IRLab@iKAT24: Learned Sparse Retrieval with Multi-aspect LLM Query Generation for Conversational Search
作者: Simon Lupart, Zahra Abbasiantaeb, Mohammad Aliannejadi
分类: cs.IR, cs.CL
发布日期: 2024-11-22
💡 一句话要点
针对对话式搜索,提出基于多方面LLM查询生成和稀疏检索的学习方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话式搜索 查询重写 大型语言模型 稀疏检索 个性化推荐 多方面查询生成 交叉编码器
📋 核心要点
- 现有对话式搜索方法难以有效利用个性化用户知识,限制了助手在特定场景下的表现。
- 论文提出利用大型语言模型进行多方面查询生成,并结合学习到的稀疏检索,以更好地理解用户意图。
- 实验结果表明,该方法在对话式搜索任务中能够有效提升性能,并超越人工重写的效果。
📝 摘要(中文)
本文针对交互式知识助手评测(iKAT)2024,旨在提升对话助手的性能,使其能够根据个性化的用户知识调整交互和响应。该评测包含个人文本知识库(PTKB)以及对话式AI任务,如段落排序和响应生成。考虑到查询重写是解决对话上下文的有效方法,我们探索了大型语言模型(LLM)作为查询重写器。具体而言,我们提交的运行探索了使用MQ4CS框架的多方面查询生成,并通过SPLADE架构增强了学习到的稀疏检索,并结合了强大的交叉编码器模型。我们还提出了一种替代先前的交错策略的方法,在重排序阶段聚合多个方面。我们的研究结果表明,多方面查询生成在与先进的检索和重排序模型集成时,能够有效提升性能。我们的结果也为对话式搜索中更好的个性化铺平了道路,依靠LLM将个性化融入查询重写中,并优于人工重写性能。
🔬 方法详解
问题定义:论文旨在解决对话式搜索中,如何更好地利用用户的个性化知识库(PTKB)来提升检索效果的问题。现有方法在处理对话上下文和用户个性化信息方面存在不足,导致检索结果不够准确和相关。人工重写查询虽然有效,但成本高昂且难以规模化应用。
核心思路:论文的核心思路是利用大型语言模型(LLM)进行查询重写,生成包含多个方面的查询,从而更全面地表达用户的搜索意图。同时,结合学习到的稀疏检索(Learned Sparse Retrieval)方法,提高检索效率和准确性。通过将LLM的生成能力和稀疏检索的效率相结合,实现更有效的个性化对话式搜索。
技术框架:整体框架包含以下几个主要阶段:1) 多方面查询生成:使用LLM(基于MQ4CS框架)根据对话历史和用户知识库生成多个不同方面的查询。2) 稀疏检索:使用SPLADE架构进行学习到的稀疏检索,快速筛选出候选文档。3) 重排序:使用交叉编码器模型对候选文档进行重排序,选择最相关的文档。4) 结果聚合:提出一种新的聚合策略,在重排序阶段将多个方面的查询结果进行整合,以获得更准确的排序结果。
关键创新:论文的关键创新在于将多方面查询生成与学习到的稀疏检索相结合,并提出了一种新的结果聚合策略。多方面查询生成能够更全面地捕捉用户意图,而稀疏检索能够提高检索效率。此外,提出的聚合策略避免了先前方法的交错策略,提高了重排序的准确性。
关键设计:在多方面查询生成方面,使用了MQ4CS框架,并针对对话式搜索任务进行了优化。在稀疏检索方面,采用了SPLADE架构,通过学习文档和查询的稀疏表示,提高了检索效率。在重排序方面,使用了强大的交叉编码器模型,对候选文档进行精细的排序。关键参数设置和损失函数等技术细节在论文中未详细说明,属于未知信息。
🖼️ 关键图片

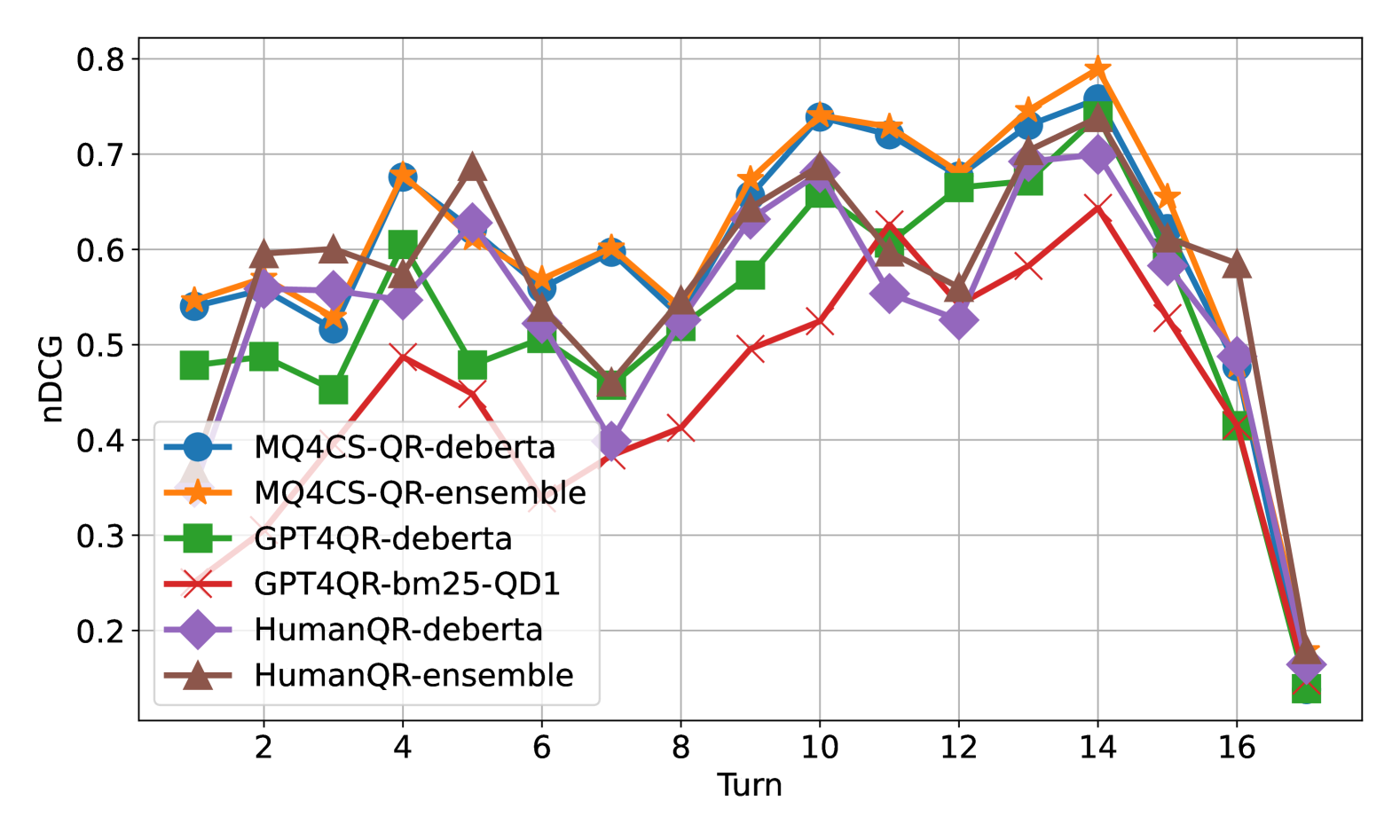

📊 实验亮点
实验结果表明,该方法在iKAT24评测中取得了显著的性能提升。通过将多方面查询生成与学习到的稀疏检索相结合,该方法优于人工重写查询的性能,表明LLM在个性化查询重写方面具有巨大潜力。具体的性能数据和对比基线在摘要中未给出,属于未知信息。
🎯 应用场景
该研究成果可应用于各种对话式搜索场景,例如智能客服、虚拟助手、个性化推荐系统等。通过更好地理解用户意图和利用个性化知识,可以提供更准确、更相关的搜索结果,提升用户体验。未来,该方法有望应用于更复杂的对话场景,例如多轮对话、知识图谱推理等。
📄 摘要(原文)
The Interactive Knowledge Assistant Track (iKAT) 2024 focuses on advancing conversational assistants, able to adapt their interaction and responses from personalized user knowledge. The track incorporates a Personal Textual Knowledge Base (PTKB) alongside Conversational AI tasks, such as passage ranking and response generation. Query Rewrite being an effective approach for resolving conversational context, we explore Large Language Models (LLMs), as query rewriters. Specifically, our submitted runs explore multi-aspect query generation using the MQ4CS framework, which we further enhance with Learned Sparse Retrieval via the SPLADE architecture, coupled with robust cross-encoder models. We also propose an alternative to the previous interleaving strategy, aggregating multiple aspects during the reranking phase. Our findings indicate that multi-aspect query generation is effective in enhancing performance when integrated with advanced retrieval and reranking models. Our results also lead the way for better personalization in Conversational Search, relying on LLMs to integrate personalization within query rewrite, and outperforming human rewrite performance.