Lessons from Studying Two-Hop Latent Reasoning
作者: Mikita Balesni, Tomek Korbak, Owain Evans
分类: cs.CL, cs.AI
发布日期: 2024-11-25 (更新: 2025-11-23)
💡 一句话要点
研究表明大语言模型具备潜在的双跳推理能力,但事实组合仍具挑战
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 双跳推理 潜在推理 合成数据集 知识图谱问答
📋 核心要点
- 现有研究对LLM潜在双跳推理能力存在争议,缺乏明确证据,且易受记忆和捷径影响。
- 论文通过在合成数据集上微调LLM,排除了记忆和推理捷径,从而控制实验环境,验证潜在推理能力。
- 实验表明LLM具备潜在双跳推理能力,但组合两个合成事实仍存在困难,提示模型推理能力存在局限。
📝 摘要(中文)
大型语言模型(LLM)可以使用思维链(CoT)来外化推理过程,从而实现对LLM智能体的监督。先前的研究表明,模型在没有CoT的情况下难以完成双跳问答。这种能力非常基础,如果它是一个根本性的限制,那么许多复杂的智能体任务也将需要CoT。本文以双跳问答为例,研究了LLM的潜在推理能力。先前关于潜在和外化双跳推理之间差距的研究产生了混合证据,结果不确定。本文引入了一个受控环境来研究LLM中的双跳推理,其中积极的结果为潜在推理提供了明确的证据。我们使用合成事实对LLM(包括Llama 3 8B和GPT-4o)进行微调,并测试基于这些事实的双跳推理。通过使用合成事实,我们排除了记忆和推理捷径作为双跳性能的解释。我们观察到一个细致的画面:模型无法组合两个合成事实,但当一个事实是合成的,另一个是自然的时,可以成功。这些结果表明,LLM无疑具有潜在的双跳推理能力,尽管这种能力如何随模型大小扩展仍不清楚。最后,我们强调了研究LLM推理的研究人员应该吸取的教训:在得出关于LLM潜在推理的结论时,必须小心避免虚假的成功(源于记忆和推理捷径)和虚假的失败(可能源于人为的实验设置,与前沿LLM的训练设置脱节)。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLM)是否具备潜在的双跳推理能力,即在没有显式思维链(CoT)的情况下,能否通过两个步骤的推理来回答问题。现有研究结果不一致,且容易受到模型记忆和推理捷径的影响,难以准确评估LLM的真实推理能力。
核心思路:论文的核心思路是通过构建一个受控的实验环境,使用合成事实对LLM进行微调,从而排除记忆和推理捷径的干扰。通过这种方式,如果模型能够在合成数据集上成功进行双跳推理,则可以明确证明其具备潜在的推理能力。
技术框架:论文的技术框架主要包括以下几个步骤:1) 构建合成事实数据集,确保模型在训练集中没有直接记忆答案;2) 使用合成事实对LLM(包括Llama 3 8B和GPT-4o)进行微调;3) 设计双跳问答测试集,测试模型在合成事实上的推理能力;4) 分析模型在不同情况下的表现,例如组合两个合成事实或组合一个合成事实和一个自然事实。
关键创新:论文的关键创新在于使用合成事实来控制实验环境,从而排除了记忆和推理捷径的干扰。这种方法能够更准确地评估LLM的潜在推理能力,并为未来的研究提供了一个可靠的基准。此外,论文还发现LLM在组合两个合成事实时存在困难,这提示模型在复杂推理方面仍存在局限性。
关键设计:论文的关键设计包括:1) 合成事实的生成方式,需要确保事实的逻辑关系清晰,且模型在训练集中没有直接记忆答案;2) 双跳问答测试集的构建,需要包含不同类型的推理问题,例如组合两个合成事实或组合一个合成事实和一个自然事实;3) 模型微调的参数设置,需要根据不同的模型和数据集进行调整,以获得最佳的推理性能。
🖼️ 关键图片
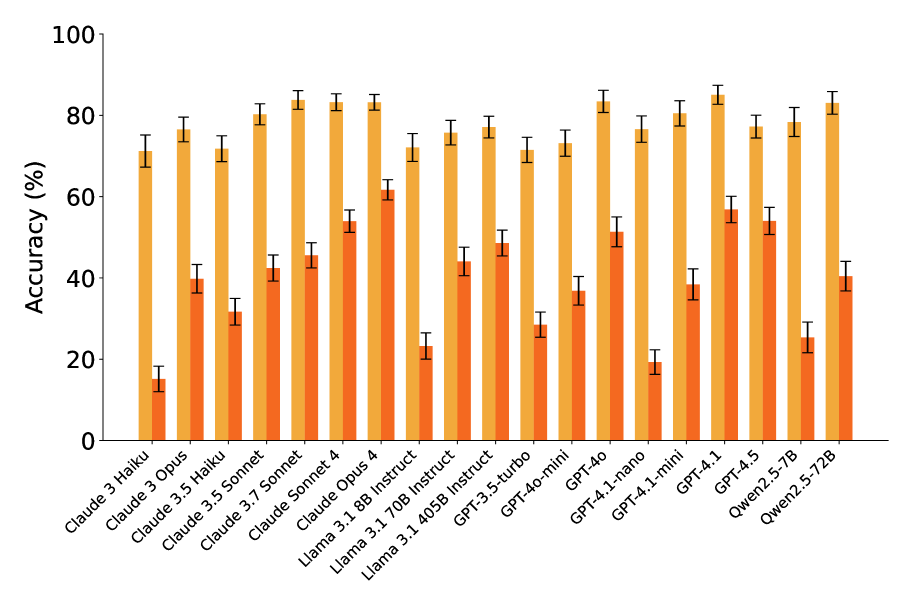

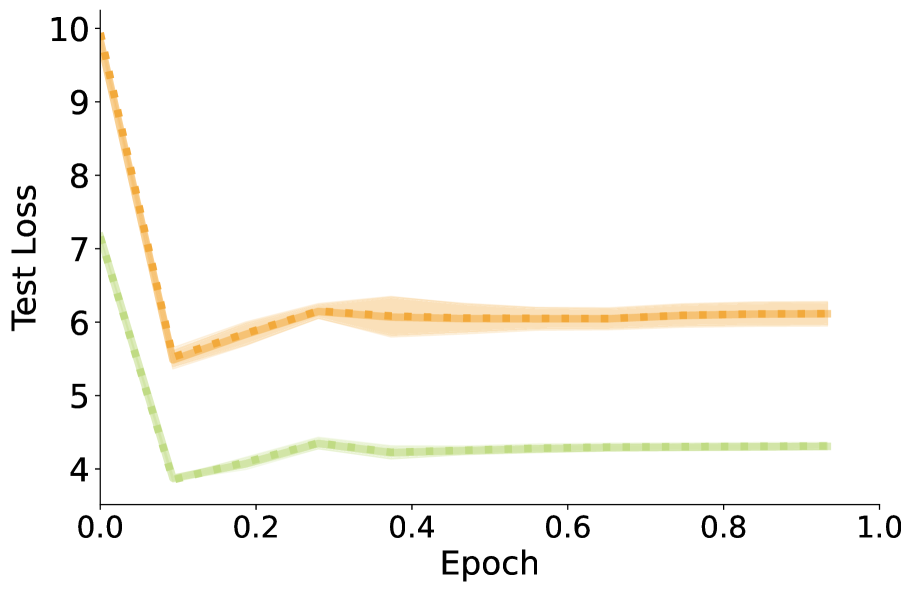
📊 实验亮点
实验结果表明,LLM(包括Llama 3 8B和GPT-4o)具备潜在的双跳推理能力,但模型无法有效组合两个合成事实。当组合一个合成事实和一个自然事实时,模型表现出较好的推理能力。这些结果揭示了LLM在推理能力上的细微差别,并为未来的研究提供了重要的方向。
🎯 应用场景
该研究成果可应用于提升LLM在知识图谱问答、复杂逻辑推理等领域的性能。通过理解LLM的推理能力边界,可以更好地设计智能体,并提高其在实际任务中的可靠性。未来的研究可以探索如何进一步提升LLM在合成事实上的推理能力,并将其应用于更复杂的推理场景。
📄 摘要(原文)
Large language models can use chain-of-thought (CoT) to externalize reasoning, potentially enabling oversight of capable LLM agents. Prior work has shown that models struggle at two-hop question-answering without CoT. This capability is so basic that if it was a fundamental limitation, it would imply that many complex agentic tasks would similarly require CoT. We investigate LLM latent reasoning capabilities using two-hop question answering as a case study. Previous work on the gap between latent and externalized two-hop reasoning produced mixed evidence with inconclusive results. In this paper, we introduce a controlled setting for investigating two-hop reasoning in LLMs, where a positive result provides definitive evidence for latent reasoning. We fine-tune LLMs (including Llama 3 8B and GPT-4o) on synthetic facts and test two-hop reasoning over these facts. By using synthetic facts, we rule out memorization and reasoning shortcuts as explanations for two-hop performance. We observe a nuanced picture: Models fail to compose two synthetic facts, but can succeed when one fact is synthetic and the other is natural. These results demonstrate that LLMs are undeniably capable of latent two-hop reasoning, although it remains unclear how this ability scales with model size. Finally, we highlight a lesson for researchers studying LLM reasoning: when drawing conclusions about LLM latent reasoning, one must be careful to avoid both spurious successes (that stem from memorization and reasoning shortcuts) and spurious failures (that may stem from artificial experimental setups, divorced from training setups of frontier LLMs).