AtomR: Atomic Operator-Empowered Large Language Models for Heterogeneous Knowledge Reasoning
作者: Amy Xin, Jinxin Liu, Zijun Yao, Zhicheng Lee, Shulin Cao, Lei Hou, Juanzi Li
分类: cs.CL
发布日期: 2024-11-25 (更新: 2025-09-26)
💡 一句话要点
AtomR:原子操作赋能大语言模型,用于异构知识推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 知识推理 异构知识 原子操作 检索增强生成
📋 核心要点
- 现有大语言模型在知识密集型推理中面临组合推理能力不足和幻觉问题,限制了其性能。
- AtomR框架通过引入原子知识操作符,将复杂问题分解为细粒度的推理树,实现更精确的知识检索和操作。
- 实验表明,AtomR在多个数据集上显著优于现有方法,尤其在异构知识推理任务中表现突出。
📝 摘要(中文)
尽管大型语言模型(LLMs)具有出色的能力,但由于其在组合推理方面的局限性和幻觉问题,知识密集型推理仍然是一项具有挑战性的任务。一种常见的解决方案是采用思维链(CoT)与检索增强生成(RAG),该方法首先通过将复杂问题分解为更简单的子问题来制定推理计划,然后在每个子问题上应用迭代RAG。然而,先前的工作存在两个关键问题:推理计划不充分和异构知识整合不佳。在本文中,我们介绍了AtomR,一个用于LLMs在原子级别进行准确异构知识推理的框架。受到知识图查询语言通过组合预定义操作来建模组合推理的启发,我们提出了三个原子知识操作符,这是一组统一的操作符,供LLMs从异构来源检索和操作知识。首先,在推理计划阶段,AtomR将复杂问题分解为推理树,其中每个叶节点对应于一个原子知识操作符,从而实现高度细粒度和正交的问题分解。随后,在推理执行阶段,AtomR执行每个原子知识操作符,从而灵活地选择、检索和操作来自异构来源的原子级别知识。我们还介绍了BlendQA,这是一个专门为异构知识推理量身定制的具有挑战性的基准。在三个单源和两个多源数据集上的实验表明,AtomR的性能大大优于最先进的基线,在2WikiMultihop上的F1得分提高了9.4%,在BlendQA上的F1得分提高了9.5%。我们发布了我们的代码和数据集。
🔬 方法详解
问题定义:现有的大语言模型在知识密集型推理任务中,尤其是在需要组合多个知识源进行推理时,表现出不足。现有的CoT和RAG方法在推理计划的制定和异构知识的有效整合方面存在局限性,导致推理过程不够准确,容易产生幻觉。
核心思路:AtomR的核心思路是将复杂的推理过程分解为一系列原子操作,每个操作负责从特定的知识源检索或操作特定的知识片段。通过组合这些原子操作,可以构建复杂的推理路径,从而更有效地利用异构知识。这种方法借鉴了知识图查询语言的思想,将推理过程建模为一系列可执行的操作。
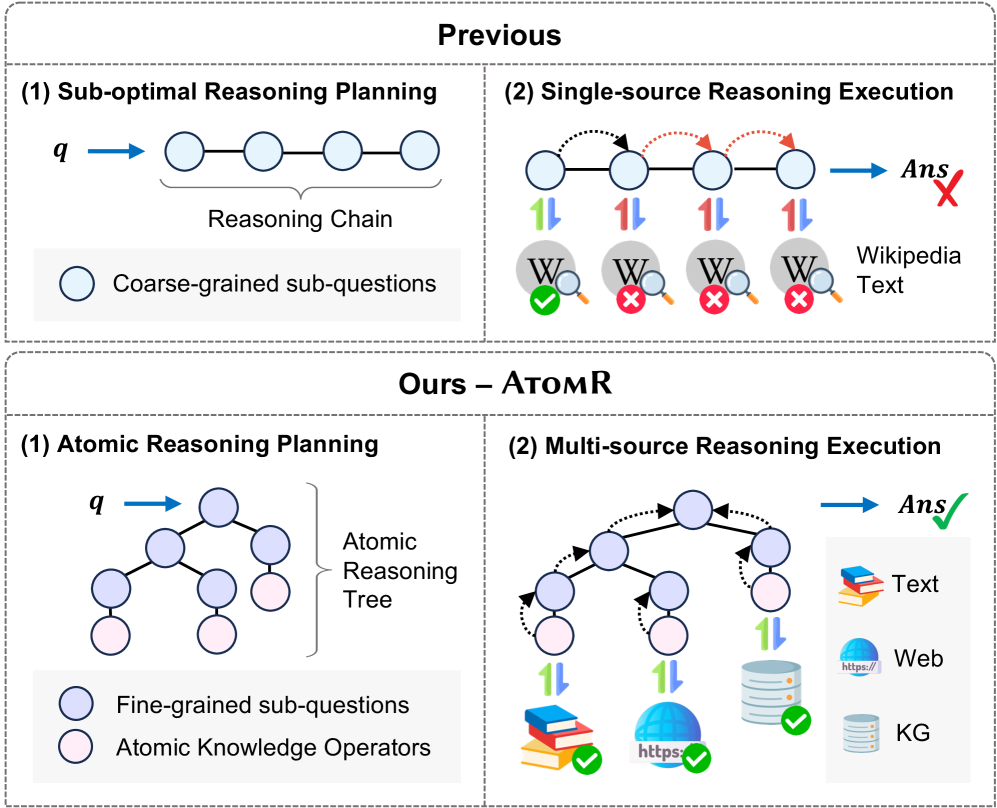
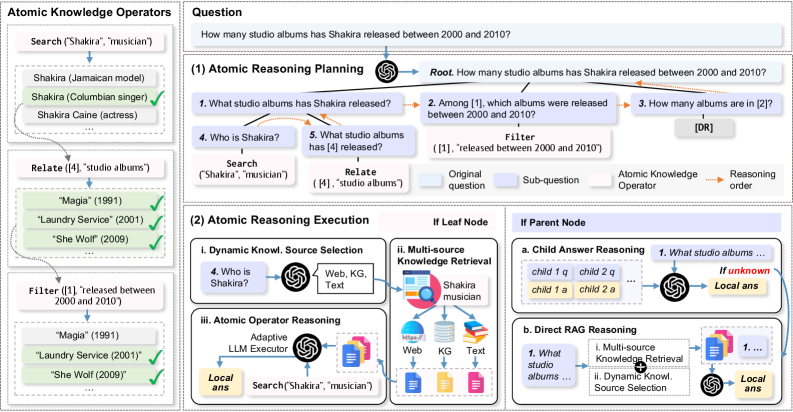
技术框架:AtomR框架包含两个主要阶段:推理计划阶段和推理执行阶段。在推理计划阶段,AtomR将复杂问题分解为一个推理树,树的每个叶节点对应一个原子知识操作符。这些操作符包括知识检索、知识组合和知识验证等。在推理执行阶段,AtomR按照推理树的结构,依次执行每个原子知识操作符,从异构知识源中检索和操作知识,最终得到答案。
关键创新:AtomR的关键创新在于引入了原子知识操作符的概念,并设计了一组统一的操作符,用于从异构知识源中检索和操作知识。这种方法使得推理过程更加模块化和可控,可以更有效地利用异构知识,并减少幻觉的产生。与现有方法相比,AtomR的推理计划更加细粒度和正交,可以更好地适应复杂的问题。
关键设计:AtomR的关键设计包括三个原子知识操作符的具体实现,以及推理树的构建算法。具体的操作符包括:1) 知识检索操作符,用于从知识库中检索相关知识;2) 知识组合操作符,用于将多个知识片段组合成一个完整的知识;3) 知识验证操作符,用于验证知识的正确性。推理树的构建算法需要根据问题的特点,选择合适的原子操作符,并确定它们之间的依赖关系。
🖼️ 关键图片

📊 实验亮点
AtomR在多个数据集上取得了显著的性能提升。在2WikiMultihop数据集上,AtomR的F1得分比最先进的基线提高了9.4%。在专门为异构知识推理设计的BlendQA数据集上,AtomR的F1得分提高了9.5%。这些结果表明,AtomR在异构知识推理方面具有显著的优势。
🎯 应用场景
AtomR框架可应用于问答系统、智能助手、知识图谱推理等领域。通过更有效地利用异构知识,AtomR可以提高这些应用在复杂推理任务中的准确性和可靠性。未来,AtomR有望在医疗诊断、金融分析等需要高度精确知识推理的领域发挥重要作用。
📄 摘要(原文)
Despite the outstanding capabilities of large language models (LLMs), knowledge-intensive reasoning still remains a challenging task due to LLMs' limitations in compositional reasoning and the hallucination problem. A prevalent solution is to employ chain-of-thought (CoT) with retrieval-augmented generation (RAG), which first formulates a reasoning plan by decomposing complex questions into simpler sub-questions, and then applies iterative RAG at each sub-question. However, prior works exhibit two crucial problems: inadequate reasoning planning and poor incorporation of heterogeneous knowledge. In this paper, we introduce AtomR, a framework for LLMs to conduct accurate heterogeneous knowledge reasoning at the atomic level. Inspired by how knowledge graph query languages model compositional reasoning through combining predefined operations, we propose three atomic knowledge operators, a unified set of operators for LLMs to retrieve and manipulate knowledge from heterogeneous sources. First, in the reasoning planning stage, AtomR decomposes a complex question into a reasoning tree where each leaf node corresponds to an atomic knowledge operator, achieving question decomposition that is highly fine-grained and orthogonal. Subsequently, in the reasoning execution stage, AtomR executes each atomic knowledge operator, which flexibly selects, retrieves, and operates atomic level knowledge from heterogeneous sources. We also introduce BlendQA, a challenging benchmark specially tailored for heterogeneous knowledge reasoning. Experiments on three single-source and two multi-source datasets show that AtomR outperforms state-of-the-art baselines by a large margin, with F1 score improvements of 9.4% on 2WikiMultihop and 9.5% on BlendQA. We release our code and datasets.