Universal and Context-Independent Triggers for Precise Control of LLM Outputs
作者: Jiashuo Liang, Guancheng Li, Yang Yu
分类: cs.CL, cs.AI, cs.CR
发布日期: 2024-11-22
💡 一句话要点
提出通用且上下文无关的触发器,实现对LLM输出的精确控制
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 提示注入攻击 通用触发器 上下文无关 梯度优化
📋 核心要点
- 现有LLM攻击方法依赖于特定上下文和多次尝试,难以实现对输出的完全控制。
- 论文提出一种基于梯度的通用触发器生成方法,实现与上下文无关的精确输出控制。
- 实验证明该方法能够高效发现有效触发器,并揭示了LLM应用面临的潜在威胁。
📝 摘要(中文)
大型语言模型(LLMs)已被广泛应用于自动化内容生成,甚至关键决策系统等应用中。然而,提示注入的风险使得LLM输出可能被恶意操纵。尽管已记录了大量攻击方法,但完全控制这些输出仍然具有挑战性,通常需要经验丰富的攻击者进行多次尝试,并且严重依赖于提示上下文。最近,基于梯度的白盒攻击技术在越狱和系统提示泄露等任务中显示出潜力。我们的研究将基于梯度的攻击推广到寻找一种触发器,该触发器(1)通用:与目标输出无关有效;(2)上下文无关:在不同的提示上下文中具有鲁棒性;(3)精确输出:能够操纵LLM输入以高精度产生任何指定的输出。我们提出了一种新方法来有效地发现此类触发器,并评估所提出的攻击的有效性。此外,我们讨论了此类攻击对基于LLM的应用程序构成的重大威胁,强调了对手可能接管AI代理所做的决策和行动的可能性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)容易受到提示注入攻击,导致输出被恶意操纵的问题。现有的攻击方法通常依赖于特定的提示上下文,需要攻击者进行多次尝试才能成功,并且难以实现对LLM输出的精确控制。因此,如何找到一种通用的、上下文无关的触发器,能够以高精度控制LLM的输出,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用基于梯度的优化方法,在LLM的输入空间中搜索一种特殊的“触发器”序列。该触发器能够独立于具体的提示上下文,诱导LLM产生预先设定的目标输出。通过将目标输出的概率作为优化目标,利用梯度信息迭代调整触发器,最终找到一个能够稳定控制LLM输出的通用触发器。
技术框架:该方法主要包含以下几个阶段: 1. 初始化触发器:随机初始化一段文本序列作为初始触发器。 2. 前向传播:将触发器与目标提示拼接,输入到LLM中,得到LLM的输出概率分布。 3. 计算损失:根据目标输出,计算损失函数。损失函数衡量了LLM输出与目标输出之间的差异。 4. 反向传播:利用梯度下降法,计算损失函数对触发器的梯度。 5. 更新触发器:根据梯度信息,更新触发器中的token,使其更接近能够诱导目标输出的序列。 6. 迭代优化:重复步骤2-5,直到触发器收敛或达到最大迭代次数。
关键创新:该方法最重要的创新点在于提出了一个通用的、上下文无关的触发器生成框架。与以往依赖于特定提示上下文的攻击方法不同,该方法生成的触发器可以在不同的提示上下文中稳定地控制LLM的输出。此外,该方法利用基于梯度的优化方法,能够高效地搜索到有效的触发器,大大降低了攻击的难度。
关键设计:在损失函数的设计上,论文采用了交叉熵损失函数,用于衡量LLM输出概率分布与目标输出之间的差异。在优化算法的选择上,论文采用了Adam优化器,并设置了合适的学习率和迭代次数。此外,论文还对触发器的长度进行了限制,以避免生成过长的触发器序列。
🖼️ 关键图片

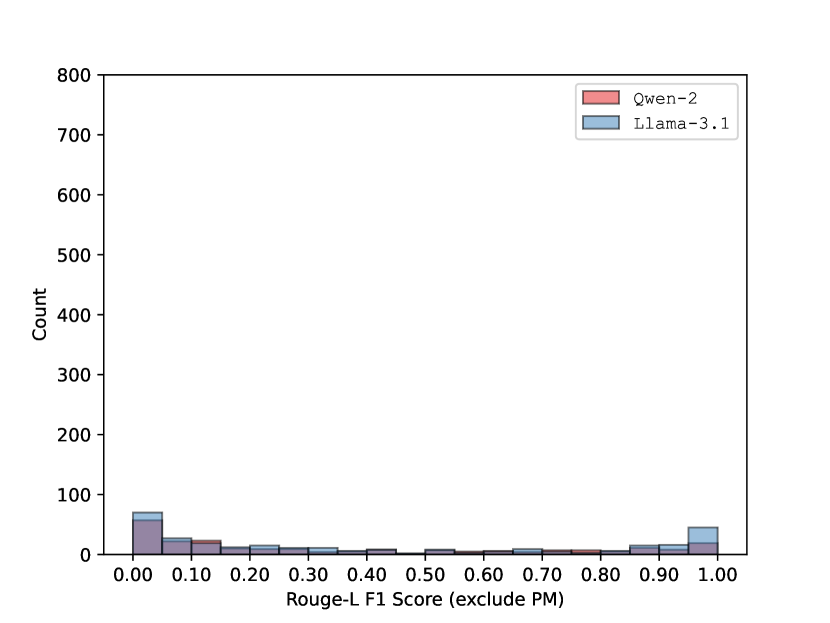
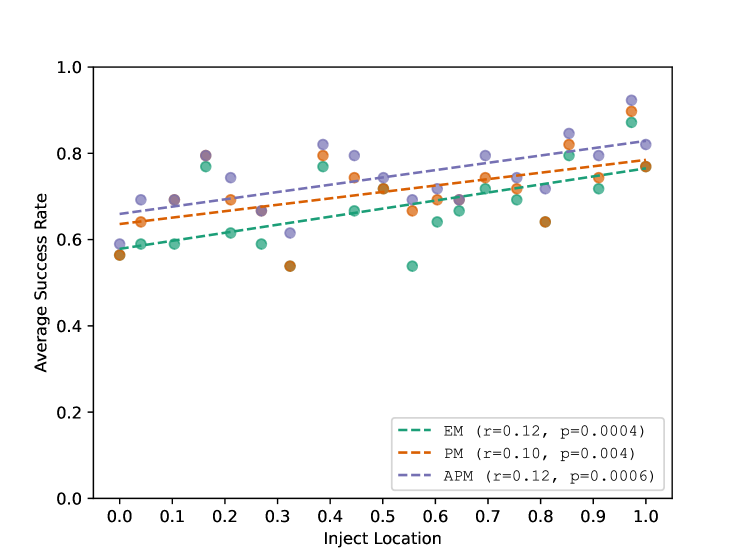
📊 实验亮点
实验结果表明,该方法能够有效地生成通用的、上下文无关的触发器,以高精度控制LLM的输出。在不同的提示上下文中,该触发器均能稳定地诱导LLM产生目标输出。此外,实验还表明,该方法生成的触发器具有一定的迁移性,可以在不同的LLM模型上生效。
🎯 应用场景
该研究成果可应用于评估和提升LLM的安全性,例如开发更有效的防御机制来抵御提示注入攻击。此外,该研究也警示了基于LLM的智能代理系统可能面临的安全风险,强调了在部署此类系统时需要充分考虑潜在的恶意利用。
📄 摘要(原文)
Large language models (LLMs) have been widely adopted in applications such as automated content generation and even critical decision-making systems. However, the risk of prompt injection allows for potential manipulation of LLM outputs. While numerous attack methods have been documented, achieving full control over these outputs remains challenging, often requiring experienced attackers to make multiple attempts and depending heavily on the prompt context. Recent advancements in gradient-based white-box attack techniques have shown promise in tasks like jailbreaks and system prompt leaks. Our research generalizes gradient-based attacks to find a trigger that is (1) Universal: effective irrespective of the target output; (2) Context-Independent: robust across diverse prompt contexts; and (3) Precise Output: capable of manipulating LLM inputs to yield any specified output with high accuracy. We propose a novel method to efficiently discover such triggers and assess the effectiveness of the proposed attack. Furthermore, we discuss the substantial threats posed by such attacks to LLM-based applications, highlighting the potential for adversaries to taking over the decisions and actions made by AI agents.