Investigating Factuality in Long-Form Text Generation: The Roles of Self-Known and Self-Unknown
作者: Lifu Tu, Rui Meng, Shafiq Joty, Yingbo Zhou, Semih Yavuz
分类: cs.CL
发布日期: 2024-11-24 (更新: 2025-09-25)
💡 一句话要点
研究长文本生成的事实性问题,分析模型自知与自不知能力的影响。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长文本生成 事实性 大型语言模型 自知能力 自不知能力
📋 核心要点
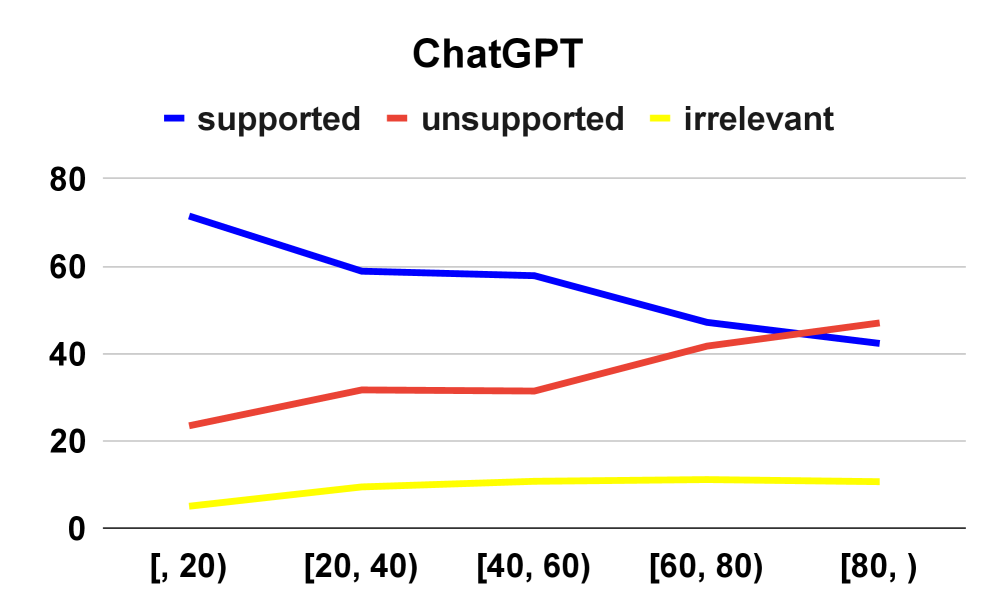
- 大型语言模型在长文本生成中存在事实性问题,容易产生真假信息混合的内容,尤其在长文本的后半部分。
- 论文通过分析LLM的自知和自不知能力,探究其与长文本生成事实性之间的关系,并提出了相应的数学模型。
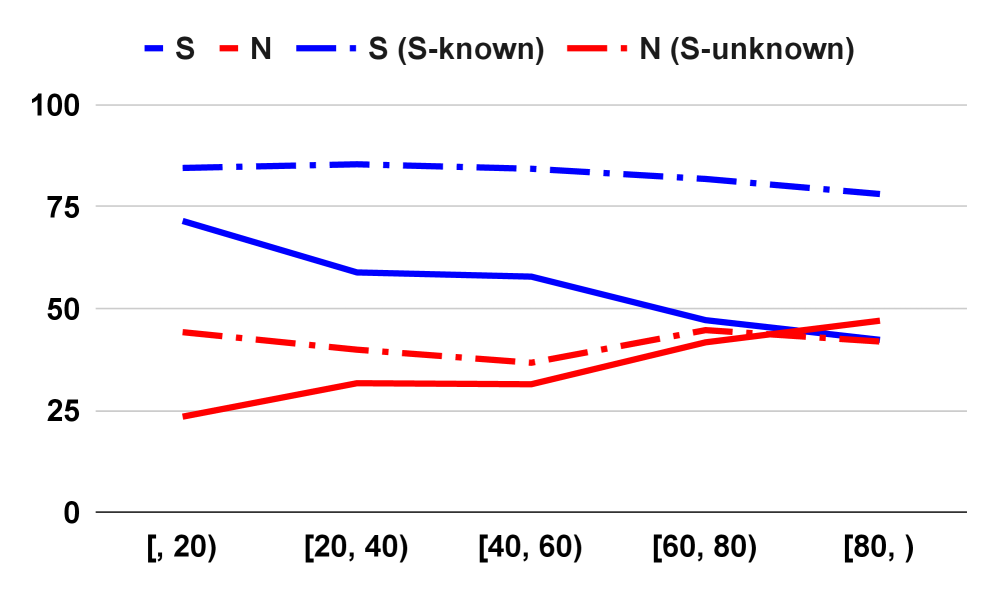
- 实验结果表明,自知能力与事实性正相关,自不知能力与事实性负相关,并揭示了RAG在提升长文本事实性方面的局限性。
📝 摘要(中文)
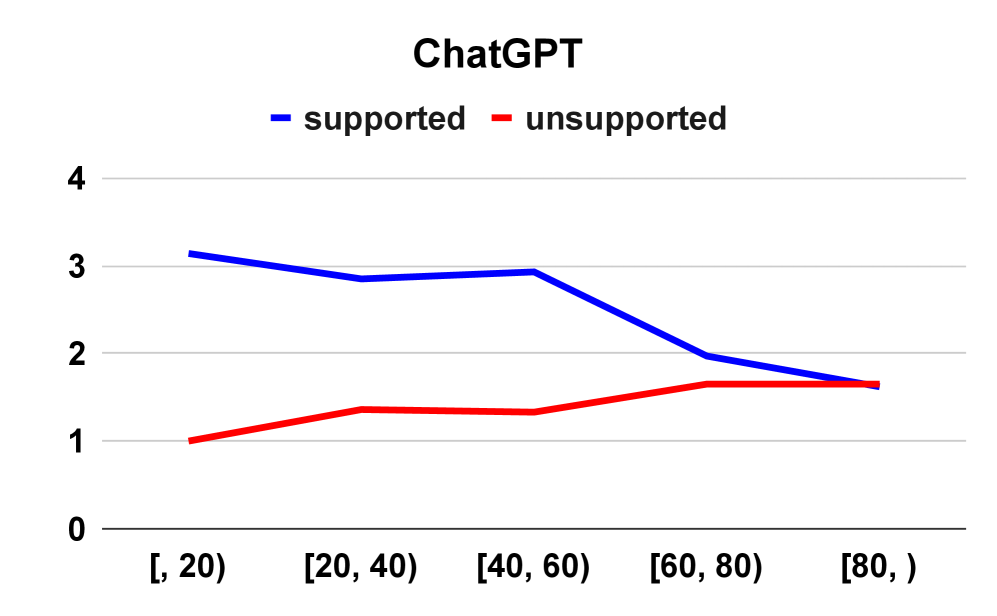
大型语言模型(LLMs)在文本理解和生成方面表现出强大的能力。然而,它们常常缺乏事实性,尤其是在长文本生成中,会产生真假信息混合的情况。本文研究了包括GPT-4、Gemini-1.5-Pro、Claude-3-Opus、Llama-3-70B和Mistral在内的各种大型语言模型(LLMs)在长文本生成中的事实性。分析表明,生成文本的后半部分事实性往往会下降,同时出现更多无依据的声明。此外,我们探索了不同的评估设置,以评估LLM是否能准确判断自身输出的正确性:自知(Self-Known,LLM判断为正确的、来自其输出的支持性原子声明的百分比)和自不知(Self-Unknown,LLM判断为不正确的、来自其输出的无依据原子声明的百分比)。经验观察表明,较高的自知得分与改进的事实性之间存在正相关关系,而较高的自不知得分与降低的事实性相关。有趣的是,即使模型的自判断得分(自知和自不知)没有显著变化,无依据声明的数量也可能增加,这可能是长文本生成的副产品。我们还推导出一个数学框架,将自知和自不知得分与事实性联系起来:$ extrm{Factuality}= rac{1- extrm{Self-Unknown}}{2- extrm{Self-Unknown}- extrm{Self-Known}}$,这与我们的经验观察结果一致。额外的检索增强生成(RAG)实验进一步突出了当前LLM在长文本生成中的局限性,并强调需要继续研究以提高长文本中的事实性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在长文本生成中事实性不足的问题。现有方法生成的长文本往往包含错误或无依据的信息,使得用户难以信任生成的内容。现有的评估方法也难以准确衡量模型的事实性水平,尤其是在长文本的上下文中。
核心思路:论文的核心思路是通过分析模型对自身生成内容的判断能力(自知和自不知),来理解和预测长文本生成的事实性。作者认为,模型是否知道自己生成的内容是正确的,直接影响了最终生成文本的事实性。通过量化模型的自知和自不知能力,可以更好地评估和改进长文本生成的事实性。
技术框架:论文的技术框架主要包括以下几个阶段:1) 使用不同的LLM生成长文本;2) 将生成的长文本分解为原子声明;3) 使用LLM判断每个原子声明是否正确;4) 计算自知(Self-Known)和自不知(Self-Unknown)得分;5) 分析自知和自不知得分与事实性之间的关系;6) 推导数学模型来描述这种关系;7) 进行RAG实验以进一步验证模型的局限性。
关键创新:论文的关键创新在于提出了自知(Self-Known)和自不知(Self-Unknown)的概念,并将其与长文本生成的事实性联系起来。通过量化模型的自判断能力,可以更深入地理解模型生成错误信息的原因。此外,论文还推导了一个数学模型,将自知和自不知得分与事实性联系起来,为评估和改进长文本生成的事实性提供了一个新的视角。
关键设计:论文的关键设计包括:1) 使用原子声明作为评估事实性的基本单位;2) 使用LLM自身来判断原子声明的正确性,避免引入外部知识库的偏差;3) 定义了自知和自不知得分的计算方法,并将其与事实性联系起来;4) 推导了一个数学模型,将自知和自不知得分与事实性联系起来,$ extrm{Factuality}= rac{1- extrm{Self-Unknown}}{2- extrm{Self-Unknown}- extrm{Self-Known}}$。
🖼️ 关键图片
📊 实验亮点
实验结果表明,较高的自知得分与改进的事实性之间存在正相关关系,而较高的自不知得分与降低的事实性相关。即使模型的自判断得分没有显著变化,无依据声明的数量也可能增加,这可能是长文本生成的副产品。论文提出的数学模型$ extrm{Factuality}= rac{1- extrm{Self-Unknown}}{2- extrm{Self-Unknown}- extrm{Self-Known}}$与经验观察结果一致。
🎯 应用场景
该研究成果可应用于各种需要生成长文本的场景,例如新闻报道、故事创作、技术文档生成等。通过提高长文本生成的事实性,可以增强用户对生成内容的信任度,减少错误信息的传播。未来的研究可以进一步探索如何利用自知和自不知信息来指导模型的训练,从而生成更准确、更可靠的长文本。
📄 摘要(原文)
Large language models (LLMs) have demonstrated strong capabilities in text understanding and generation. However, they often lack factuality, producing a mixture of true and false information, especially in long-form generation. In this work, we investigates the factuality of long-form text generation across various large language models (LLMs), including GPT-4, Gemini-1.5-Pro, Claude-3-Opus, Llama-3-70B, and Mistral. Our analysis reveals that factuality tend to decline in later sentences of the generated text, accompanied by a rise in the number of unsupported claims. Furthermore, we explore the effectiveness of different evaluation settings to assess whether LLMs can accurately judge the correctness of their own outputs: Self-Known (the percentage of supported atomic claims, decomposed from LLM outputs, that the corresponding LLMs judge as correct) and Self-Unknown (the percentage of unsupported atomic claims that the corresponding LLMs judge as incorrect). Empirically, we observe a positive correlation between higher Self-Known scores and improved factuality, whereas higher Self-Unknown scores are associated with reduced factuality. Interestingly, the number of unsupported claims can increase even without significant changes in a model's self-judgment scores (Self-Known and Self-Unknown), likely as a byproduct of long-form text generation. We also derive a mathematical framework linking Self-Known and Self-Unknown scores to factuality: $\textrm{Factuality}=\frac{1-\textrm{Self-Unknown}}{2-\textrm{Self-Unknown}-\textrm{Self-Known}}$, which aligns with our empirical observations. Additional Retrieval-Augmented Generation (RAG) experiments further highlight the limitations of current LLMs in long-form generation and underscore the need for continued research to improve factuality in long-form text.