NormXLogit: The Head-on-Top Never Lies
作者: Sina Abbasi, Mohammad Reza Modarres, Mohammad Taher Pilehvar
分类: cs.CL
发布日期: 2024-11-25 (更新: 2025-08-18)
备注: Added comparisons on computational efficiency, included experiments on a new dataset with an additional evaluation metric for classification tasks, expanded explanations and discussions in the experiments, and presented a worked example for alignment metrics computation
💡 一句话要点
提出NormXLogit,一种模型无关的LLM可解释性方法,提升token重要性评估的忠实性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 可解释性 token重要性 模型无关 词嵌入范数
📋 核心要点
- 现有LLM可解释性方法依赖模型特定设计,计算成本高,通用性不足。
- NormXLogit基于token的输入输出表示,通过词嵌入范数和预测相似性评估token重要性。
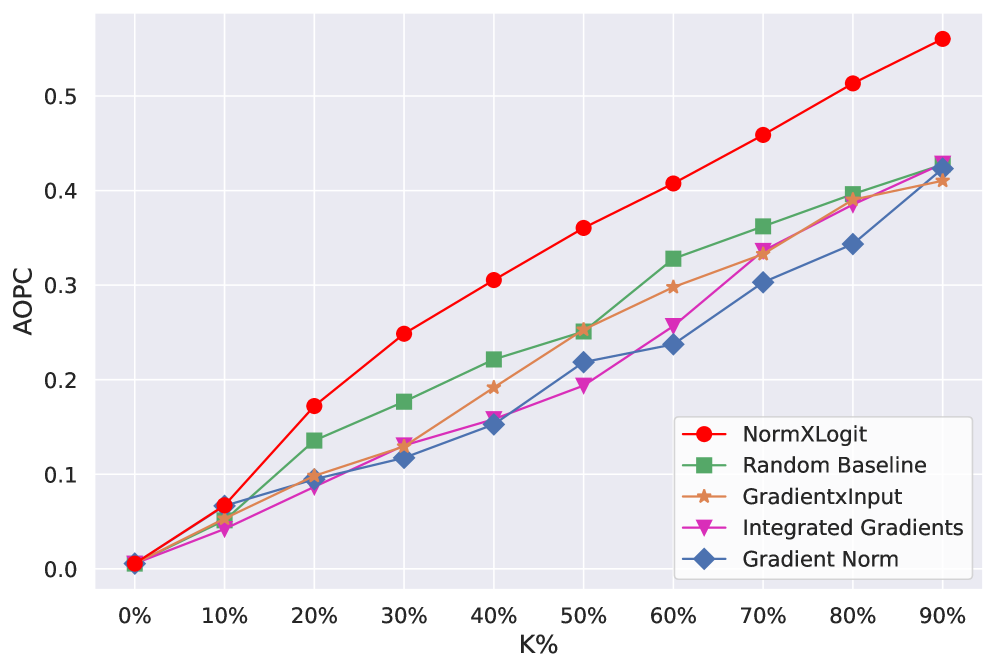
- 实验表明,NormXLogit在忠实性上优于梯度方法,且层级解释性能与特定架构方法相当。
📝 摘要(中文)
随着大型语言模型(LLM)的快速发展,考虑模型无关方法在不同架构上的可解释性价值至关重要。虽然LLM可解释性的最新进展展现了前景,但许多方法依赖于复杂的、模型特定的方法,计算成本高昂。为了解决这些局限性,我们提出NormXLogit,一种用于评估单个输入token重要性的新颖技术。该方法基于与每个token相关的输入和输出表示。首先,我们证明了在LLM的预训练期间,词嵌入的范数有效地捕捉了token的重要性。其次,我们揭示了token的重要性与其表示能够多大程度上类似于模型的最终预测之间存在显著关系。广泛的分析表明,我们的方法在忠实性方面优于现有的基于梯度的方法,并且在逐层解释方面提供了与领先的架构特定技术相当的性能。
🔬 方法详解
问题定义:现有LLM可解释性方法,如基于梯度的方法,通常计算成本高昂,且严重依赖于特定模型的架构,缺乏通用性。这限制了它们在不同LLM上的应用,并可能导致对模型行为的不准确解释。因此,需要一种模型无关、计算效率高且能提供忠实解释的方法。
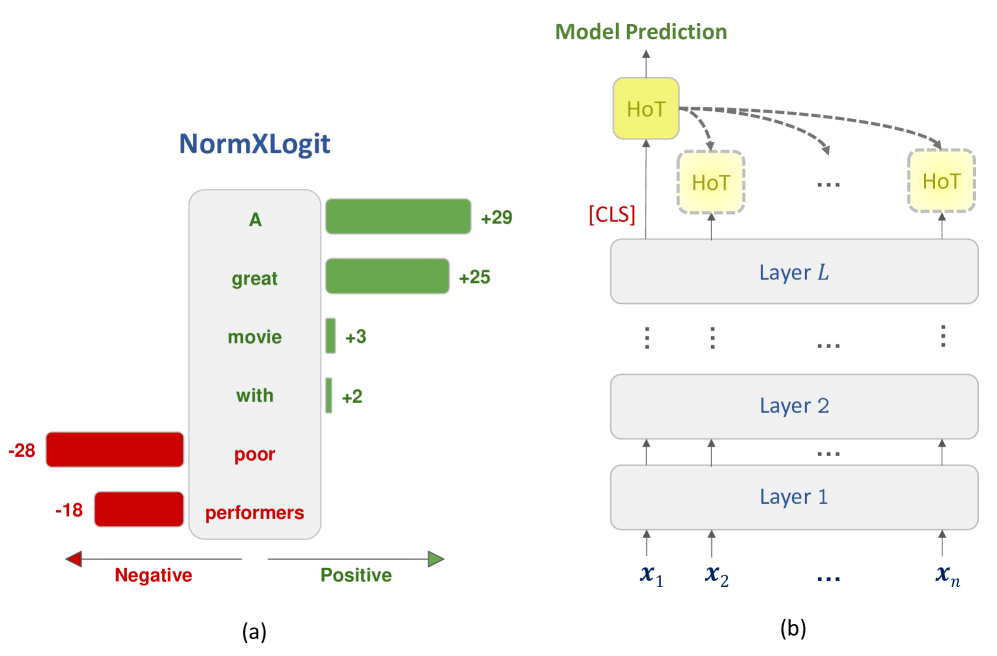
核心思路:NormXLogit的核心思路是利用LLM预训练过程中学习到的token嵌入的范数来衡量token的重要性。同时,该方法还考虑了token的表示与模型最终预测之间的相似性。作者认为,重要的token应该具有较大的嵌入范数,并且其表示应该与模型的最终预测更加相似。
技术框架:NormXLogit方法主要包含两个步骤:1) 计算每个token的嵌入范数。2) 计算每个token的表示与模型最终预测之间的相似性。然后,将这两个指标结合起来,得到每个token的重要性得分。该方法不需要访问模型的内部参数或梯度信息,因此具有模型无关性。
关键创新:NormXLogit的关键创新在于它是一种模型无关的可解释性方法,不需要针对特定模型进行调整。它利用了LLM预训练过程中学习到的token嵌入的范数和token表示与最终预测的相似性,从而提供了一种简单而有效的token重要性评估方法。与现有的基于梯度的方法相比,NormXLogit具有更高的计算效率和更好的忠实性。
关键设计:NormXLogit的关键设计包括:1) 使用词嵌入的L2范数作为token重要性的初步指标。2) 使用余弦相似度来衡量token表示与模型最终预测之间的相似性。3) 通过加权平均的方式将嵌入范数和余弦相似度结合起来,得到最终的token重要性得分。权重参数可以通过实验进行调整,以获得最佳的解释性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,NormXLogit在忠实性方面优于现有的基于梯度的方法。具体来说,在token删除和插入任务中,NormXLogit能够更准确地识别对模型预测影响最大的token。此外,NormXLogit在逐层解释方面提供了与领先的架构特定技术相当的性能,同时具有更高的计算效率。
🎯 应用场景
NormXLogit可应用于各种LLM的可解释性分析,帮助研究人员和开发人员理解模型的行为,诊断潜在的偏差,并改进模型的性能。此外,该方法还可以用于评估不同LLM的token重要性,从而为模型选择和优化提供指导。该方法具有模型无关性,因此可以广泛应用于各种LLM,具有很高的实际价值。
📄 摘要(原文)
With new large language models (LLMs) emerging frequently, it is important to consider the potential value of model-agnostic approaches that can provide interpretability across a variety of architectures. While recent advances in LLM interpretability show promise, many rely on complex, model-specific methods with high computational costs. To address these limitations, we propose NormXLogit, a novel technique for assessing the significance of individual input tokens. This method operates based on the input and output representations associated with each token. First, we demonstrate that during the pre-training of LLMs, the norms of word embeddings effectively capture token importance. Second, we reveal a significant relationship between a token's importance and the extent to which its representation can resemble the model's final prediction. Extensive analyses reveal that our approach outperforms existing gradient-based methods in terms of faithfulness and offers competitive performance in layer-wise explanations compared to leading architecture-specific techniques.