"All that Glitters": Approaches to Evaluations with Unreliable Model and Human Annotations
作者: Michael Hardy
分类: cs.CL, cs.AI, stat.AP
发布日期: 2024-11-23
备注: 20 pages, 15 figures, 58 pages with references and appendices
💡 一句话要点
提出评估框架,解决低质量标注下模型与人工评估的可靠性问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型评估 人工标注 标签质量 偏差分析 人机协作 大型语言模型 Transformer GPT
📋 核心要点
- 现有模型评估方法在低质量人工标注数据下,难以准确评估模型性能,可能掩盖偏差和不公平性。
- 提出一种新的评估框架,从一致性、置信度、有效性、偏差、公平性和帮助性六个维度评估标签质量。
- 实验表明,标准指标在低质量标注下会产生误导,新评估方法能揭示模型和人工标注中的偏差。
📝 摘要(中文)
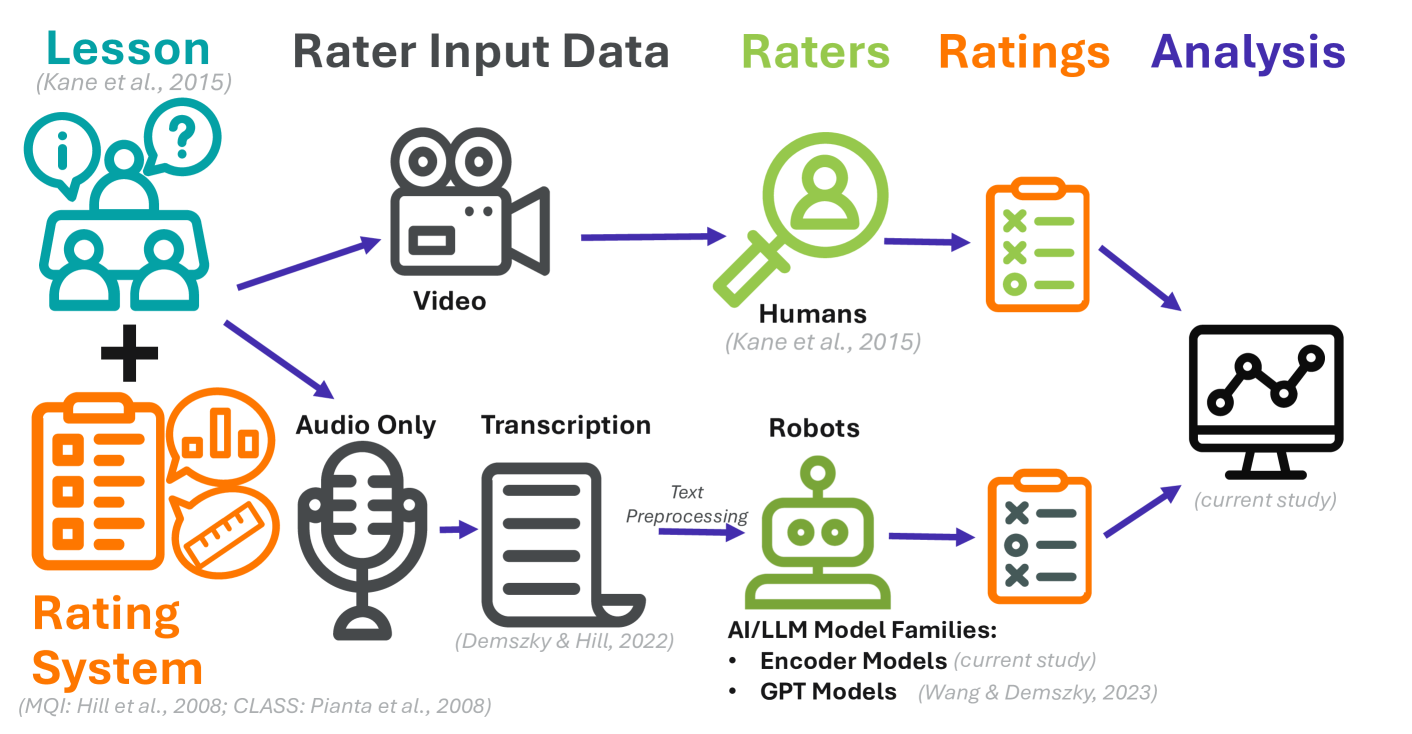
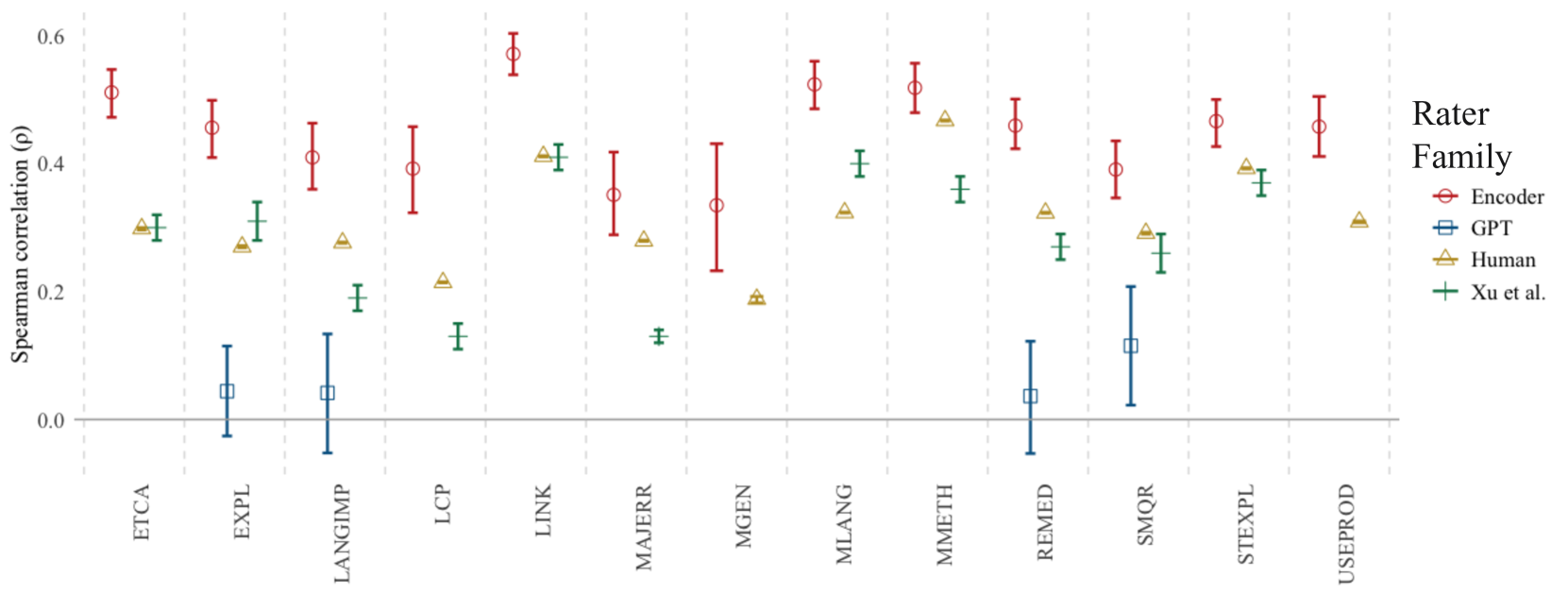
人工标注的“金标准”和“真值”标签存在误差。这种误差可能会逃脱常用的标签质量指标,或掩盖模型评估中关于准确性、偏差、公平性和有用性的问题。本研究展示了在专家人工标注可靠性极低的情况下,回答这些问题的方法。我们分析了人工标签、GPT模型评分和Transformer编码器模型标注,这些标注描述了课堂教学的质量,这是一项重要、昂贵且目前仅由人工完成的任务。我们使用新颖的方法评估了跨六个维度(一致性、置信度、有效性、偏差、公平性和帮助性)的标签质量,从而回答了是否可以使用两种大型语言模型(LLM)架构系列——编码器和GPT解码器来自动化此类任务的问题。首先,我们证明了在存在不良标签的情况下使用标准指标可能会掩盖标签和模型质量:编码器模型系列在所有课堂标注任务中都取得了最先进的,甚至是“超人”的结果。但是,在使用更严格的评估措施揭示模型和人类之间的虚假相关性和非随机种族偏见之后,并非所有这些积极的结果都保留了下来。然后,本研究扩展了这些方法,以估计如果在人机协作环境中使用模型,模型的使用将如何改变人工标签质量,发现GPT模型标签中捕获的方差会降低受这些模型影响的人的可靠性。我们确定了在当前数据的泛化范围内,某些LLM可以提高昂贵的课堂教学人工评分质量的领域。
🔬 方法详解
问题定义:论文旨在解决在人工标注质量不高的情况下,如何有效评估模型性能的问题。现有方法依赖于高质量的“金标准”标签,但在实际应用中,人工标注往往存在误差,导致模型评估结果失真,无法准确反映模型的真实能力,甚至可能掩盖模型中的偏差和不公平性。
核心思路:论文的核心思路是不再盲目信任人工标注,而是通过多维度分析标签质量,例如一致性、置信度、有效性、偏差、公平性和帮助性,来更全面地评估模型。同时,研究模型对人工标注的影响,分析模型是否会加剧人工标注的偏差。
技术框架:论文的整体框架包括以下几个阶段:1) 数据收集:收集课堂教学质量的人工标注数据,以及GPT模型和Transformer编码器模型的标注数据。2) 标签质量评估:使用提出的六个维度指标评估人工标注和模型标注的质量。3) 模型性能评估:在考虑标签质量的基础上,评估不同模型的性能,并分析模型中的偏差。4) 人机协作影响分析:研究模型对人工标注的影响,分析模型是否会改变人工标注的质量。
关键创新:论文最重要的创新点在于提出了一个多维度的标签质量评估框架,该框架不仅考虑了标签的准确性,还考虑了标签的一致性、置信度、有效性、偏差、公平性和帮助性。这种多维度的评估方法能够更全面地反映标签的质量,从而更准确地评估模型性能。此外,论文还研究了模型对人工标注的影响,这有助于理解人机协作中可能存在的风险。
关键设计:论文的关键设计包括:1) 六个维度指标的定义和计算方法。2) 使用GPT模型和Transformer编码器模型进行标注,并与人工标注进行比较。3) 设计实验来评估模型对人工标注的影响,例如,让人工标注者在参考模型标注结果后进行标注,然后分析人工标注的变化。
🖼️ 关键图片

📊 实验亮点
研究表明,在低质量标注下,标准评估指标会产生误导,例如,编码器模型在所有课堂标注任务中都取得了最先进的性能,但更严格的评估揭示了模型和人类之间的虚假相关性和非随机种族偏见。此外,研究还发现,GPT模型标签中捕获的方差会降低受这些模型影响的人的可靠性。
🎯 应用场景
该研究成果可应用于各种需要人工标注的领域,例如图像识别、自然语言处理、情感分析等。通过使用该研究提出的评估框架,可以更准确地评估模型性能,发现模型中的偏差,并提高人机协作的效率和质量。此外,该研究还可以帮助人们更好地理解人工标注的局限性,从而设计更有效的标注策略。
📄 摘要(原文)
"Gold" and "ground truth" human-mediated labels have error. The effects of this error can escape commonly reported metrics of label quality or obscure questions of accuracy, bias, fairness, and usefulness during model evaluation. This study demonstrates methods for answering such questions even in the context of very low reliabilities from expert humans. We analyze human labels, GPT model ratings, and transformer encoder model annotations describing the quality of classroom teaching, an important, expensive, and currently only human task. We answer the question of whether such a task can be automated using two Large Language Model (LLM) architecture families--encoders and GPT decoders, using novel approaches to evaluating label quality across six dimensions: Concordance, Confidence, Validity, Bias, Fairness, and Helpfulness. First, we demonstrate that using standard metrics in the presence of poor labels can mask both label and model quality: the encoder family of models achieve state-of-the-art, even "super-human", results across all classroom annotation tasks. But not all these positive results remain after using more rigorous evaluation measures which reveal spurious correlations and nonrandom racial biases across models and humans. This study then expands these methods to estimate how model use would change to human label quality if models were used in a human-in-the-loop context, finding that the variance captured in GPT model labels would worsen reliabilities for humans influenced by these models. We identify areas where some LLMs, within the generalizability of the current data, could improve the quality of expensive human ratings of classroom instruction.