A Survey on LLM-as-a-Judge
作者: Jiawei Gu, Xuhui Jiang, Zhichao Shi, Hexiang Tan, Xuehao Zhai, Chengjin Xu, Wei Li, Yinghan Shen, Shengjie Ma, Honghao Liu, Saizhuo Wang, Kun Zhang, Yuanzhuo Wang, Wen Gao, Lionel Ni, Jian Guo
分类: cs.CL, cs.AI
发布日期: 2024-11-23 (更新: 2025-10-19)
备注: Project Page: https://awesome-llm-as-a-judge.github.io/
💡 一句话要点
综述LLM-as-a-Judge:探索构建可靠的大语言模型评判系统的策略与方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 LLM-as-a-Judge 评估系统 可靠性 偏差缓解 一致性 基准测试 提示词工程
📋 核心要点
- 传统评估方法存在主观性强、成本高、难以规模化等问题,无法满足日益增长的评估需求。
- 论文核心思想是探索如何利用LLM构建可靠的评判系统,替代传统专家评估,实现更高效、一致的评估。
- 论文提出了提高LLM评判系统可靠性的策略,包括提升一致性、缓解偏差,并设计了新的基准进行评估。
📝 摘要(中文)
准确和一致的评估对于众多领域的决策至关重要,但由于其固有的主观性、可变性和规模性,评估仍然是一项具有挑战性的任务。大型语言模型(LLM)在各个领域都取得了显著的成功,从而催生了“LLM-as-a-Judge”的概念,即利用LLM作为复杂任务的评估者。凭借处理多样化数据类型以及提供可扩展、经济高效且一致的评估的能力,LLM为传统的专家驱动评估提供了一种引人注目的替代方案。然而,确保LLM-as-a-Judge系统的可靠性仍然是一个重大挑战,需要仔细的设计和标准化。本文对LLM-as-a-Judge进行了全面的综述,旨在解决核心问题:如何构建可靠的LLM-as-a-Judge系统?我们探讨了提高可靠性的策略,包括提高一致性、减轻偏差以及适应多样化的评估场景。此外,我们提出了一套用于评估LLM-as-a-Judge系统可靠性的方法,并为此设计了一个新的基准。为了推进LLM-as-a-Judge系统的开发和实际部署,我们还讨论了实际应用、挑战和未来方向。本综述为这个快速发展的领域的研究人员和从业人员提供了一个基础参考。
🔬 方法详解
问题定义:论文旨在解决传统评估方法中存在的主观性、可变性和规模限制问题。现有方法依赖于专家评估,成本高昂且难以保证一致性。此外,传统评估方法难以适应快速变化和多样化的评估需求。
核心思路:论文的核心思路是利用大型语言模型(LLM)作为评判者,即“LLM-as-a-Judge”,以实现更高效、可扩展和一致的评估。LLM具备处理多种数据类型和进行复杂推理的能力,使其能够胜任评估任务。通过精心设计提示词和评估流程,可以引导LLM进行客观、公正的评估。
技术框架:论文主要围绕如何构建可靠的LLM-as-a-Judge系统展开,框架包括以下几个关键部分:1) 提高一致性的策略:例如,使用更明确的评估标准和提示词,以及采用集成方法来减少随机性。2) 缓解偏差的策略:例如,使用多样化的训练数据,以及采用对抗训练来识别和消除偏差。3) 适应多样化评估场景的策略:例如,使用领域特定的微调,以及采用元学习来快速适应新的评估任务。4) 评估LLM-as-a-Judge系统可靠性的方法:论文提出了新的基准,用于评估LLM评判系统在不同方面的性能。
关键创新:论文的主要创新在于对LLM-as-a-Judge进行了全面的综述,并提出了构建可靠LLM评判系统的策略和方法。与现有方法相比,论文更加关注LLM评判系统的可靠性,并提出了相应的评估方法。此外,论文还探讨了LLM评判系统在实际应用中的挑战和未来方向。
关键设计:论文中涉及的关键设计包括:1) 提示词工程:如何设计有效的提示词,引导LLM进行准确的评估。2) 数据增强:如何使用多样化的数据来训练LLM,减少偏差。3) 模型微调:如何使用领域特定的数据来微调LLM,提高评估性能。4) 评估指标:如何设计合适的评估指标,衡量LLM评判系统的可靠性。
🖼️ 关键图片
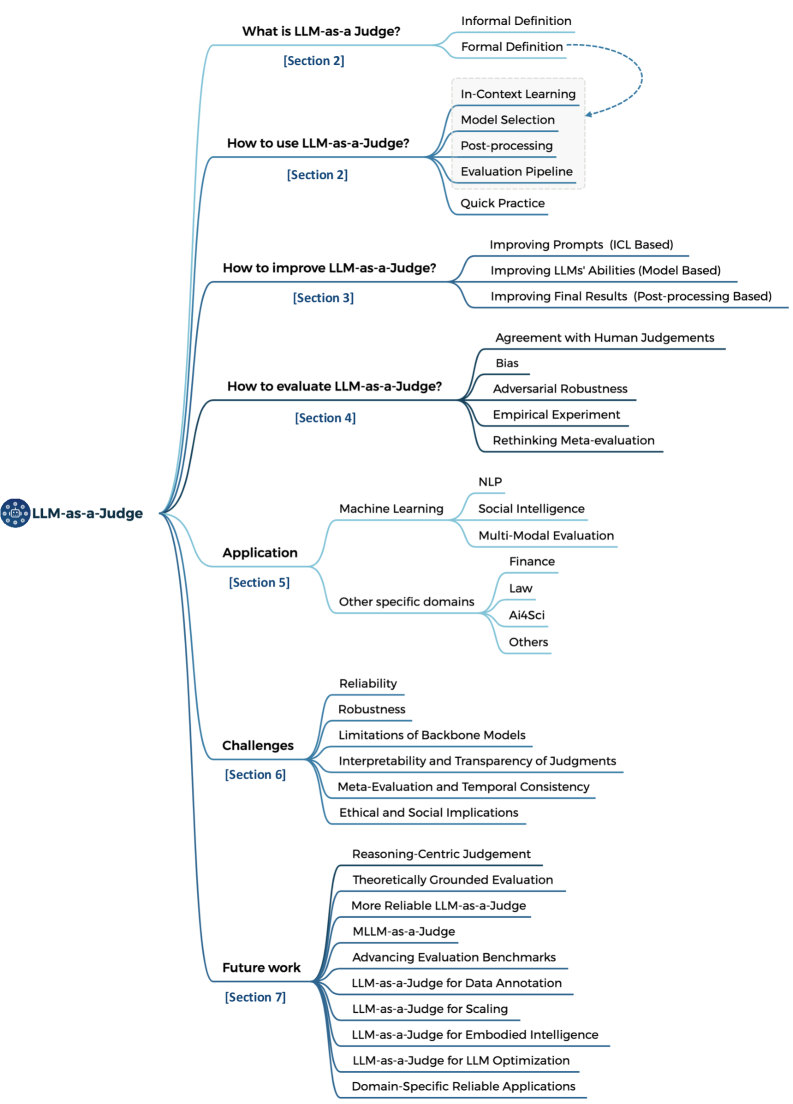
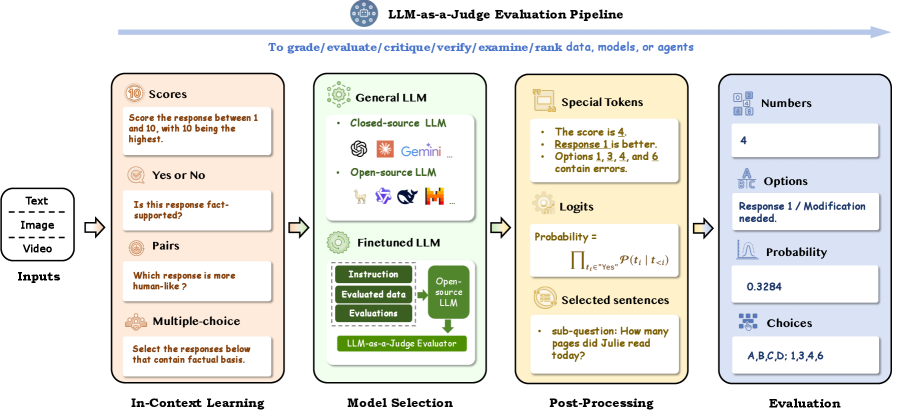
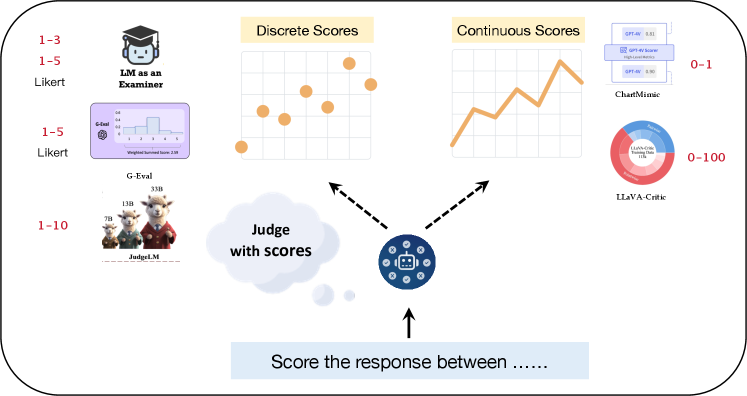
📊 实验亮点
该论文是一篇综述性文章,主要贡献在于对LLM-as-a-Judge领域进行了全面的梳理和总结,并提出了构建可靠LLM评判系统的策略和方法。论文还设计了一个新的基准,用于评估LLM评判系统的可靠性。由于是综述,没有具体的性能数据和提升幅度,但为该领域的研究人员提供了重要的参考。
🎯 应用场景
LLM-as-a-Judge具有广泛的应用前景,例如自动代码评审、论文评审、产品质量评估、内容审核等。它可以降低评估成本,提高评估效率,并提供更一致的评估结果。未来,LLM-as-a-Judge有望成为各种评估任务的重要工具,推动相关领域的发展。
📄 摘要(原文)
Accurate and consistent evaluation is crucial for decision-making across numerous fields, yet it remains a challenging task due to inherent subjectivity, variability, and scale. Large Language Models (LLMs) have achieved remarkable success across diverse domains, leading to the emergence of "LLM-as-a-Judge," where LLMs are employed as evaluators for complex tasks. With their ability to process diverse data types and provide scalable, cost-effective, and consistent assessments, LLMs present a compelling alternative to traditional expert-driven evaluations. However, ensuring the reliability of LLM-as-a-Judge systems remains a significant challenge that requires careful design and standardization. This paper provides a comprehensive survey of LLM-as-a-Judge, addressing the core question: How can reliable LLM-as-a-Judge systems be built? We explore strategies to enhance reliability, including improving consistency, mitigating biases, and adapting to diverse assessment scenarios. Additionally, we propose methodologies for evaluating the reliability of LLM-as-a-Judge systems, supported by a novel benchmark designed for this purpose. To advance the development and real-world deployment of LLM-as-a-Judge systems, we also discussed practical applications, challenges, and future directions. This survey serves as a foundational reference for researchers and practitioners in this rapidly evolving field.