XGrammar: Flexible and Efficient Structured Generation Engine for Large Language Models
作者: Yixin Dong, Charlie F. Ruan, Yaxing Cai, Ruihang Lai, Ziyi Xu, Yilong Zhao, Tianqi Chen
分类: cs.CL, cs.AI, cs.PL
发布日期: 2024-11-22 (更新: 2025-05-12)
备注: MLSys '25
💡 一句话要点
XGrammar:为大语言模型提供灵活高效的结构化生成引擎
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 结构化生成 大语言模型 上下文无关文法 LLM代理 推理加速
📋 核心要点
- 现有方法在LLM结构化生成中,使用上下文无关文法存在运行时开销大的问题,影响效率。
- XGrammar通过划分上下文无关和相关token,并进行预检查和运行时解释,加速文法执行。
- 实验表明,XGrammar相比现有方案可提速高达100倍,并能实现近零开销的端到端结构化生成。
📝 摘要(中文)
大型语言模型(LLM)代理的应用日益复杂和多样化,对可解析为代码、结构化函数调用和具身代理命令的结构化输出的需求很高。这些发展对LLM推理中的结构化生成提出了重大需求。上下文无关文法是一种通过约束解码实现结构化生成的灵活方法。然而,执行上下文无关文法需要在运行时遍历词汇表中所有token的多个堆栈状态,这为结构化生成带来了不可忽略的开销。本文提出了XGrammar,一种为大型语言模型提供灵活高效的结构化生成引擎。XGrammar通过将词汇表划分为可以预先检查的上下文无关token和需要在运行时解释的上下文相关token来加速上下文无关文法的执行。我们进一步构建转换来扩展文法上下文并减少上下文无关token的数量。此外,我们构建了一个高效的持久堆栈来加速上下文相关token的检查。最后,我们将文法引擎与LLM推理引擎共同设计,以将文法计算与GPU执行重叠。评估结果表明,XGrammar可以实现比现有解决方案高达100倍的加速。与LLM推理引擎结合使用,它可以在端到端低LLM服务中生成近乎零开销的结构化生成。
🔬 方法详解
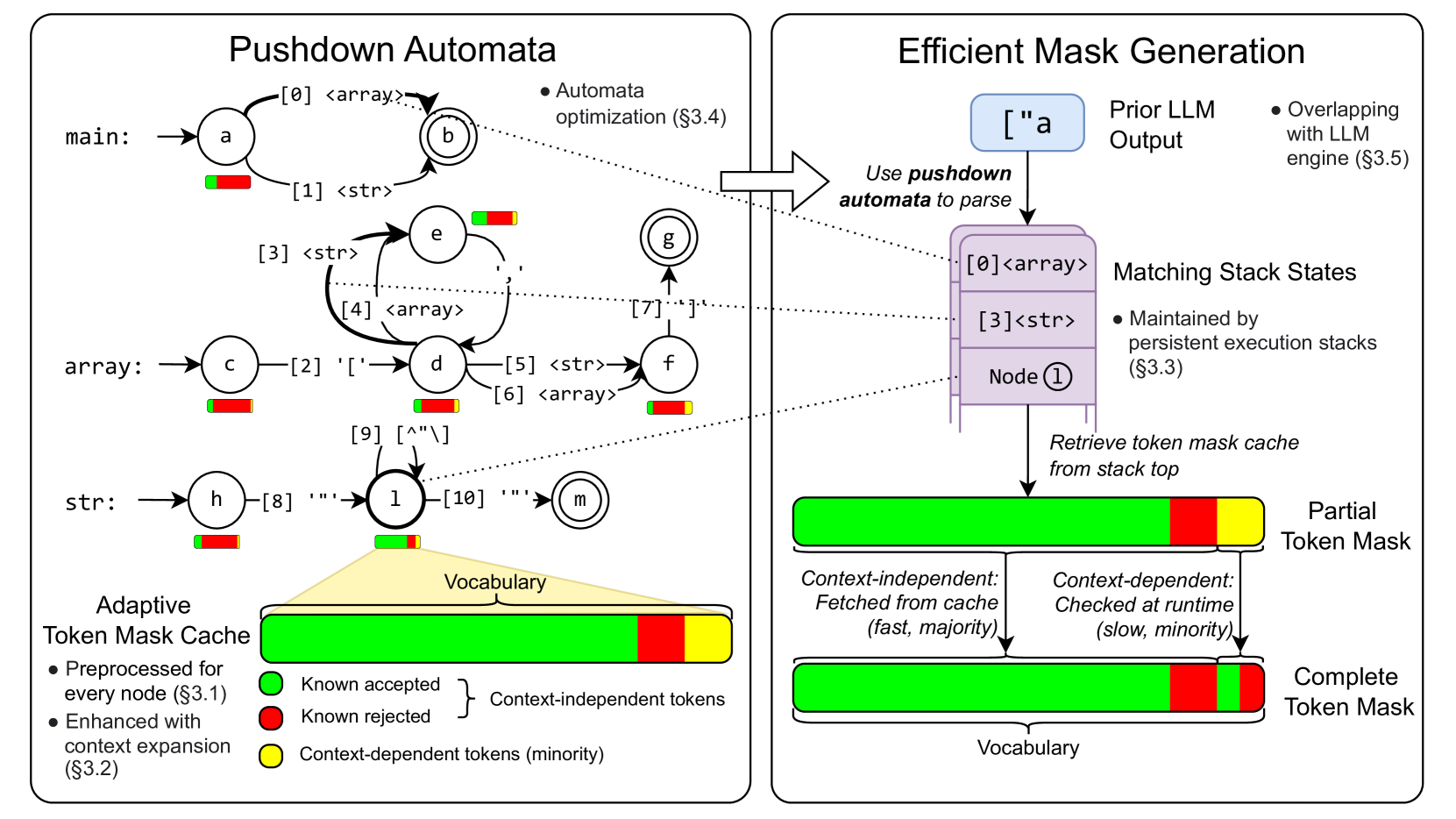
问题定义:论文旨在解决大型语言模型(LLM)在结构化生成任务中效率低下的问题。现有的基于上下文无关文法的方法,在生成过程中需要对词汇表中的每个token进行多次堆栈状态检查,导致显著的运行时开销,限制了LLM在需要快速响应的复杂应用中的应用。
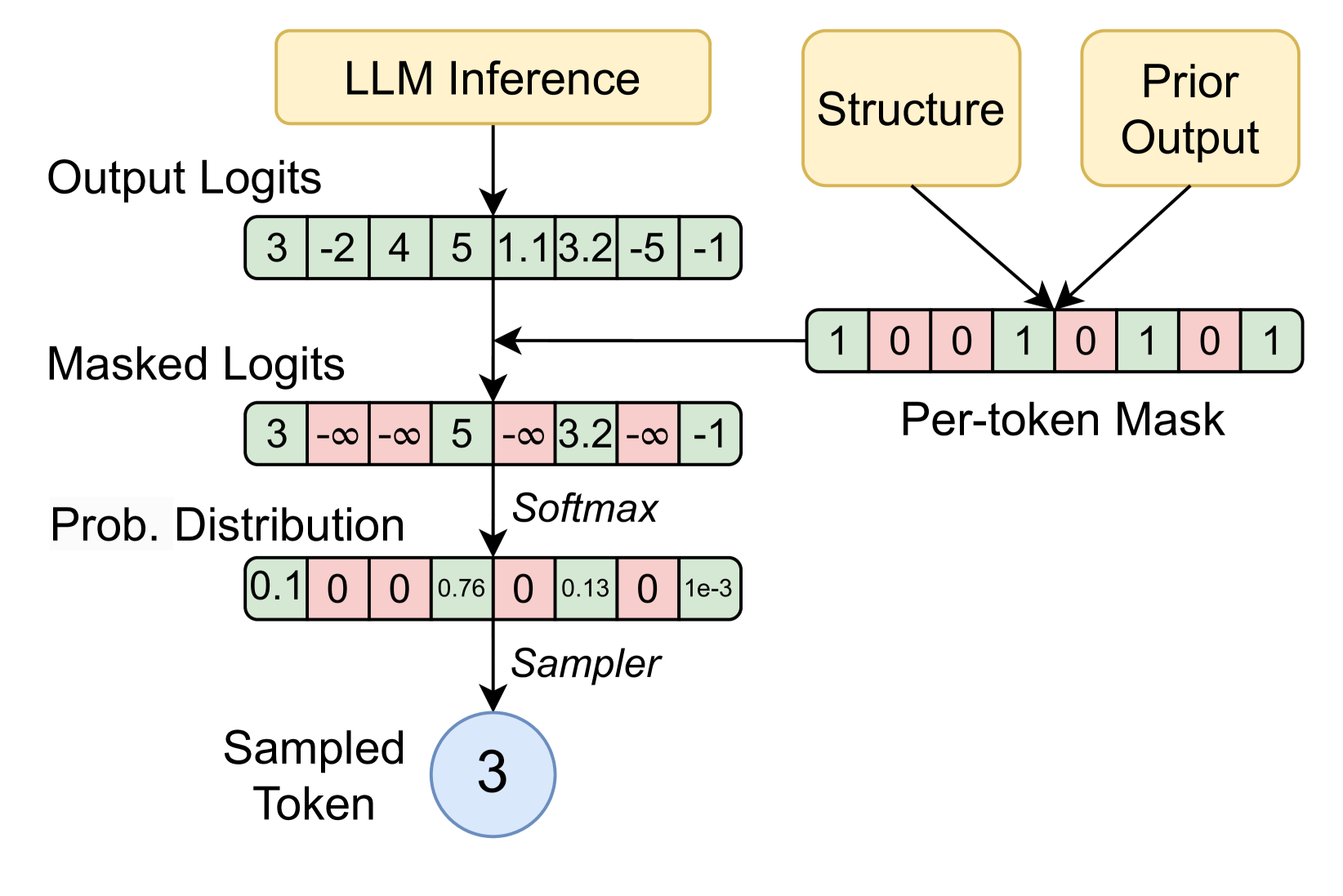
核心思路:XGrammar的核心思路是将词汇表中的token分为两类:上下文无关token和上下文相关token。上下文无关token可以在运行时预先检查,而上下文相关token则需要在运行时进行解释。通过这种划分,可以减少运行时需要进行复杂文法检查的token数量,从而加速整个生成过程。此外,论文还通过文法转换来扩展上下文,进一步减少上下文无关token的数量。
技术框架:XGrammar的整体框架包括以下几个主要模块:1) 词汇表划分模块:将词汇表划分为上下文无关token和上下文相关token。2) 文法转换模块:通过转换扩展文法上下文,减少上下文无关token的数量。3) 持久堆栈模块:构建高效的持久堆栈,加速上下文相关token的检查。4) LLM推理引擎协同设计:将文法引擎与LLM推理引擎共同设计,实现文法计算与GPU执行的重叠。
关键创新:XGrammar的关键创新在于其对词汇表的划分和预检查机制。通过将token分为上下文无关和上下文相关两类,并对上下文无关token进行预检查,显著减少了运行时需要进行复杂文法检查的token数量。这种方法与现有方法需要对所有token进行运行时检查形成了本质区别。
关键设计:论文中关键的设计包括:1) 词汇表划分策略:如何有效地将词汇表划分为上下文无关和上下文相关token。2) 文法转换规则:如何设计文法转换规则,以扩展上下文并减少上下文无关token的数量。3) 持久堆栈的实现:如何构建高效的持久堆栈,以加速上下文相关token的检查。4) 与LLM推理引擎的协同策略:如何将文法引擎与LLM推理引擎进行协同设计,以实现文法计算与GPU执行的重叠。
🖼️ 关键图片

📊 实验亮点
实验结果表明,XGrammar相比现有解决方案实现了高达100倍的加速。与LLM推理引擎结合使用时,XGrammar能够在端到端LLM服务中实现近乎零开销的结构化生成。这些结果验证了XGrammar在提升LLM结构化生成效率方面的显著优势。
🎯 应用场景
XGrammar可广泛应用于需要结构化输出的LLM代理应用中,例如代码生成、结构化函数调用和具身代理命令等。该技术能够显著提升LLM在这些应用中的响应速度和效率,使其能够更好地服务于复杂的任务需求。未来,XGrammar有望推动LLM在自动化、智能助手等领域的更广泛应用。
📄 摘要(原文)
The applications of LLM Agents are becoming increasingly complex and diverse, leading to a high demand for structured outputs that can be parsed into code, structured function calls, and embodied agent commands. These developments bring significant demands for structured generation in LLM inference. Context-free grammar is a flexible approach to enable structured generation via constrained decoding. However, executing context-free grammar requires going through several stack states over all tokens in vocabulary during runtime, bringing non-negligible overhead for structured generation. In this paper, we propose XGrammar, a flexible and efficient structure generation engine for large language models. XGrammar accelerates context-free grammar execution by dividing the vocabulary into context-independent tokens that can be prechecked and context-dependent tokens that need to be interpreted during runtime. We further build transformations to expand the grammar context and reduce the number of context-independent tokens. Additionally, we build an efficient persistent stack to accelerate the context-dependent token checks. Finally, we co-design the grammar engine with LLM inference engine to overlap grammar computation with GPU executions. Evaluation results show that XGrammar can achieve up to 100x speedup over existing solutions. Combined with an LLM inference engine, it can generate near-zero overhead structure generation in end-to-end low-LLM serving.