Multi-ToM: Evaluating Multilingual Theory of Mind Capabilities in Large Language Models
作者: Jayanta Sadhu, Ayan Antik Khan, Noshin Nawal, Sanju Basak, Abhik Bhattacharjee, Rifat Shahriyar
分类: cs.CL
发布日期: 2024-11-24
💡 一句话要点
Multi-ToM:评估大型语言模型在多语言环境下的心理理论能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 心理理论 多语言 跨文化 大型语言模型 社会认知
📋 核心要点
- 现有大型语言模型在跨语言和文化背景下的心理理论能力评估不足,缺乏多语言ToM数据集。
- 论文提出Multi-ToM方法,通过翻译和文化适配现有ToM数据集,构建多语言评估基准。
- 实验结果表明,语言和文化多样性显著影响LLM的ToM表现,揭示了模型社会推理能力的局限性。
📝 摘要(中文)
心理理论(ToM)是指推断和归因自己和他人心理状态的认知能力。随着大型语言模型(LLM)在社会和认知能力方面受到越来越多的评估,这些模型在不同语言和文化背景下表现出的ToM能力在多大程度上仍然不清楚。本文旨在填补这一空白,对多语言ToM能力进行了全面研究。我们的方法包括两个关键组成部分:(1)我们将现有的ToM数据集翻译成多种语言,有效地创建了一个多语言ToM数据集;(2)我们用特定文化元素丰富这些翻译,以反映与不同人群相关的社会和认知场景。我们对六个最先进的LLM进行了广泛的评估,以衡量它们在翻译的和文化适应的数据集上的ToM性能。结果突出了语言和文化多样性对模型表现ToM能力的影响,并质疑了它们的社会推理能力。这项工作为未来增强LLM的跨文化社会认知的研究奠定了基础,并有助于开发更具文化意识和社会智能的AI系统。我们所有的数据和代码都是公开可用的。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)在心理理论(Theory of Mind, ToM)方面的能力评估主要集中在英语数据集上,缺乏对多语言和跨文化场景的深入研究。这使得我们难以了解LLMs是否真正具备理解不同文化背景下人类心理状态的能力。现有方法的痛点在于无法有效评估LLMs在不同语言和文化环境下的社会认知能力。
核心思路:论文的核心思路是通过构建一个多语言的ToM评估基准,来系统地评估LLMs在不同语言和文化背景下的ToM能力。具体而言,该方法首先将现有的ToM数据集翻译成多种语言,然后通过引入特定文化元素来丰富这些翻译,从而创建一个更具代表性和挑战性的评估数据集。这样设计的目的是为了更全面地考察LLMs在处理不同文化背景下的社会认知任务时的表现。
技术框架:Multi-ToM的整体框架包括两个主要阶段:数据集构建和模型评估。在数据集构建阶段,首先将现有的ToM数据集翻译成多种目标语言。然后,对翻译后的数据集进行文化适配,即根据不同文化的社会规范和认知习惯,对数据集中的场景和问题进行调整。在模型评估阶段,使用构建好的多语言ToM数据集对多个LLMs进行评估,并分析它们在不同语言和文化背景下的ToM表现。
关键创新:该论文的关键创新在于构建了一个多语言且文化敏感的ToM评估基准。与以往主要依赖英语数据集的ToM评估方法不同,Multi-ToM考虑了不同语言和文化背景下的社会认知差异,从而能够更全面、更准确地评估LLMs的ToM能力。这种多语言和文化敏感的设计使得评估结果更具普适性和参考价值。
关键设计:在数据集构建方面,论文采用了高质量的机器翻译和人工校对相结合的方法,以确保翻译的准确性和流畅性。在文化适配方面,论文邀请了来自不同文化背景的专家参与,以确保文化适配的合理性和有效性。在模型评估方面,论文采用了多种评估指标,包括准确率、召回率和F1值等,以全面衡量LLMs的ToM表现。此外,论文还对不同语言和文化背景下的评估结果进行了详细的对比分析,以揭示LLMs在处理不同文化背景下的社会认知任务时的优势和不足。
🖼️ 关键图片


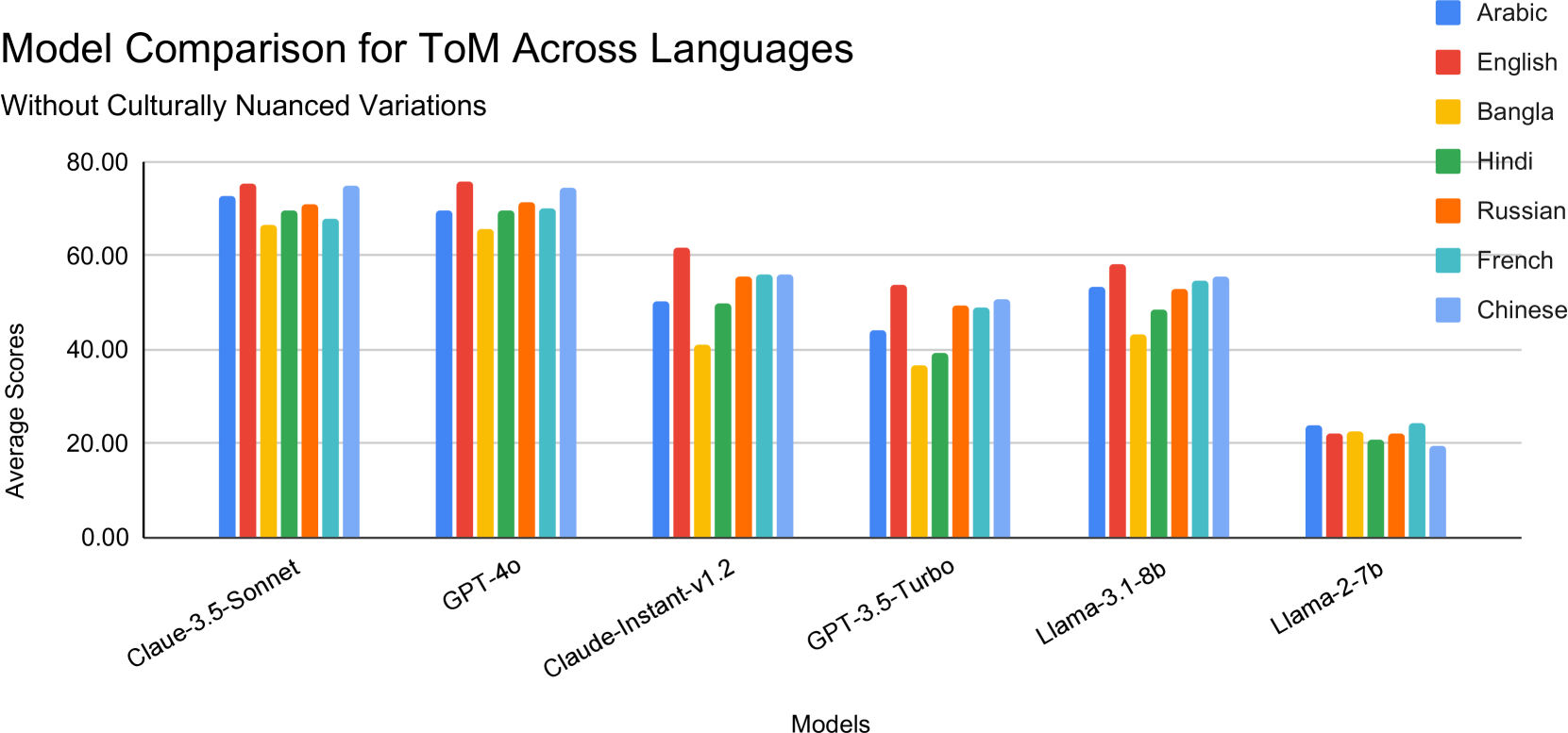
📊 实验亮点
实验结果表明,LLMs在不同语言和文化背景下的ToM表现存在显著差异,即使是性能最先进的LLMs在某些语言和文化背景下的ToM能力也远低于英语环境。例如,某些模型在英语数据集上表现出较高的准确率,但在翻译成其他语言或进行文化适配后,准确率显著下降,这表明LLMs的ToM能力可能受到语言和文化因素的限制。
🎯 应用场景
该研究成果可应用于开发更具文化意识和社会智能的AI系统,例如跨文化交流助手、个性化教育平台和智能客服。通过提升AI系统在不同文化背景下的社会认知能力,可以有效减少文化误解和冲突,促进跨文化交流与合作,并为用户提供更贴合其文化背景的个性化服务。
📄 摘要(原文)
Theory of Mind (ToM) refers to the cognitive ability to infer and attribute mental states to oneself and others. As large language models (LLMs) are increasingly evaluated for social and cognitive capabilities, it remains unclear to what extent these models demonstrate ToM across diverse languages and cultural contexts. In this paper, we introduce a comprehensive study of multilingual ToM capabilities aimed at addressing this gap. Our approach includes two key components: (1) We translate existing ToM datasets into multiple languages, effectively creating a multilingual ToM dataset and (2) We enrich these translations with culturally specific elements to reflect the social and cognitive scenarios relevant to diverse populations. We conduct extensive evaluations of six state-of-the-art LLMs to measure their ToM performance across both the translated and culturally adapted datasets. The results highlight the influence of linguistic and cultural diversity on the models' ability to exhibit ToM, and questions their social reasoning capabilities. This work lays the groundwork for future research into enhancing LLMs' cross-cultural social cognition and contributes to the development of more culturally aware and socially intelligent AI systems. All our data and code are publicly available.