Multi-modal Retrieval Augmented Multi-modal Generation: Datasets, Evaluation Metrics and Strong Baselines
作者: Zi-Ao Ma, Tian Lan, Rong-Cheng Tu, Yong Hu, Yu-Shi Zhu, Tong Zhang, Heyan Huang, Zhijing Wu, Xian-Ling Mao
分类: cs.CL
发布日期: 2024-11-25 (更新: 2025-05-23)
💡 一句话要点
提出多模态检索增强多模态生成框架M²RAG,并构建数据集、评估指标和基线模型。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态检索增强生成 多模态学习 基础模型 数据集构建 评估指标 多模态融合 信息检索
📋 核心要点
- 现有方法难以有效处理多模态网络内容,并生成信息密度和可读性高的多模态响应,缺乏高质量数据集和评估指标。
- 论文提出多模态检索增强多模态生成框架M²RAG,利用检索增强技术,使模型能够处理多模态信息并生成多模态响应。
- 实验结果表明,微调的7B-8B模型性能优于GPT-4o,接近OpenAI o3-mini,验证了所提指标的可靠性和数据管理流程的有效性。
📝 摘要(中文)
本文对多模态检索增强多模态生成(M²RAG)进行了系统研究。M²RAG是一项新任务,旨在使基础模型能够处理多模态网络内容并生成多模态响应,从而提高信息密度和可读性。尽管具有潜在的影响,但M²RAG仍未得到充分研究,缺乏全面的分析和高质量的数据资源。为了解决这个问题,我们通过严格的数据管理流程建立了一个全面的基准,并采用基于基础模型的文本模态指标和多模态指标进行评估。我们进一步提出了几种策略,使基础模型能够有效地处理M²RAG任务,并通过使用我们设计的指标过滤高质量样本来构建训练集。大量的实验证明了我们提出的指标的可靠性,展示了我们设计的策略中的模型性能,并表明我们微调的7B-8B模型优于GPT-4o模型,并接近最先进的OpenAI o3-mini。此外,我们对不同领域进行了细粒度的分析,并验证了我们的设计在数据管理流程中的有效性。所有资源,包括代码、数据集和模型权重,都将公开发布。
🔬 方法详解
问题定义:论文旨在解决多模态检索增强多模态生成(M²RAG)任务,即如何让基础模型能够处理多模态网络内容(例如包含文本和图像的网页),并生成信息丰富且易于理解的多模态响应。现有方法在处理复杂的多模态信息时存在困难,并且缺乏高质量的数据集和有效的评估指标,限制了该领域的发展。
核心思路:论文的核心思路是利用检索增强生成(RAG)的思想,将多模态信息检索与多模态内容生成相结合。通过检索相关信息,模型可以更好地理解输入的多模态内容,并生成更准确、更丰富的多模态响应。此外,论文还设计了新的评估指标和数据过滤策略,以提高模型的性能和泛化能力。
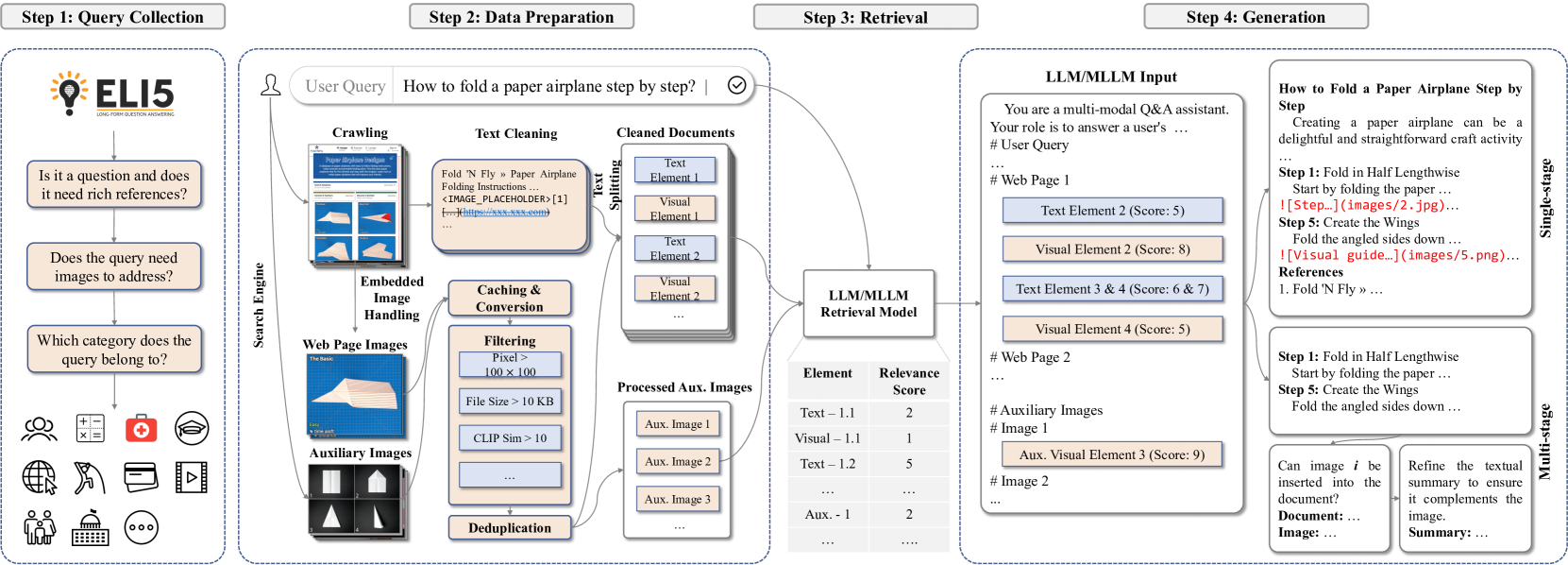
技术框架:M²RAG框架包含以下主要模块:1) 多模态信息检索模块:负责从外部知识库中检索与输入多模态内容相关的文档。2) 多模态信息融合模块:将检索到的信息与原始输入的多模态内容进行融合,形成更全面的上下文表示。3) 多模态内容生成模块:基于融合后的上下文表示,生成多模态响应。论文还提出了使用高质量样本进行训练的数据过滤策略。
关键创新:论文的关键创新在于:1) 提出了M²RAG任务,填补了多模态检索增强生成领域的空白。2) 构建了高质量的多模态数据集,并设计了新的评估指标,为该领域的研究提供了基准。3) 提出了有效的数据过滤策略,提高了模型的训练效率和性能。
关键设计:论文的关键设计包括:1) 使用基于基础模型的文本模态指标和多模态指标进行评估,以更全面地衡量模型的性能。2) 设计了多种策略来指导基础模型处理M²RAG任务,例如使用不同的检索方法和融合策略。3) 通过过滤高质量样本来构建训练集,以提高模型的训练效率和性能。具体的参数设置、损失函数和网络结构等技术细节在论文中进行了详细描述(未知)。
🖼️ 关键图片
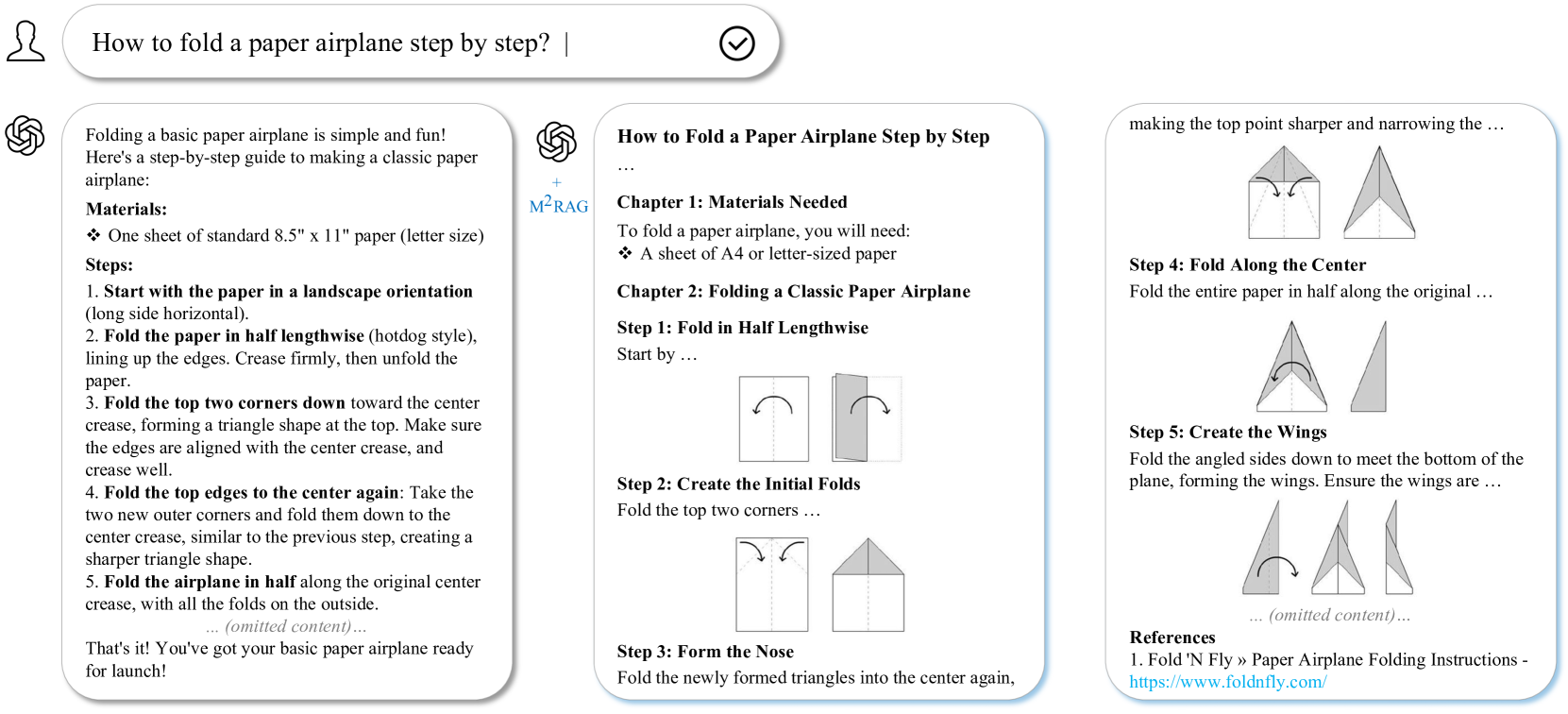
📊 实验亮点
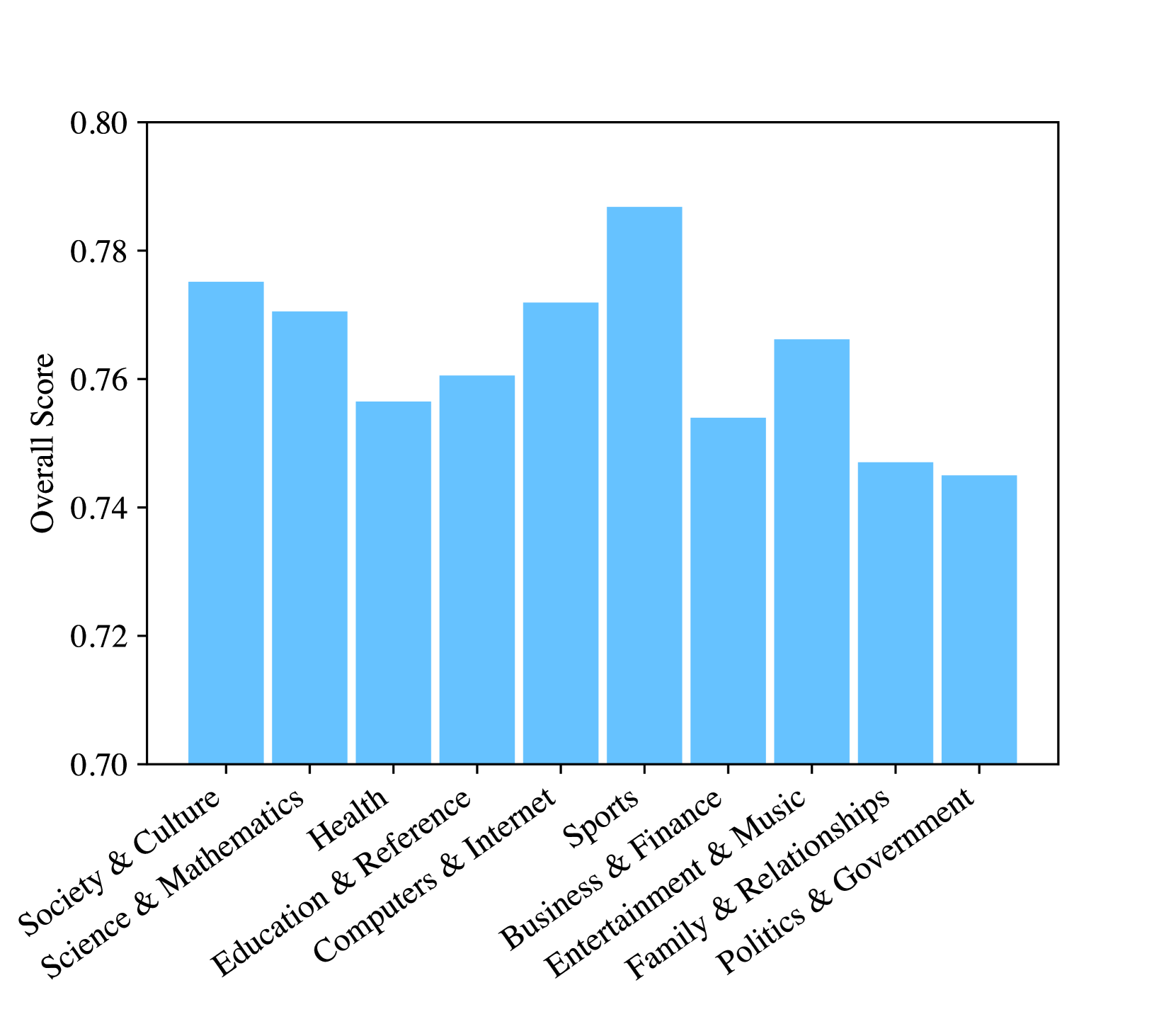
实验结果表明,经过微调的7B-8B模型在M²RAG任务上表现出色,性能优于GPT-4o模型,并接近最先进的OpenAI o3-mini模型。论文提出的评估指标和数据过滤策略也得到了验证,能够有效提高模型的性能和泛化能力。这些结果表明,M²RAG框架具有很大的潜力,有望成为多模态人工智能领域的重要研究方向。
🎯 应用场景
该研究成果可应用于智能客服、多模态内容创作、教育辅助等领域。例如,智能客服可以利用M²RAG框架处理用户上传的图片和文字,并生成包含图片和文字的回复,从而更有效地解决用户的问题。多模态内容创作工具可以利用该框架生成更丰富、更具吸引力的内容。教育领域可以利用该框架生成多模态教学材料,提高学生的学习效果。未来,该技术有望在更多领域得到应用,推动多模态人工智能的发展。
📄 摘要(原文)
We present a systematic investigation of Multi-modal Retrieval Augmented Multi-modal Generation (M$^2$RAG), a novel task that enables foundation models to process multi-modal web content and generate multi-modal responses, which exhibits better information density and readability. Despite its potential impact, M$^2$RAG remains understudied, lacking comprehensive analysis and high-quality data resources. To address this gap, we establish a comprehensive benchmark through a rigorous data curation pipeline, and employ text-modal metrics and multi-modal metrics based on foundation models for evaluation. We further propose several strategies for foundation models to process M$^2$RAG task effectively and construct a training set by filtering high-quality samples using our designed metrics. Our extensive experiments demonstrate the reliability of our proposed metrics, a landscape of model performance within our designed strategies, and show that our fine-tuned 7B-8B models outperform the GPT-4o model and approach the state-of-the-art OpenAI o3-mini. Additionally, we perform fine-grained analyses across diverse domains and validate the effectiveness of our designs in data curation pipeline. All resources, including codes, datasets, and model weights, will be publicly released.