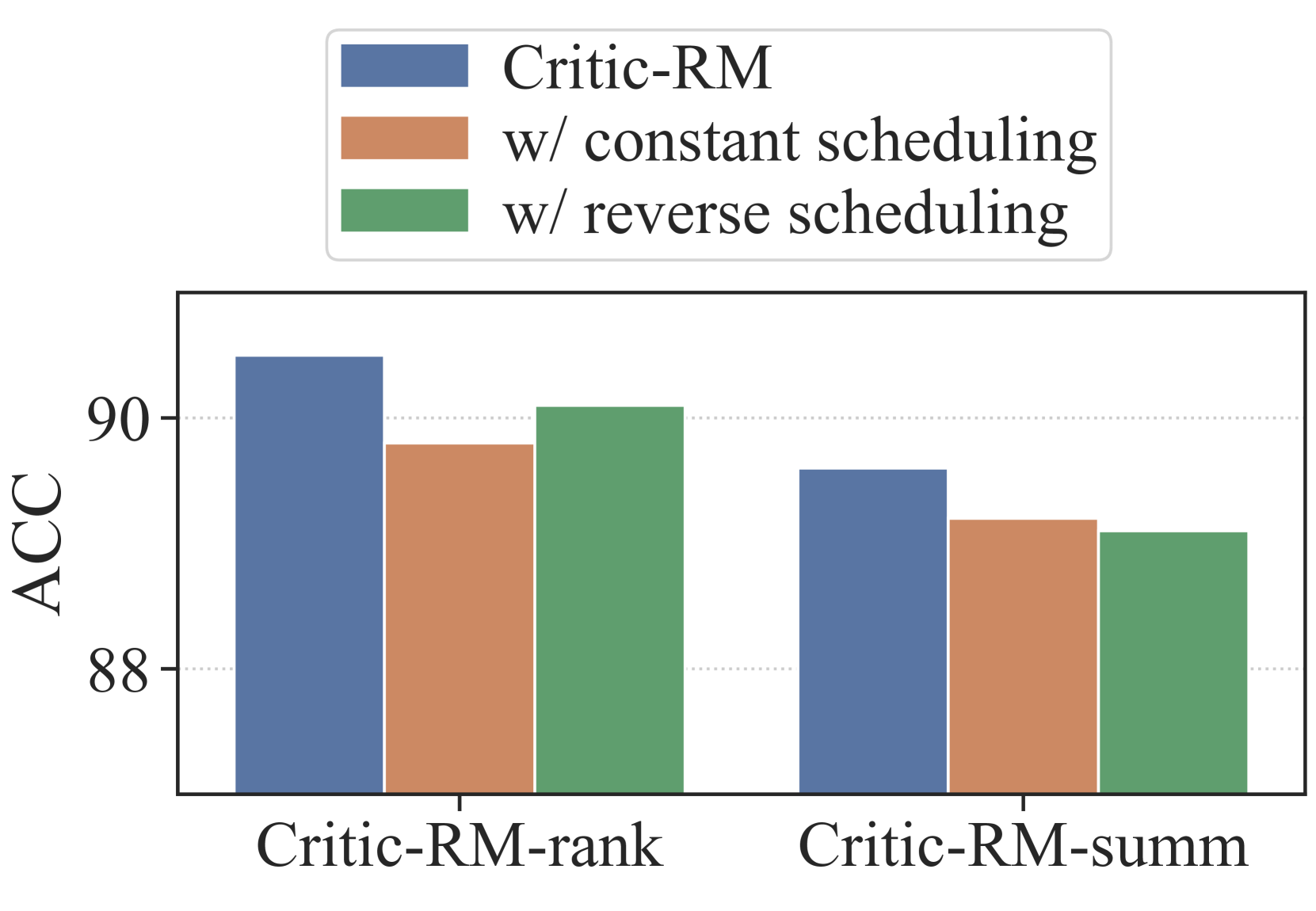
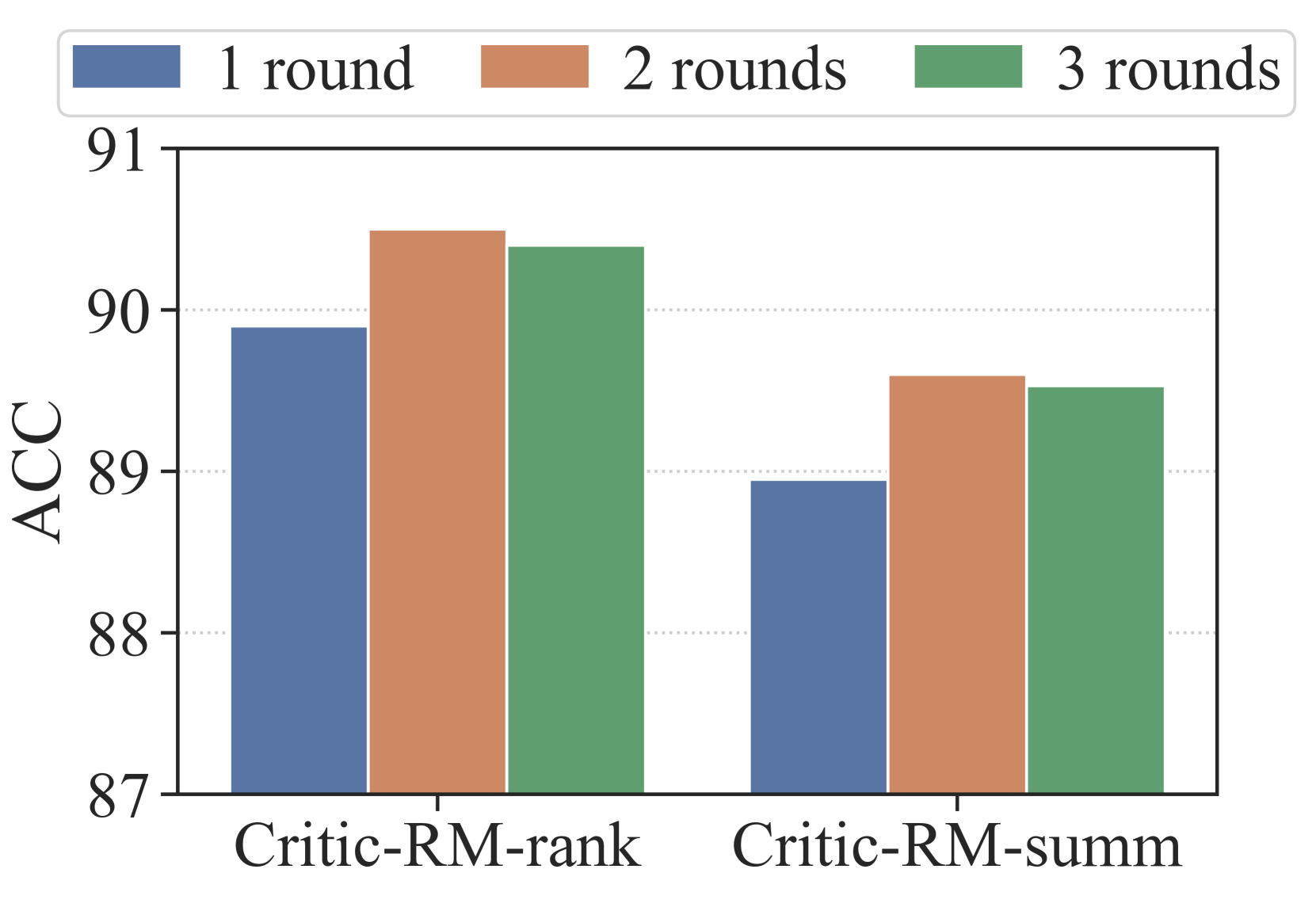
实验结果表明,Critic-RM在多个基准测试中显著提高了奖励建模的准确性,提升幅度为3.7%-7.3%,优于标准奖励模型和LLM judges。此外,Critic-RM还能够有效纠正语言模型推理过程中的错误,从而将推理精度提高2.5%-3.2%。这些结果表明,Critic-RM是一种有效且数据高效的奖励建模方法。
🎯 应用场景
Critic-RM可应用于各种需要将语言模型与人类偏好对齐的场景,例如对话系统、文本摘要、代码生成等。通过提供更细粒度的反馈信息,Critic-RM可以帮助语言模型生成更符合人类偏好的结果,提高用户满意度。此外,该方法还可以用于改进语言模型的推理能力,提高其在各种任务上的性能。
📄 摘要(原文)
Reward modeling is crucial for aligning large language models (LLMs) with human preferences, especially in reinforcement learning from human feedback (RLHF). However, current reward models mainly produce scalar scores and struggle to incorporate critiques in a natural language format. We hypothesize that predicting both critiques and the scalar reward would improve reward modeling ability. Motivated by this, we propose Critic-RM, a framework that improves reward models using self-generated critiques without extra supervision. Critic-RM employs a two-stage process: generating and filtering high-quality critiques, followed by joint fine-tuning on reward prediction and critique generation. Experiments across benchmarks show that Critic-RM improves reward modeling accuracy by 3.7%-7.3% compared to standard reward models and LLM judges, demonstrating strong performance and data efficiency. Additional studies further validate the effectiveness of generated critiques in rectifying flawed reasoning steps with 2.5%-3.2% gains in improving reasoning accuracy.